
CVPR2021|神经网络如何进行深度估计?

极市导读
与深度神经网络相比,人类的视觉拥有更强的泛化能力,所以能够胜任各项视觉任务。结合人类视觉系统“通过观察结构信息获得感知能力”的特点,本文提出了一种新的深度估计方法,能够赋予神经网络强大的深度估计的泛化能力。目前,相关工作的论文已被 CVPR 2021 收录。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
在深度学习的驱动下,如今计算机已经在多个图像分类任务中取得了超越人类的优异表现。但面对一些不寻常的图像,以“深度”著称的神经网络还是无法准确识别。与此相比,人类的视觉系统是通过双眼的立体视觉来感知深度的。通过大量实际场景的经验积累以后,人类可以在只有一张图像的情况下,判断图像中物体的前后距离关系。
在计算机视觉领域,单目深度估计试图模拟人类的视觉,旨在在只有一张图像作为输入的情况下,预测出每个像素点的深度值。单目深度估计是 3D 视觉中一个重要的基础任务,在机器人、自动驾驶等多个领域都具有广泛的应用,是近年来的研究热点。
目前通用的解决方案是依赖深度学习强大的拟合能力,在大量数据集上进行训练,试图获取深度估计的能力。这一“暴力”解法尽管在某些特定数据集的测试场景上取得了优异的结果,但是网络的泛化能力较差,很难迁移到更一般的应用情形,无法适应不同的光照条件、季节天气,甚至相机参数的变化。其中一个具体的例子就是,相同的场景在不同光照条件下的输入图像,经过同一个深度估计网络,会出现截然不同的预测结果。
造成这一结果的原因在于,从人类感知心理学的相关研究中可以发现人的视觉系统更倾向于利用形状结构特征进行判断,而卷积神经网络则更依赖纹理特征进行判断。
例如,给定一只猫的图像,保留猫的轮廓,再使用大象的纹理去取代猫的皮毛纹理,人类倾向于认为图像的类别是猫,但是网络却会判定为大象。这种不一致性,会导致网络强行学习到的规律和人类不一致,很难完成对人类视觉系统的模拟。具体到深度估计领域,图像的纹理变化,例如不同的光照、天气、季节造成的影响都会对模型产生较大的影响。

另一个更为严重的问题,是网络容易根据局部的颜色信息来进行判断,而不是根据图像整体的布局。比如,深度网络会把前方路面上的白色卡车误认为是白云,将较近距离的卡车判断为较远距离的云,这种误判在自动驾驶场景中非常致命,会导致车辆无法对白色卡车进行合理规避,酿成严重事故。
将人类视觉用于深度估计
如何解决上述两个“致命”问题,从而提高深度神经网络的泛化能力?
尽管“误判”问题可以通过扩大训练数据集来缓解,但是收集数据本身会带来大量的人力、物力成本。而使用计算机图形图像学技术虽然可以以较低的成本生成大量的训练数据,但是由于合成数据和真实数据存在色彩色调不一致的情况,所以合成数据集上训练的深度估计网络也很难泛化到实际应用场景中。
因此,微软亚洲研究院的研究员们提出了一个更通用的解决思路:模仿人类视觉系统。相关工作“S2R-DepthNet: Learning a Generalizable Depth-specific Structural Representation”(论文链接:https://arxiv.org/pdf/2104.00877.pdf)已被 CVPR 2021 接受。通过结合人类的视觉系统特点,该工作探究了网络进行单目深度估计的本质,并赋予了网络强大的深度估计泛化能力。

具体的研究思路是:考虑到人类视觉系统更依赖结构信息来进行感知,例如人可以从仅包含结构信息的草图中获取场景的深度信息,研究员们通过对图像中的结构信息和纹理信息进行解耦,先提取图像中的结构信息,去除无关的纹理信息,再基于结构信息进行深度估计。
这样设计的深度估计网络去除了对纹理信息的影响,可以做到更强的泛化能力。论文中的模型(S2R-DepthNet, Synthesic to Real Depth Network),仅在合成数据上进行训练,不接触任何目标域的真实图像,所得到的模型无需任何额外操作就可以直接在实际的数据集上取得很好的深度估计效果。该方法远超基于域迁移(Domain Adaptation)的方法。
S2R-DepthNet 的网络结构为了获得深度特定的结构表示,利用提出的结构提取模块 STE 从图像中提取出通用的结构表征,如图2所示。可是此时得到的结构表示是一个通用的并且低级的图像结构,其中包含了大量与深度无关的结构信息。例如平滑表面的结构(车道线或者墙上的照片)。
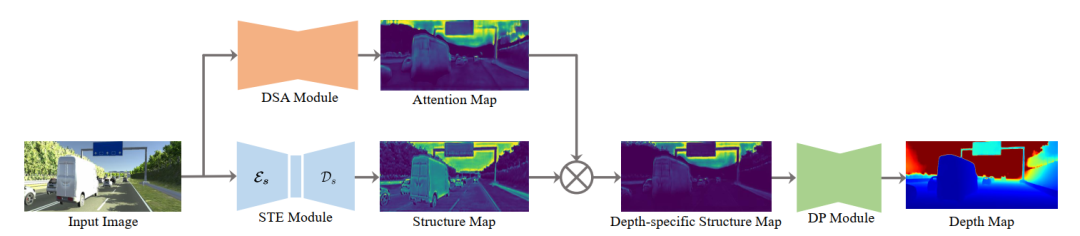
所以研究员们进一步提出了一个深度特定的注意力模块 DSA 去预测一个注意力图,以抑制这些与深度无关的结构信息。由于只有深度特定的结构信息输入到了最终的深度预测网络中,因此,训练“成熟”的 S2R-DepthNet 泛化能力极强,能够“覆盖”没见过的真实数据。
STE 模块目的是为了从不同风格的图像中提取领域不变的结构信息。如图3所示,STE 模块包含了一个编码器 Es 去提取结构信息,和一个解码器 Ds 去解码编码的结构信息到结构图。
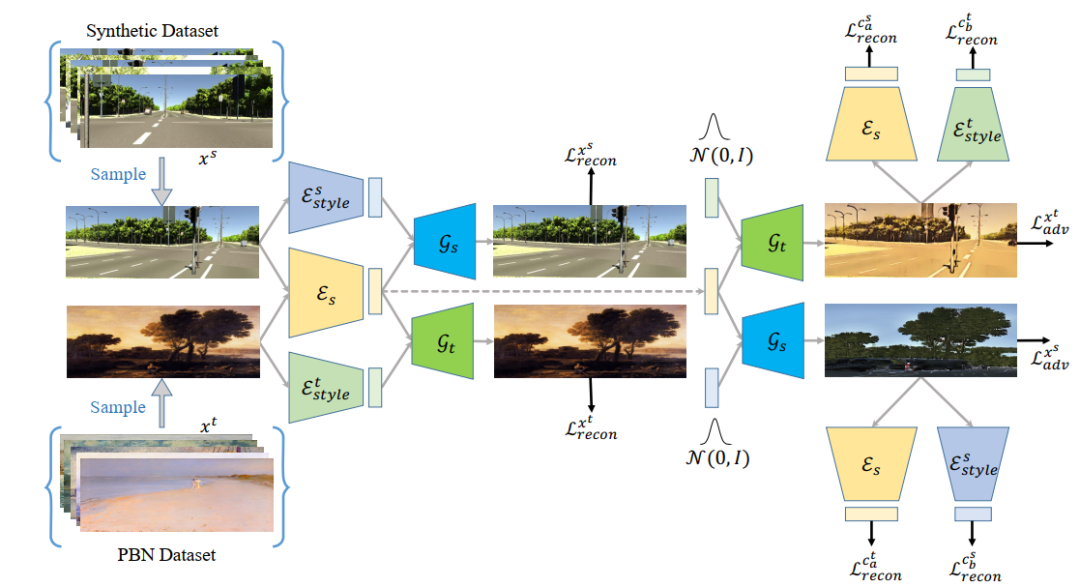
如图4所示,研究员们利用了图像到图像转换的框架去训练 STE 的编码器 Es。而为了使得网络可以适应多个风格的图像,并将通用的图像结构从图像中解耦出来,研究员们用一个风格数据集Painter By Numbers (PBN)作为目标域,合成数据作为源域,通过共有的结构编码器和两个私有的风格编码器,分别编码出源域和目标域的结构信息和风格信息。再利用图像自重建损失、潜层特征自重建损失和对抗损失结合的方式将结构信息和风格信息解耦。通过这种方式训练的结构编码器可以编码出通用的结构信息。

为了训练 STE 模块的解码器,研究员们在其后加了一个深度估计网络,通过对预测的深度施加损失,便可以通过结构图预测出深度图。此外研究员们还用了一个启发性的损失函数,施加在结构图上,以突出结构图中深度相关的区域。如以下公式所示。
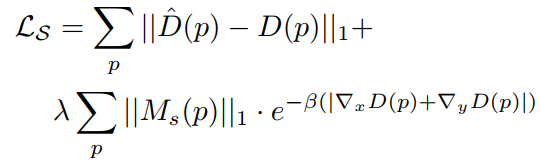
提取出的结构图是通用的结构图,不但包含深度相关的结构信息,同时也包含与深度无关的结构信息,因此通过提出深度相关注意力模型预测注意力图,可以有效地抑制与深度无关的结构信息。由于结构编码器中包含了多个 IN 层,导致其损失了很多判别特征,很难包含语义信息,因此设计的深度相关注意力模块使用了大量的膨胀卷积,可以有效在保持分辨率的情况下增大感受野。
通过上述注意力模块,研究员们可以得到与深度相关的结构化表示。直接输入到深度估计网络中,便可进行深度预测,从而在不同领域之间进行迁移。
研究员们可视化了学到的通用结构表示和深度特定的结构表示,如图2所示,即使合成数据和真实数据在图像上有明显的不同,学到的结构图和深度特定的结构表示也可以共享很多相似性。
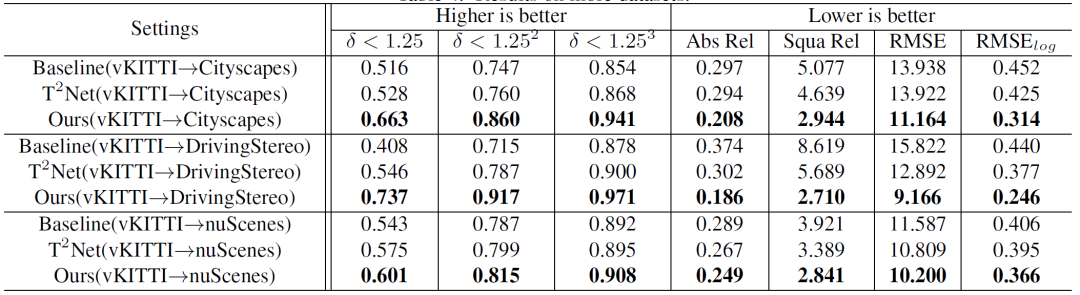
该方法的量化结果如表格1所示。域迁移方法在使用合成数据训练的过程中,加入了目标域的真实场景图像,此方法在训练过程中只用了合成数据图像,已取得了显著的泛化能力的提升。其原因在于抓住了深度估计任务结构化表示的本质特征。
研究员们提出的结构化表征方法更复合人类视觉系统的特点,因此可以将其推广到其它任务,例如图像分类、图像检测和图像分割等。同时,研究员们也将整个训练过程进行了简化,将所有的结构化表征学习通过一个基于 ResNet 的 backbone 网络来进行实现,通过在 ImageNet 上训练,该模型在多个下游任务(分类、检测和分割)的测试中,均取得了目前最优的模型泛化能力。其相关工作已投稿 NeurIPS 2021,论文和代码将于近期公开。
论文标题:S2R-DepthNet: Learning a Generalizable Depth-specific Structural Representation
地址:https://arxiv.org/pdf/2104.00877.pdf
代码:https://github.com/microsoft/S2R-DepthNet
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“79”获取CVPR 2021:TransT 直播链接~

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
