
实操教程:用一维卡尔曼滤波器来估计运动物体的位置和速度

极市导读
本文作者通过创建了一个一维卡尔曼滤波器,结合物体运动的不确定性,来估计物体未来的位置以及运动速度的过程,解释了卡尔曼滤波器以及高斯的相关概念。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
什么是卡尔曼滤波器?
卡尔曼滤波器为每个结果状态找到最佳的平均因子。另外,以某种方式保存过去的状态。它针对每个时间范围对变量执行联合概率分布。该算法对每个步骤使用新的均值和新方差,以便计算结果的不确定性,并尝试为测量更新(传感/预测)和运动更新(运动)的每个时间范围提供准确的测量。该算法还使用其他误差和统计噪声来表示初始的不确定性。
卡尔曼滤波器的目的
• 将来自各种传感器(如LiDAR和Radar跟踪器)的数据输入转换为可用形式。计算和推断速度。
• 减少目标位置和速度的测量误差(噪声)。
• 使用先前的状态估计和新数据预测目标的未来状态。
• 简单,实用和可移植的算法。
• 估计一个连续状态和结果,卡尔曼滤波器给了我们一个单峰分布。
卡尔曼滤波器的工作
卡尔曼过滤为我们提供了一种数学方法,这种方法依据物体的初始位置和相关变量来推断物体之后的运动速度和状态。因此,在这里,我们将创建一个一维卡尔曼滤波器,设置初始位置,结合物体运动的不确定性,来估计物体未来的位置以及运动速度。此外,如果我们想了解卡尔曼滤波器的工作原理,我们首先需要了解一些有关高斯的知识,它代表卡尔曼滤波器中的单峰分布。
高斯是在位置空间上的连续函数,其下面的面积之和最多为1。高斯的特征在于两个参数,平均值,经常缩写为希腊字母μ,高斯的宽度通常被称为方差即σ ²。所以,我们常用平均值和方差来寻找对象的位置,获得最佳估计。另外,宽度越大,不确定性越大。
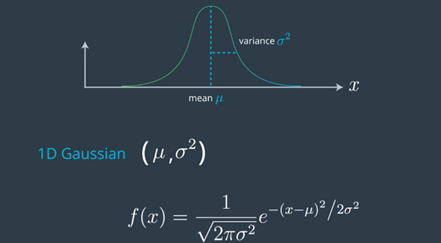
上图表示高斯的均值(μ)和方差(σ²)。平均值(μ)越高,物体在该位置出现的机会就越高。相反,如果方差(σ²)较大,即分布较宽,则该对象的不确定性较高;可以放置在高斯内部的任何位置。
就公式而言,它是二次函数的指数,我们取表达式的指数。我们的查询点x相对于平均值(μ)的二次方差,除以方差(σ²),乘以-(1/2)。现在,如果x =μ,则分子变为0,如果x为0,即1。事实证明,我们必须在2πσ²的平方根上对常数进行归一化处理。
高斯特性
高斯是其特征在于通过给定的指数函数平均值(μ),其限定了高斯曲线的峰值的位置,和一个方差(σ ²)限定曲线的宽度/扩散。所有高斯都是:对称的。它们具有一个峰(也称为“单峰”分布),并且在该峰的两侧均具有指数下降。
方差是高斯分布的度量;方差越大,对应的高斯越短。差异也是确定性的度量;如果试图找到最确定的位置,例如汽车的位置,则需要一个高斯函数,其均值是汽车的位置并且不确定性/传播范围最小。我们编写一个高斯函数:
from math import *import matplotlib.pyplot as pltimport numpy as np# gaussian functiondef f(mu, sigma2, x):''' f takes in a mean and squared variance, and an input xand returns the gaussian value.'''coefficient = 1.0 / sqrt(2.0 * pi *sigma2)exponential = exp(-0.5 * (x-mu) ** 2 / sigma2)return coefficient * exponential
改变均值
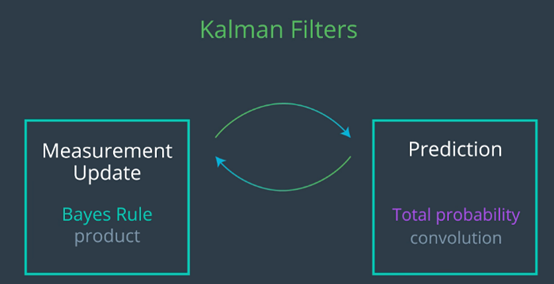
在卡尔曼滤波器中,我们迭代使用贝叶斯规则的测量(测量更新),贝叶斯规则仅是乘积或乘法,而运动更新(预测)则使用总概率(卷积或加法)进行迭代。
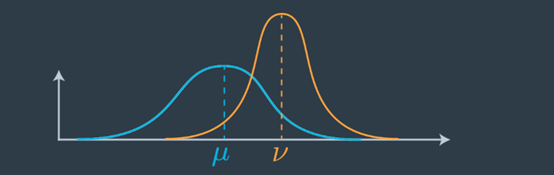
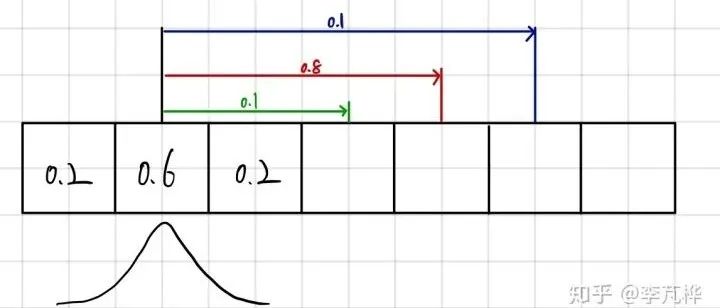
为了理解周期,我们假设我们正在对车辆进行定位并且我们有一个先验分布(蓝色高斯);这是一个非常宽泛的高斯平均值。现在,我们得到一个测量值(橙色高斯),它告诉我们有关车辆定位的信息。这是我们之前的一个例子,我们对位置不确定,但测量结果告诉我们有关车辆的位置信息。
事先分配和测量分配
注意:在上图中,Mu(μ)是先前的均值,Nu(v) 是新的测量均值。最终均值在两个旧均值,先验均值和测量均值之间移动。在测量方面,它要稍远一些,因为与以前相比,该测量可以更确定地确定车辆的位置。我们越确定,就越会在确定答案的方向上拉均值。
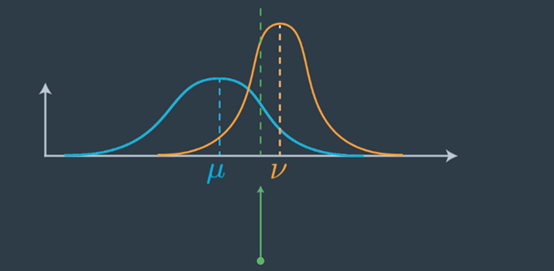
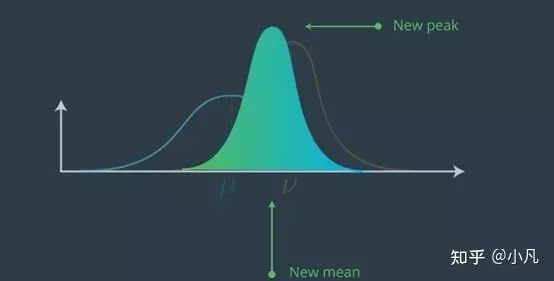
新高峰在哪里?
所得的高斯比两个分量的高斯更确定,即协方差小于设备中两个协方差中的任一个。直观上来说,是因为我们实际上获得了位置信息。在任一高斯装置中,这两个高斯都具有较高的信息量。
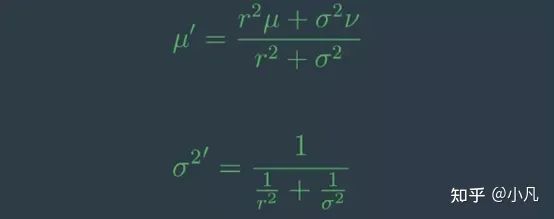
测量更新的公式
1.假设我们按照贝叶斯规则将两个高斯乘以一个先验概率和一个测量概率。先验的均值为Mu (μ),且为σ²,方差为Nu (v),协方差为r-square (r²)。
2. 然后,新的均值Mu prime (μ')是旧均值的加权和。Mu (μ)由r平方(r²)加权,Nu (v)由Sigma平方(σ²)加权,并由加权因子之和标准化。新的方差项将是Sigma平方素数(σ²')。
3. 显然,先验的高斯不确定性要高得多,因此σ²更大,这意味着Nu(v)的权重比Mu (μ)大得多。需要注意的是,方差项不受实际方法的影响,它仅使用以前的方差。
def update(mean1, var1, mean2, var2):''' This function takes in two means and two squared variance terms,and returns updated gaussian parameters.'''#Calculate the new parametersnew_mean = (var2*mean1 + var1*mean2)/(var2+var1)new_var = 1/(1/var2 + 1/var1)
高斯运动:
运动更新的公式
新的均值(μ')是旧均值Mu (μ)加上u的运动。因此,如果在x方向上移动了10米,那么它就是10米,并且知道σ²'是旧σ²加上运动高斯的方差(r²)。这就是我们所需要知道的,仅仅是补充。在预测步骤中得到的高斯只是将这两件事加起来,即mu(μ)加u和σ²加方差(r²)。
def predict(mean1, var1, mean2, var2):''' This function takes in two means and two squared variance terms,and returns updated gaussian parameters, after motion.'''#Calculate the new parametersnew_mean = mean1 + mean2new_var = var1 + var2return [new_mean, new_var]
过滤器管道:
# measurements for mu and motions, Umeasurements = [5., 6., 7., 9., 10.]motions = [1., 1., 2., 1., 1.]# initial parametersmeasurement_sig = 4.motion_sig = 2.mu = 0.sig = 10000. #0000000001## TODO: Loop through allmeasurements/motions## Print out and display the resultingGaussian# your code herefor i in range(len(measurements)):#measurement update, with uncertaintymu, sig = update(mu, sig, measurements[i], measurement_sig)print('Update: [{}, {}]'.format(mu, sig))#motion update, with uncertaintymu, sig = predict(mu, sig, motions[i], motion_sig)print('Predict: [{}, {}]'.format(mu, sig))# print the final, resultant mu, sigprint('\n')print('Final result: [{}, {}]'.format(mu,sig))
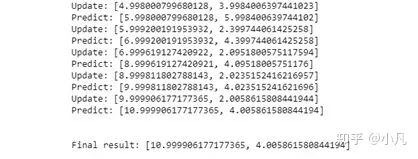
•现在,我们将所有内容放在一起编写一个具有这两个功能的主程序,进行更新和预测,并馈入一系列测量和运动。选择的示例中,测量值= 5,6,7,9,10,运动是1,1,2,1,1。如果初始估算为5,但我们将其设置为0,不确定性为10,000。
•假设测量不确定度为常数4,运动不确定度为常数2。运行该变量时,位置的第一个估算值基本上应为5–4.99,原因是初始不确定性太大,因此估算值占主导地位通过第一次测量。不确定性减少到3.99,这比测量不确定性要好一些。然后,预测将增加1,但是不确定性增加到5.99,这是运动不确定性2。
•再次基于度量6更新,得到的估计值为5.99,几乎是6。再次移动1。测量了7。移动了2.测量了9.移动了1.测量了10,然后移动了最终1。结果作为最终结果,该位置的预测为10.99,即10位置移动了1 ,以及不确定性(残余不确定性)4。
绘制高斯:
## Print out and display the final,resulting Gaussian# set the parameters equal to the output ofthe Kalman filter resultmu = musigma2 = sig# define a range of x valuesx_axis = np.arange(-20, 20, 0.1)# create a corresponding list of gaussianvaluesg = []for x in x_axis:g.append(f(mu, sigma2, x))# plot the resultplt.plot(x_axis, g)
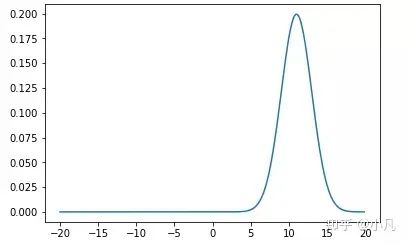
过滤器的实际工作方式
请记住,在测量更新中,measurement_sig(var2或σ²)= 4,在运动更新(预测)中,motion_sig(var2或σ²)= 2将保持恒定。除此之外,代码中的每个变量都会在每个时间步更新。例如,在过滤器管道的for循环中,mu和sig值将在测量更新中得到更新,然后将新的更新的mu和sig值输入到运动更新(预测)功能中。然后再次通过运动更新(预测)功能生成新值时,将这些更新后的值输入到测量更新(更新)功能中,循环继续进行,直到为车辆/物体的每个时间步长计算不确定性为止。
本文仅做学术分享,如有侵权,请联系删文。
推荐阅读
2020-12-25
2020-10-11
2020-11-08


#CV技术社群邀请函#
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
