
光场深度估计
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
深度估计是场景三维重建过程中要解决的一个关键问题,传统影像中,常见的深度估计方法主要分为以下单目深度估计、双目深度估计以及多目深度估计。单目深度估计主要是借助图像的纹理、梯度、散焦/模糊线索等;双目或多目深度估计(也可以说是立体视觉)是基于三角测量原理,从多张不同视角拍摄的同一场景的二维图像中提取深度信息。光场深度估计的方法是传统图像深度估计方法的继承与发展。
光场深度估计算法分类
我们知道,光场图像中包含场景的多个视角信息,使得光场相机进行深度估计变得可能,同时相较于传统图像深度估计,不易受运动等带来的影响。但是由于多视角信息之间的基线较短,可能会导致误匹配的问题,目前国内外针对光场进行深度估计的方法大致分为以下几类:
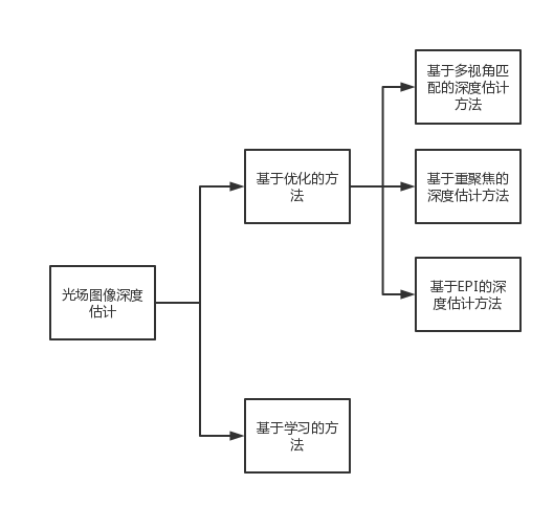
图1 深度估计方法分类图
基于优化的方法
基于多视角匹配的深度估计方法
基于多视角匹配的方法是由传统二维图像的立体匹配演变而来,具体的理论在这里就不赘述了。传统立体匹配方法需要使用两台或多台相机对一个场景进行拍摄,在这个过程中需要克服相机抖动、人为操作的影响;而光场相机一次拍照等效于多个相机对同一场景进行拍摄,并且几乎不受相机抖动影响,在深度估计方面有着很大的潜力。同样的光场相机目前也存在一些需要克服的问题,我们在前边提到,光场相机由于基线较短,容易造成误匹配的问题,而多视角匹配方法来求取深度,最关键的一点就是要得到准确的匹配对,为了解决误匹配的问题,学者们也提到了许多方法来尽可能提升准确度,下表是列举出来的一些具有代表性的方法:
论文名称 | Accurate depth map estimation from a lenslet light field camera |
论文作者 | Jeon, Hae Gon, et al. |
DOI | 10.1109/CVPR.2015.7298762 |
论文名称 | Line Assisted Light Field Triangulation and Stereo Matching |
论文作者 | Yu, Zhan, et al. |
DOI | 10.1109/ICCV.2013.347 |
论文名称 | Shape from Light Field Meets Robust PCA |
论文作者 | Heber, Stefan, and T. Pock |
DOI | 10.1007/978-3-319-10599-4_48 |
论文名称 | Variational Shape from Light Field |
论文作者 | Heber, Stefan, R. Ranftl, and T. Pock |
DOI | 10.1007/978-3-642-40395-8_6 |
论文名称 | Light Field Stereo Matching Using Bilateral Statistics of Surface Cameras |
论文作者 | Chen, Can, et al. |
DOI | 10.1109/CVPR.2014.197 |
其中,Yu等人研究了基线空间中的几何关系,改善了光场的立体匹配效果[1];但是该方法只使用了传统的匹配方式,导致视差较小的场景中难以很好的估计深度。之后为了克服小基线的误匹配问题,Jeon等人基于多视角提出了一种成本量匹配算法,用于评估不同视差值标签之间的匹配成本[2]。Heber等人提出了一种新的PCA匹配条件用于视角弯曲的创建,以解决光场多视角窄基线带来的像素级细微差异不敏感的问题[3]。
基于EPI的光场深度估计方法
不同于多视角立体匹配的方式,基于EPI的方式是通过分析光场数据结构的从而进行深度估计的方式。
如下图所示:
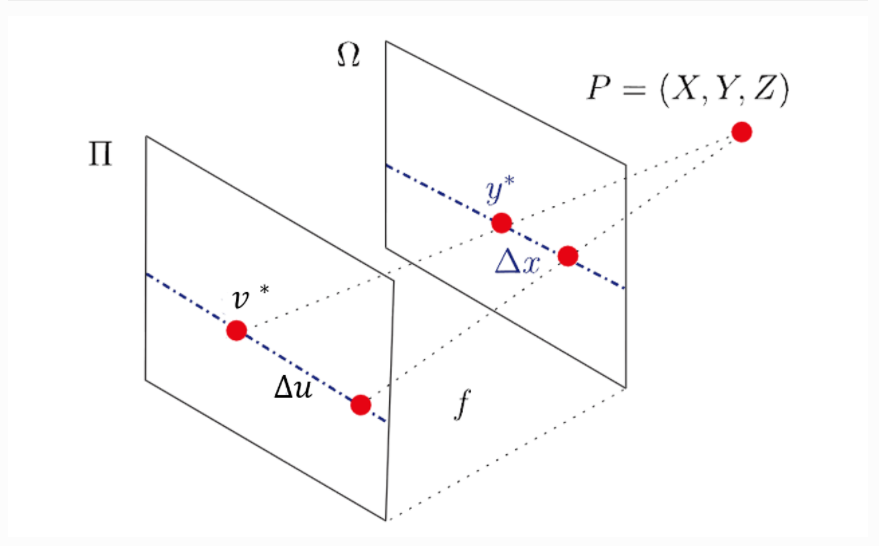
图2 空间点投影示意图
上图中P点为空间点,Ⅱ为相机平面,Ω为像平面。如下图所示,通过固定光场影像的一个角度方向和空间方向,我们可以获取其EPI图像,下图下侧和右侧为EPI示意图:

图3 EPI示意图
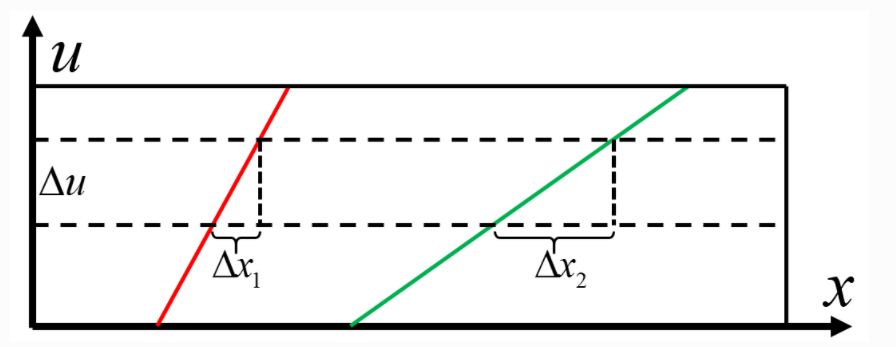
图4 EPI斜率示意图
进一步的,我们得到了EPI图像之后,可以通过检测EPI图像中斜线的斜率来进行视差d估计,如下式:
d = △u/△x
根据对极几何的原理,可以推导出深度Z与视差d之间的关系,如下式:
Z = -f/d
上式f为焦距;另外,结合公式与上图可知,不同深度的目标点,对应的EPI图像中的斜率不同。
下表是列出的比较有代表性的基于EPI的光场深度估计方法:
论文名称 | Robust depth estimation for light field via spinning parallelogram operator |
论文作者 | Zhang S, Sheng H, et al. |
DOI | 10.1016/j.cviu.2015.12.007 |
论文名称 | Variational light field analysis for disparity estimation and supersolution |
论文作者 | Wanner S, Goldluecke B. |
DOI | 10.1109/TPAMI.2013.147 |
论文名称 | Continuous depth map reconstruction from light fields |
论文作者 | Li J, Lu M, Li Z N |
DOI | 10.1109/TIP.2015.2440760 |
论文名称 | A Bidrectional Light Field Hologram Transform |
论文作者 | Ziegler R, Bucheli S, et al. |
DOI | 10.1111/j.1467-8659.2007.01066.x |
论文名称 | Epipolar-plane image analysis:An approach to determining structure from motion |
论文作者 | Bolles R C, Baker H H, Marimont D H. |
DOI | 10.1007/BF00128525 |
EPI图像是对光场的四维坐标进行重组的一种表征形式,把一个角度坐标和一个空间坐标组合,以二维图像的形式表示出来。在光场图像得到应用之前,传统方法是在二维光学几何基础上利用不同视角拍摄的图像之间的极线几何关系实现场景重建。最早使用EPI用于深度估计的工作是于1987年由Bolles等人提出的一种关于运动背景下的结构深度估计,但该工作是基于颜色一致性原则假设的,因此对遮挡和噪声不鲁棒[7]。之后,Zhang等人借助旋转平行四边形算子测量EPI的斜率,改善基于EPI的方法对强遮挡与噪声不鲁棒的特点[8]。该方法将算子在二维的EPI中集成,这样只需测量窗口两个部分之间的分部距离即可。Wanner等人利用EPI空间中的结构张量估计直线的局部方向,再引入平滑优化构建全局的深度[9]。基于该工作,Li等人利用结构信息建立了关于EPI的可靠性图[10]。该类方法对EPI斜坡分段处理,因此在分段处容易产生错误预测。Ziegler等人把二维的EPI信息扩展到了四维空间,取得了优秀的深度估计效果[11]。EPI的方法在深度沿着空间内一条直线连续变化的情况下具有出色的效果,但当直线受遮挡或噪声影响而中断时,就会产生错误预测。而若引入分段处理或其他的约束条件,算法的复杂度又会增大。
基于重聚焦的深度估计方法
光场图像的一大特点就是可以先拍照后聚焦,我们知道不同深度的物体在多视角图像中对应的视差值是不同的,那么将多视角子图像按照一定规律进行平移叠加就可以呈现出不同的聚焦效果。那么反过来思考:处于焦平面处的物体更清晰,其他平面的物体会模糊,我们根据这一特性可以根据焦点堆栈来反推深度。
目前基于重聚焦的深度估计方法,大致思路都是从以下路线进行:
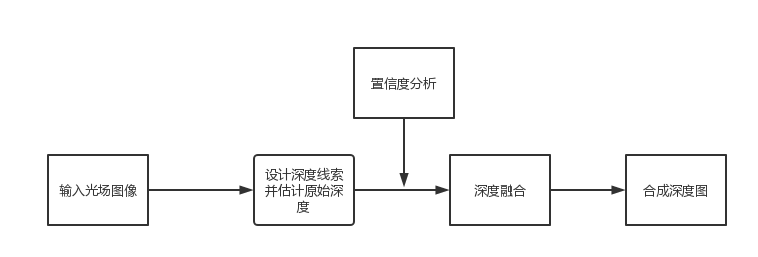
图5 基于重聚焦深度估计流程图
其中深度线索及原始深度估计是通过焦点堆栈来获取离焦量,之后借助离焦量(也有在离焦量的基础上结合其他线索的方法)来估计初始深度;但是得到的初始深度并不能完全反映真实的场景深度,还要引入一个新的控制变量——置信度,来约束优化深度,例如Tao估计离焦量与深度之间的变化曲线来引入一个主次峰值比例来作为置信度,从而优化深度值,最后进行深度融合[5]。学者们也提出了不同的估计方法,下表列举了一些较为有代表性的方法:
论文名称 | Depth from combining defocus and correspondence using light-field cameras |
论文作者 | Tao M W, Hadap S, et al. |
DOI | 10.1109/ICCV.2013.89 |
论文名称 | Robust light field depth estimation for noisy scene with occlusion |
论文作者 | Williem W, Kyu Park, et al. |
DOI | 10.1109/CVPR.2016.476 |
论文名称 | Occlusion-Aware Depth Estimation Using Light-Field Cameras |
论文作者 | Wang, Ting Chun, et al. |
DOI | 10.1109/ICCV.2015.398 |
论文名称 | Depth from shading, defocus, and, correspondence using light-field angular coherence |
论文作者 | Tao, Michael W, et al. |
DOI | 10.1109/CVPR.2015.7298804 |
目前针对基于重聚焦的深度估计方法,主要集中于深度线索的改进,提升算法针对遮挡和噪声的鲁棒性。基于重聚焦的深度估计方法在重复的纹理和强噪声场景下有较好的效果,但是在时间和算法表现上还需要进一步的权衡。
基于学习的深度估计方法
随着深度学习的兴起,越来越多的学者将其应用到深度估计当中;与基于优化的方法相比,深度学习只需要预先完成训练,就可以快速预测出场景深度,并且对噪声、遮挡等情况也更加的鲁棒,并且不被算法复杂度或计算时间影响,但是将其应用到光场领域算法仍然不多,同时网络训练阶段易受训练数据和网络结构的制约。下表是一些较为代表性的算法:
论文名称 | Neural EPI-volume networks for shape from light field |
论文作者 | Heber S, Yu W, Pock T. |
DOI | 10.1109/ICCV.2017.247 |
论文名称 | What sparse light field coding reveals about scene structure |
论文作者 | Johannsen O, Sulc A, Goldluecke B. |
DOI | 10.1109/CVPR.2016.355 |
论文名称 | EPINET: A fully-convolutional neural network using epipolar geometry for depth from light field images |
论文作者 | Shin C, Jeon H G, ea al. |
DOI | 10.1109/CVPR.2018.00499 |
论文名称 | Convolutional networks for shape from light field |
论文作者 | Heber S, Pock T. |
DOI | 10.1109/CVPR.2016.407 |
虽然深度学习可以有效学习预测光场的深度信息,但目前受制于硬件算力和光场数据资源稀少的问题,算法的最终效果仍然具有提升的额空间,在数据资源一定的前提下,众多学者都致力于提升网络的学习效率,以应对光场中大量信息冗余的问题;例如尝试对光场数据进行预处理,以降低网络需要学习的参数。此外光场中的信息繁杂,能否高效地筛选重要的步伐并抑制不重要的部分,也是影响网络性能和效率的关键。
部分代表性算法结果展示
多视角立体匹配
在这里展示Jeon等人提出的基于相移理论的亚像素多视角立体匹配算法[2]。该方法的思路是:
将图像转换到频域进行匹配(为了克服基线短的问题)——>匹配代价构建——>构建迭代优化模型——>深度图优化
该方法中,作者一共设计了两种优化模型,一种是多标签优化模型,一种是迭代优化模型,下图是不同方法的结果展示图:

图6 多视角立体匹配结果展示
图a 子孔径图像中心视图,图b 基于初始成本量的深度图,图c 加权均值滤波优化后的深度图,图d 基于多标签优化模型优化后的深度图,图e 迭代优化后的深度图
基于重聚焦的方法
这里展示Tao等人提出的方法,其算法主要是做了2件事情,首先是设计两种深度线索并估计原始深度;之后是进行置信度分析并进行深度融合[5];其算法框架以及分步结果如下:
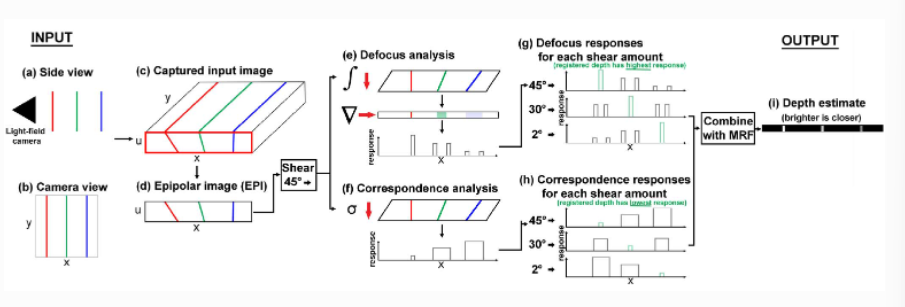
图7 基于重聚焦的算法结构展示图
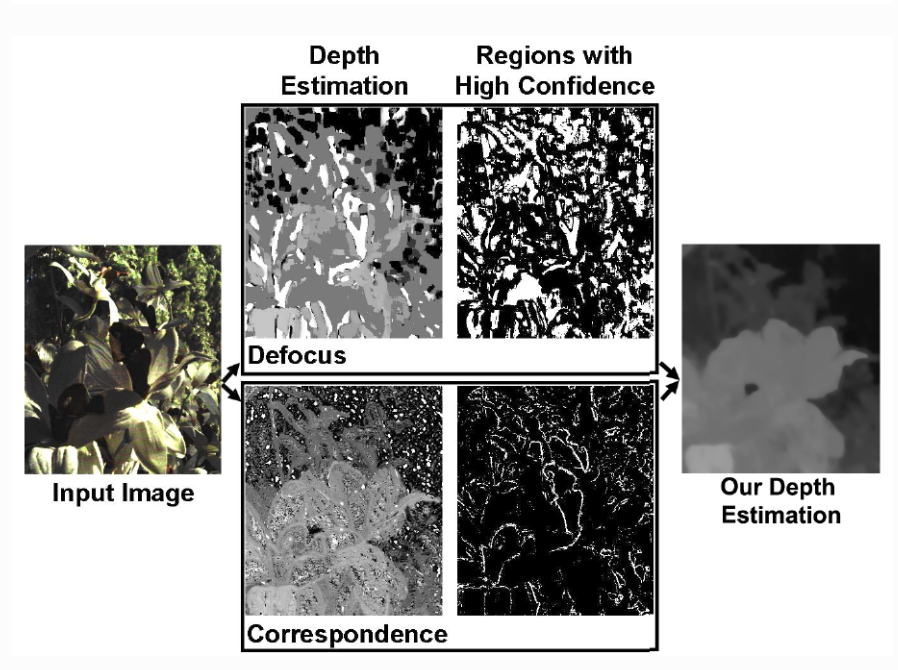
图8 基于重聚焦的结果展示图
基于EPI的方法
这里展示Wanner等人提出的方法,其方法在借助EPI估计视差的基础之上设计了一种连续的全变分框架,提出了一种结构张量发来估计EPI图像中的斜率,从而生成视差图,其方法假设子孔径图像序列之间的亚像素偏差是固定的,能够快速生成视差图,但是该方法在边缘部分估计误差较大[9]。下图是不同数据集下的视差估计结果:
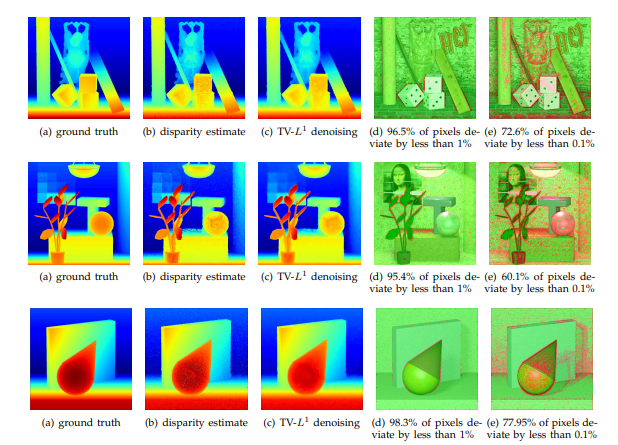
图9 基于EPI的结果展示图
(图a 为视差背景图,图b 优化钱前的视差图,图c采用全变分框架优化后的视差图;图d、e是像素偏差比例)
基于学习的方法
这里展示比较有代表性的方法——EPINET的网络框架图以及结果;该网络结构的特点是对输入的光场数据进行4个不同角度的堆叠处理,之后将每个角度的特征进行堆叠卷积操作,期望获取不同角度特征之间的关系,最后使用了ConvReLU-Conv结构来获取亚像素级的估计精度[14]。
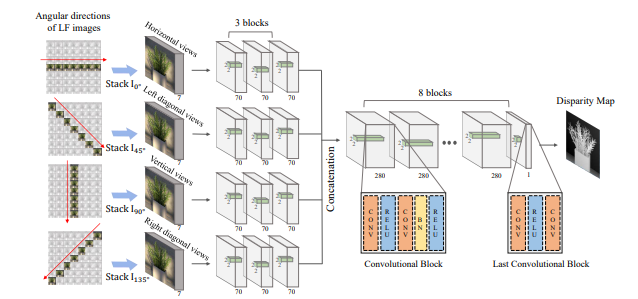
图10 网络结构图
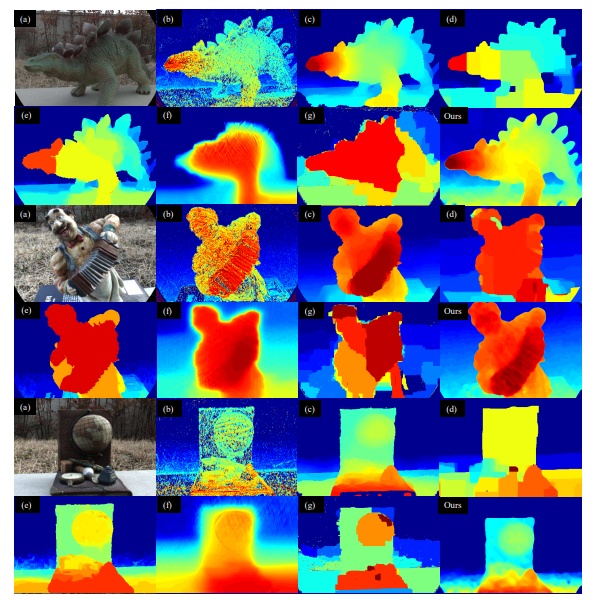
图11 EPINET与不同方法的结果对比图
结语
本期光场新知向大家介绍了目前国内外光场深度估计的主流方法,同时各主流方法中选了一个代表性方法进行结果展示;目前国内外基于光场图像进行深度估计的方法依然较少,同时现有方法各有优缺点,希望本期光场新知能够为大家在今后的研究道路上带来些许帮助,如果觉得本期光场新知对您有所帮助,不妨勾勾小指头点个在看点个赞。
参考文献
[1] Yu Z, Guo X, Lin H, et al. Line assisted light field triangulation and stereo matching[C]//Proceedings of the IEEE International Conference on Computer Vision. 2013: 2792-2799.
[2] Jeon H G, Park J, Choe G, et al. Accurate depth map estimation from a lenslet light field camera[C]//Proceedings of the IEEE conference on computervision and pattern recognition. 2015: 1547-1555.
[3] Heber S, Pock T. Shape from Light Field Meets Robust PCA[C]. european conference on computer vision, 2014: 751-767.
[4] Ng, Ren, Levoy, Marc, Duval, Gene,et al. Light Field Photography with a Hand-held Plenoptic Camera[J]. stanford university cstr, 2005.
[5] Tao M W, Hadap S, Malik J, et al. Depth from combining defocus and correspondence using light-field cameras[C]//Proceedings of the IEEE International Conference on Computer Vision. 2013: 673-680.
[6] Williem W, Kyu Park I. Robust light field depth estimation for noisy scene with occlusion[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 4396-4404.
[7] Bolles R C, Baker H H, Marimont D H. Epipolar-plane image analysis: An approach to determining structure from motion[J]. International journal of computer vision, 1987, 1(1): 7-55.
[8] Zhang S, Sheng H, Li C, et al. Robust depth estimation for light field via spinning parallelogram operator[J]. Computer Vision and Image Understanding, 2016, 145: 148-159.
[9] Wanner S, Goldluecke B. Variational light field analysis for disparity estimation and super-resolution[J]. IEEE transactions on pattern analysis and machine intelligence, 2013, 36(3): 606-619.
[10] Li J, Lu M, Li Z N. Continuous depth map reconstruction from light fields[J]. IEEE Transactions on Image Processing, 2015, 24(11): 3257-3265.
[11] Ziegler R, Bucheli S, Ahrenberg L, et al. A Bidirectional Light Field ‐ Hologram Transform[C]//Computer Graphics Forum. Oxford, UK: Blackwell Publishing Ltd, 2007, 26(3): 435-446.
[12] Heber S, Yu W, Pock T. Neural EPI-volume networks for shape from light field[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 2252-2260.
[13] Johannsen O, Sulc A, Goldluecke B. What sparse light field coding reveals about scene structure[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 3262-3270.
[14] Shin C, Jeon H G, Yoon Y, et al. Epinet: A fully-convolutional neural network using epipolar geometry for depth from light field images[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 4748-4757.
[15] Heber S, Pock T. Convolutional networks for shape from light field[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 3746-3754.
来源:工光场成像LightField
本文仅做学术分享,如有侵权,请联系删文。