
【深度学习】谷歌工程师万字好文:我们为何追求高性能深度学习?如何实现?

原文:High Performance Deep Learning
作者:Gaurav Menghani(谷歌研究院 | 软件工程师)
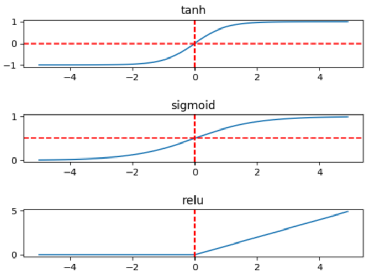
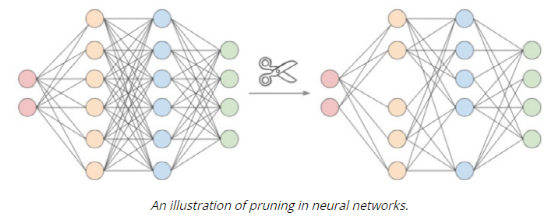
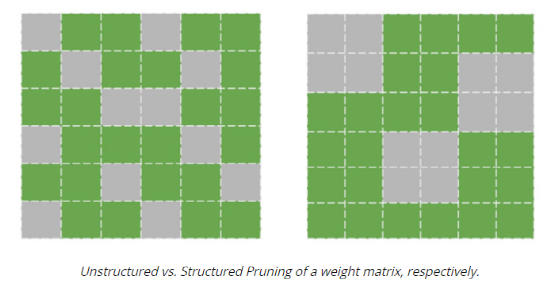
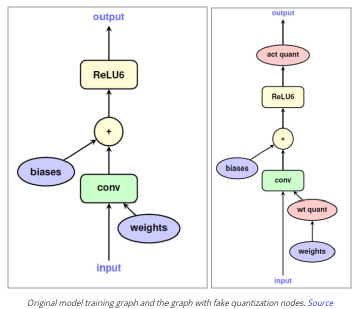
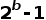 (其中 b 是精度位数),并线性地将它们之间的所有值外推(extrapolate)为整数。通常,这足以减少模型的大小。例如,如果 b = 8,则将 32 位浮点权值映射为 8 位无符号整数(unsigned integers),该操作可以将空间减少 4 倍。在进行推理(计算模型预测)时,我们可以使用数组的量化值和最小 & 最大浮点值恢复原始浮点值(由于舍入误差)的有损表示(lossy representation)。鉴于要量化模型的权重,于是此步被称为权重量化(Weight Quantization)。
(其中 b 是精度位数),并线性地将它们之间的所有值外推(extrapolate)为整数。通常,这足以减少模型的大小。例如,如果 b = 8,则将 32 位浮点权值映射为 8 位无符号整数(unsigned integers),该操作可以将空间减少 4 倍。在进行推理(计算模型预测)时,我们可以使用数组的量化值和最小 & 最大浮点值恢复原始浮点值(由于舍入误差)的有损表示(lossy representation)。鉴于要量化模型的权重,于是此步被称为权重量化(Weight Quantization)。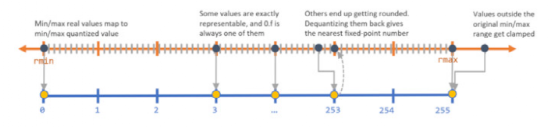
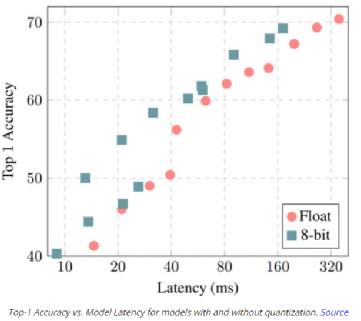
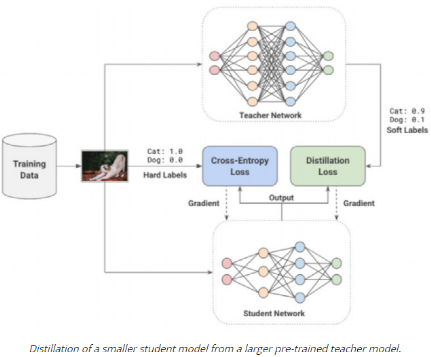
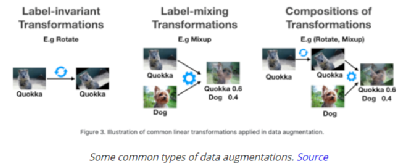
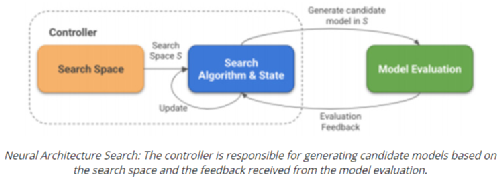
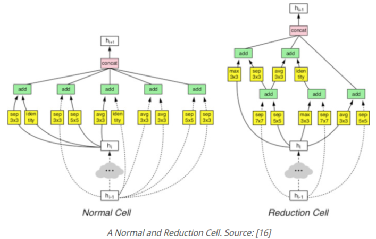
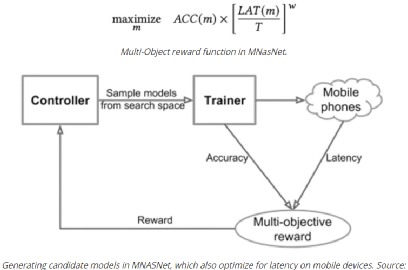
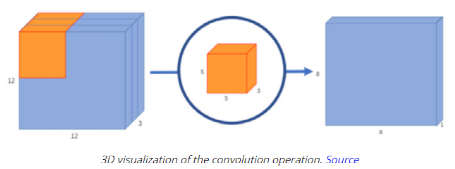
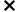 3, 55 等),第三维与输入通道的数量相同。每个过滤器都对输入进行卷积操作,生成给定过滤器的特征映射。每个过滤器都可以学习检测边缘等特征(水平、垂直、对角线等),从而在特征映射中发现该特征存在的更高值。总的来说,单个卷积层的特征映射可以从图像中提取有意义的信息。堆叠在上面的卷积层将使用前一层生成的特征映射作为输入,逐步学习更复杂的特征。
3, 55 等),第三维与输入通道的数量相同。每个过滤器都对输入进行卷积操作,生成给定过滤器的特征映射。每个过滤器都可以学习检测边缘等特征(水平、垂直、对角线等),从而在特征映射中发现该特征存在的更高值。总的来说,单个卷积层的特征映射可以从图像中提取有意义的信息。堆叠在上面的卷积层将使用前一层生成的特征映射作为输入,逐步学习更复杂的特征。
 ×
×  × input_channels,其中和通常是相等的。针对每个滤波器都是同样的操作,因此卷积操作同时发生在 x 和 y 维度的空间,并在 z 维度中向纵深处进行。
× input_channels,其中和通常是相等的。针对每个滤波器都是同样的操作,因此卷积操作同时发生在 x 和 y 维度的空间,并在 z 维度中向纵深处进行。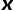 和
和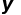 维度中使用 × 过滤器进行空间卷积。
维度中使用 × 过滤器进行空间卷积。
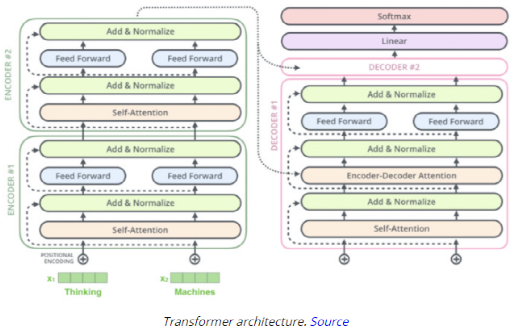
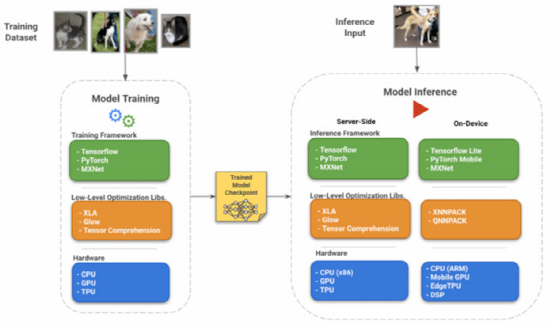
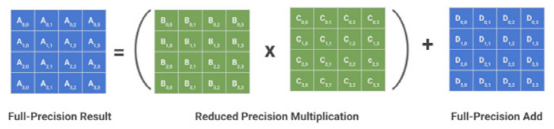

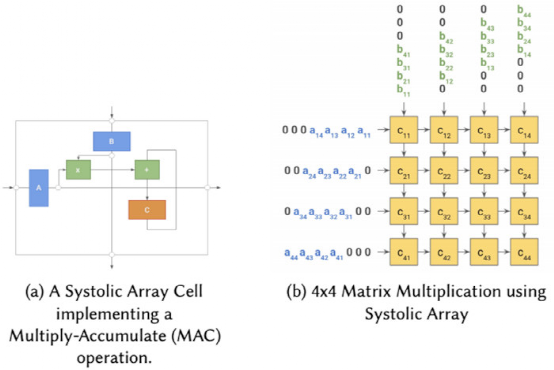


往期精彩回顾 本站qq群851320808,加入微信群请扫码:
评论