
面向软件工程师的卡尔曼滤波器
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转自|磐创AI

与我的朋友交谈时,我经常听到:“哦,卡尔曼(Kalman)滤波器……我经常学它,然后我什么都忘了”。好吧,考虑到卡尔曼滤波器(KF)是世界上应用最广泛的算法之一(如果环顾四周,你80%的技术可能已经在内部运行某种KF),让我们尝试将其弄清楚。
在这篇文章的结尾,你将对KF的工作原理,其背后的想法,为什么需要多个变体以及最常见的变体有一个直观而详细的了解。
状态估计
KF是所谓的状态估计算法的一部分。什么是状态估计?假设你有一个系统(让我们将其视为黑箱)。黑箱可以是任何东西:你的风扇,化学系统,移动机器人。对于这些系统中的每一个,我们都可以定义一个状态。状态是我们关心的变量向量,可以描述系统处于特定时间点的“状态”(这就是为什么将其称为状态)。“可以描述”是什么意思?这意味着,如果你了解当时的状态向量k和提供给系统的输入,则可以了解当时的k+1的系统状态(与此同时使用系统工作原理的一些知识)。
例如,假设我们有一个移动的机器人,并且我们关心其在空间中的位置(并且不在乎其方向)。如果我们将状态定义为机器人的位置(x, y)及其速度,(
,
)并且我们有一个机器人如何运动的模型,那么就足以确定机器人的位置以及下一个时刻的位置。
因此,状态估计算法估计系统的状态。为什么要估算呢?因为在现实生活中,外部观察者永远无法访问系统的真实状态。通常有两种情况:你可以测量状态,但是测量结果会受到噪声的影响(每个传感器只能产生一定精度的读数,可能对你来说还不够),或者你无法直接测量状态。一个例子可能是使用GPS计算上述移动机器人的位置(我们将位置确定为状态的一部分),这可能会给你带来多达10米的测量误差,对于你可能想到的任何应用程序来说,这可能都不够精确。
通常,当你进行状态估计时,你可以放心地假设你知道系统的输入(因为是你给出的)和输出。由于测量了输出,因此它也会受到一定的测量噪声的影响。据此,我们将状态估计器定义为一个系统,该系统接收你要估计其状态的系统的输入和输出并输出系统状态的估计。
传统上,状态用表示x,输出用y或z,u是输入,
是估计状态。
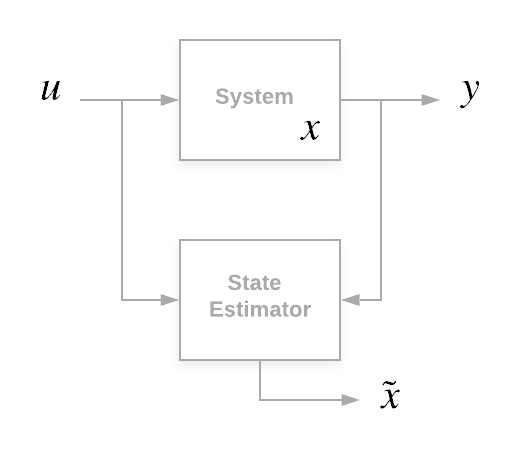
卡尔曼滤波器
你可能已经注意到,我们已经讨论了一些有关误差的内容:
你可以测量系统的输出,但是传感器会给出测量误差
你可以估计状态,但是作为状态估计它具有一定的置信度。
除此之外,我说过,你需要某种系统知识,你需要了解系统“行为”的模型(稍后会详细介绍),你的模型当然并不完美,因此你将拥有另一个误差。
在KF中,你可以使用高斯分布来处理所有这些不确定性。高斯分布是表示你不确定的事物的一种好方法。你当前确定的东西可以用分布的均值表示,而标准差可以说明你对该确定的信心。
在KF中:
你的估计状态将是具有一定均值和协方差的高斯随机变量(它将告诉我们该算法“确定”其当前估计的程度)
你对原始系统的输出度量的不确定性将用均值为0和一定协方差的随机变量表示(这将告诉我们我们对度量本身的信任程度)
系统模型的不确定性将由均值为0和一定协方差的随机变量表示(这将告诉我们我们对使用的模型有多信任)。
让我们举一些例子来了解其背后的想法。
不良模型,好的传感器,让我们再次假设你要跟踪机器人的位置,并且你在传感器上花费了很多钱,它们为你提供厘米级的精度。另一方面,你根本不喜欢机器人技术,搜索了一下,发现了一个非常基本的运动模型:随机游走(基本上是一个仅由噪声给出运动的粒子)。很明显,你的模型不是很好,不能真正被信任,而你的测量结果却很好。在这种情况下,你可能将使用非常窄的高斯分布(小方差)来建模测量噪声,而使用非常宽的高斯分布(大方差)来建模不确定性。
传感器质量差,模型好,如果传感器质量不好(例如GPS),但是你花费大量时间对系统进行建模,则情况恰好相反。在这种情况下,你可能将使用非常窄的高斯分布(小方差)来建模模型不确定性,而使用非常宽的高斯分布(大方差)来建模噪声。
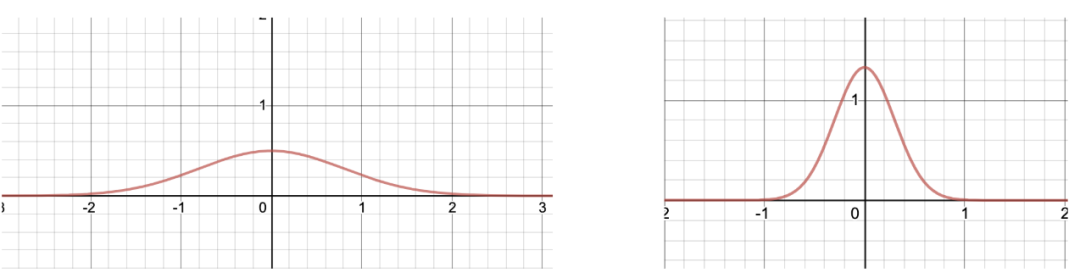
估计的状态不确定性如何?
KF将根据估计过程中发生的事情进行更新,你唯一要做的就是将其初始化为足够好的值。“足够好”取决于你的应用程序,你的传感器,你的模型等。通常,KF需要一点时间才能收敛到正确的估计值。
KF如何工作?
正如我们所说,要让KF正常工作,你需要对系统有“一定的了解”。特别是对于KF,你需要两个模型:
状态转换模型:某些函数,给定时间步k的状态和输入,给出时间步k+1的状态。

测量模型:某个函数,给定时间步k的状态,即可为你提供同一时间的测量结果
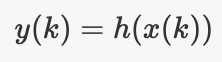
稍后,我们将了解为什么需要这些功能,让我们首先查看一些示例以了解它们的含义。
状态转换模型
该模型告诉你系统如何随时间变化(如果你还记得的话,我们之前曾谈到状态必须具有足够的描述性以及时推断系统行为)。这在很大程度上取决于系统本身以及你对系统的关心。如果你不知道如何对系统建模,则可以使用一些Google搜索来提供帮助。对于运动的物体(如果以适当的采样率测量),可以使用恒速模型(假定物体以恒定的速度运动),对于车辆,可以使用单轮脚踏车模型,等等……
让我们假设一种或另一种方式,我们建立了一个模型。我们在这里做出一个重要的假设,这对于KF的工作是必要的:你的当前状态仅取决于先例。换句话说,系统状态的“历史”会压缩为先前的状态,也就是说,给定先例状态,每个状态都独立于过去。这也称为马尔可夫假设。如果这不成立,你将无法仅根据先例来表达当前状态。
测量模型(Measurement model)
测量模型告诉你如何将输出和状态联系在一起。直观上,你需要这样做,因为你知道测量的输出,并且想要在估计期间从中推断出状态。同样,此模型因情况而异。例如,在移动机器人示例中,如果你的状态是位置并且你拥有GPS,则你的模型就是单位函数(identity function),因为你已经在知道了状态的有噪声版本。
每个步骤的数学公式和解释如下:

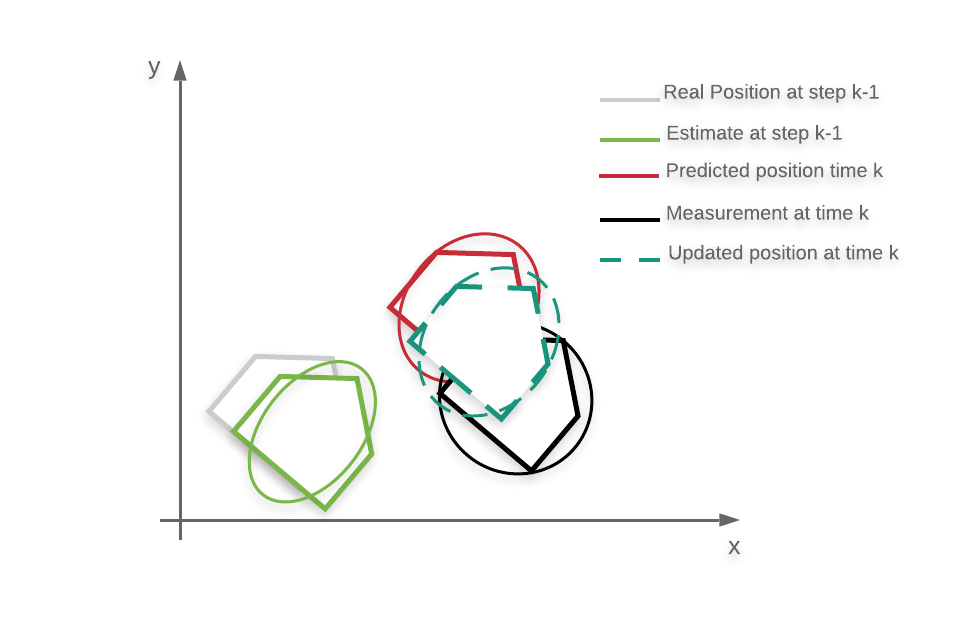
那么,KF实际如何运作?该算法分两个步骤工作,称为预测和更新。假设我们在时间步k,并且那时我们具有估计状态。首先,我们使用状态转换模型,并使估计状态预测到下一个时刻。这相当于说:鉴于我目前对状态的信念,我所拥有的输入以及对系统的了解,我希望我的下一个状态是这样。这是预测步骤。
现在,由于我们还具有输出和测量模型,因此我们实际上可以使用实际测量“校正”预测。在更新步骤中,我们采用预期状态,我们计算输出(使用测量模型)(2),并将其与实际测量的输出进行比较。然后,我们以“智能方式”使用两者之间的差异来校正状态估计(3)。
通常,我们在校正之前用apex -表示状态的估计,它来自于预测步骤。K是卡尔曼增益。这就是巧妙之处:K取决于我们对度量的信任程度,取决于我们对当前估计的信任程度(这取决于我们对模型的信任程度),根据这些信息,K“决定”预测的估计在多大程度上被测量纠正。如果我们的测量噪声与我们对来自预测步骤的估计的信任程度相比是“小”的,我们将使用测量对估计进行大的校正,如果相反,我们将对其进行最小程度的校正。
注意:为简单起见,我写方程式时就好像在处理普通变量一样,但是你必须考虑到在每一步中我们都在处理随机的高斯变量,因此我们还需要通过函数传播变量的协方差,而不仅仅是均值。
让我们举例说明。假设我们正在(再次)跟踪一个机器人的位置。实际位置显示为灰色,k时刻我们认为机器人处于绿色位置,估计协方差表示为一个椭圆。粗略地说,你可以从椭圆的形状看出,我们的过滤器在这一步对横向定位比在向前运动方向的定位更“自信”。在使用状态转换模型让系统演进的预测步骤之后,我们认为新的位置是红色的。由于椭圆在横向上变大了,我们现在对新的估计位置不太确定(例如,因为我们不太相信模型)。然后我们读取GPS,得到黑色的位置。在更新步骤中,实际的位置估计将是深绿色的虚线部分。如果我们更信任模型(与测量噪声协方差相比,协方差更小),估计值将更接近红色;如果我们更信任测量(与模型不确定性相比,噪声测量协方差更小),估计值将更接近红色。
KF家族
根据所使用的模型类型(状态转换和测量),可以将KF分为两个大类:如果模型是线性的,则具有线性卡尔曼滤波器,而如果它们是非线性的,则具有非线性卡尔曼滤波器。
为什么要区分?好吧,KF假设你的变量是高斯变量,当通过线性函数传递时,高斯变量仍然是高斯变量,如果通过非线性函数传递,则不正确。这打破了卡尔曼假设,因此我们需要找到解决方法。
历史上,人们发现了两种主要的方法:利用模型作弊和利用数据作弊。如果你在模型上做了弊你基本上是将当前估计周围的非线性函数线性化,这样你就回到了线性的情况下。这种方法称为扩展卡尔曼滤波(EKF)。这种方法的主要缺点是必须能够计算f()和h()的雅可比矩阵。或者,如果你在数据上作弊,你使用非线性函数,然后你尝试“高斯化”(如果这个词存在的话)你做出的非高斯分布。这是通过一种叫做无损变换的智能采样技术实现的。这个变换允许你用平均值和协方差来描述(近似地)一个分布(只有高斯分布才能被前两个矩完全描述)。这种方法称为无损卡尔曼滤波(UKF)。理论上,UKF优于EKF,因为无损变换比线性化模型得到的近似更接近结果分布。在实践中,你必须有相当大的非线性才能真正看到大的区别。
实际中的KF
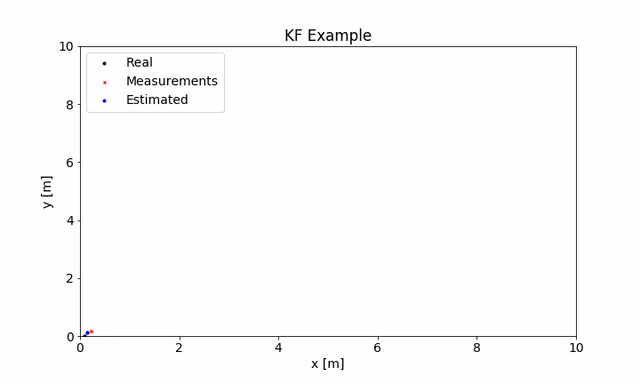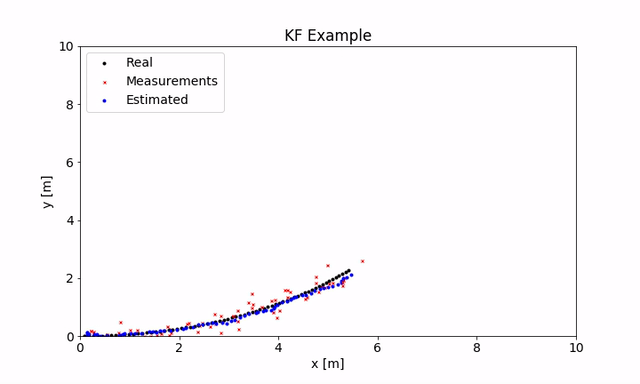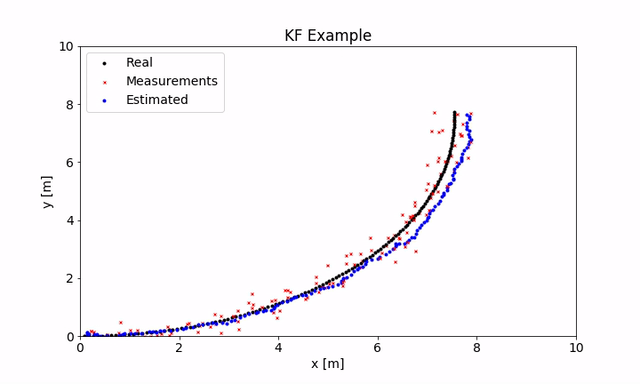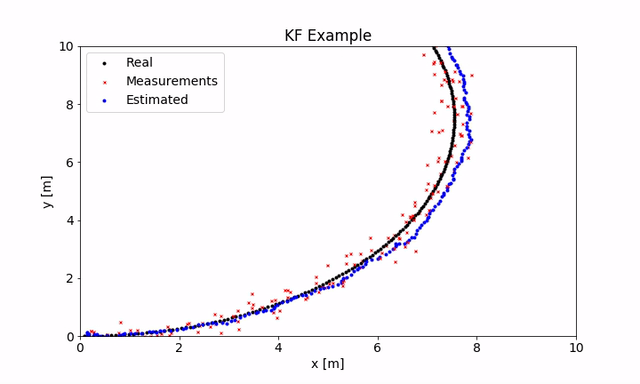
由于我谈到了很多有关带GPS的移动机器人的内容,因此我就此情况作了简短的演示(如果要使用它,可以在这里找到代码)。机器人的运动是使用单轮模型生成的。用于KF的状态转换模型是等速模型,其状态包含x和y位置,转向角及其导数。
机器人会及时移动(实际位置显示为黑色),在每个步骤中,你都会得到非常嘈杂的GPS测量值,该测量值给出x和y(红色)并估算位置(蓝色)。你可以使用不同的参数,看看它们如何影响状态估计。如你所见,我们可以进行非常嘈杂的测量,并对实际位置进行很好的估算。
奖励:卡尔曼增益的直观含义
让我们看一下线性KF情况下卡尔曼增益的公式,并试图更深入地了解增益的工作原理。
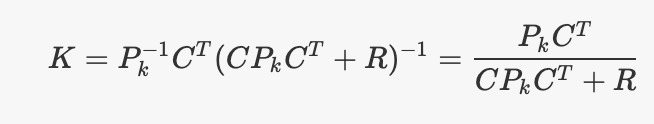
其中
,当前估算状态的协方差(我们对估算的信心程度)C是测量模型的线性变换,其中y(k) = Cx(k)和R是测量噪声的协方差矩阵。请注意,分数符号并不是真正正确的,但是可以使发生的事情更容易可视化。
根据等式,如果R变为0,则我们有:
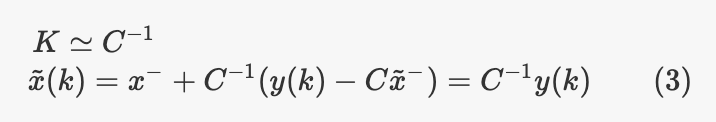
代入我们定义(3)的算法步骤,可以看到我们将完全忽略预测步骤的结果,并且使用测量模型的逆变换来获得仅来自测量的状态估计。
相反,如果我们非常信任模型/估计,
则将趋于0,得出:

因此,我们得到的最终估计与预测步长输出相同。
需要注意的是,我正在交替使用“信任模型”和“信任当前估计”。他们是不一样的但是他们是相关的,因为我们有多么信任预测的评估是我们有多信任模型(如预测步骤完成只使用模型)与我们有多么信任前一步的滤波的组合。
奖励2:库
有很多不错的库可以在线计算KF,这是我的一些最爱。
作为一个GO爱好者,我将从这个非常不错的GO库开始,其中包含几个预实现的模型:https://github.com/rosshemsley/kalman
对于Python,你可以查看:https://pykalman.github.io/
结论:我们深入研究了状态估计是什么,卡尔曼滤波器的工作原理,其背后的直觉是什么,如何使用它们以及何时使用。我们介绍了一个玩具(但现实生活中)的问题,并介绍了如何使用卡尔曼滤波器解决该问题。然后,我们更深入地研究了Kalman滤波器在幕后的实际作用。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
评论