
人脸关键点检测的数据集与核心方法发展综述
点击蓝字
关注我们

前言:本文作者为深度学习领域资深专家言有三。作者近期发布新书《深度学习之人脸图像处理:核心技术与案例实践》,由浅入深、全面系统地介绍人脸图像的各个研究方向和应用场景,包括但不限于基于深度学习的各个方向的核心技术。本书理论体系完备,讲解时提供大量实例,可供读者实战演练。
今天,我们特邀作者送出5本新书作为极市粉丝福利,获取方式见文末。
1、什么是关键点检测?

2、人脸关键点标注点数发展
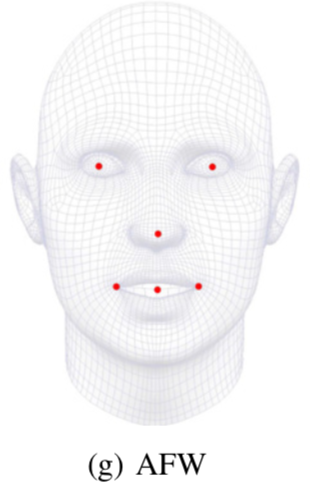
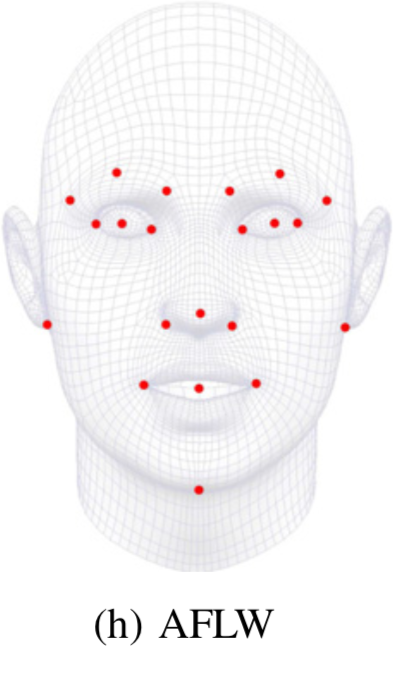

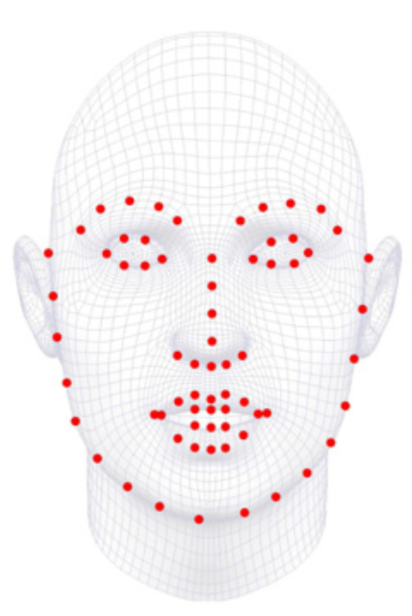
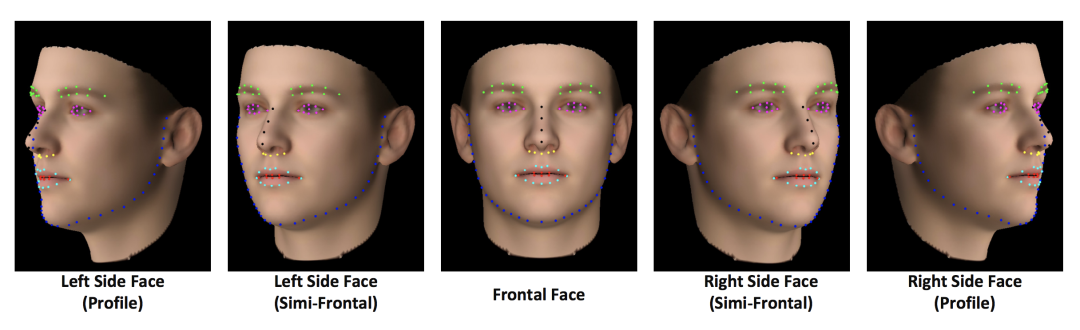

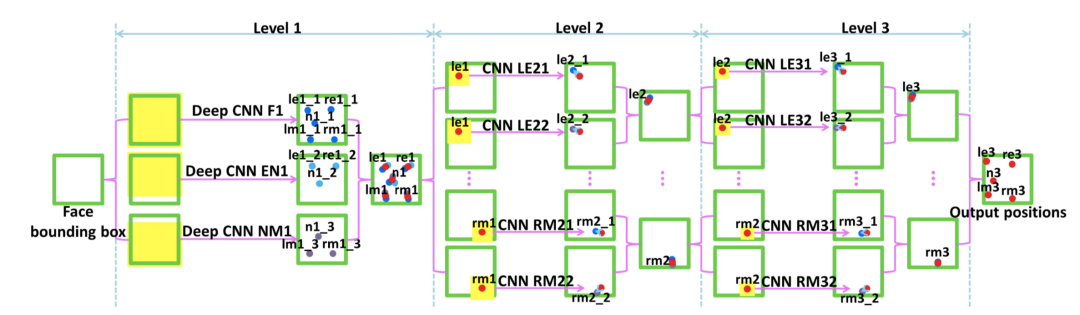
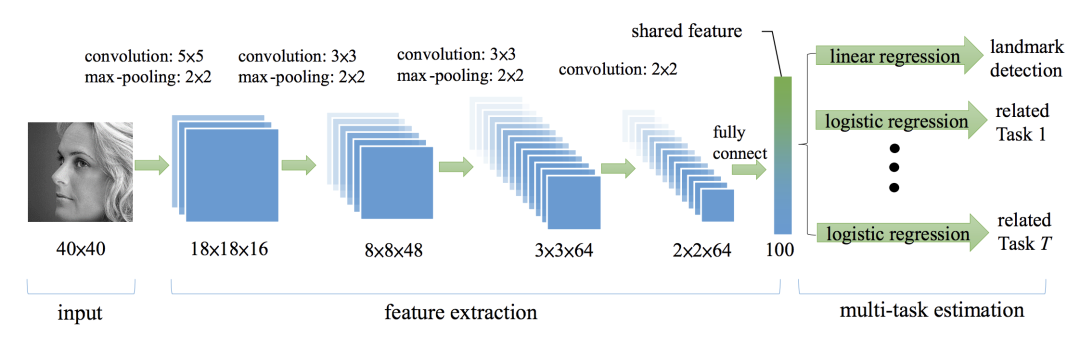
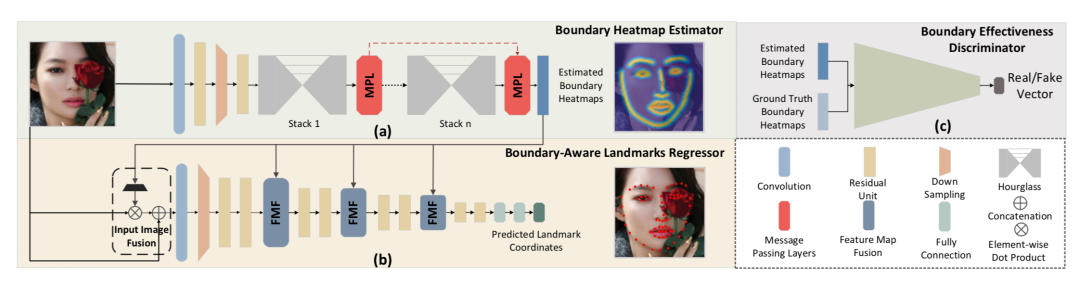
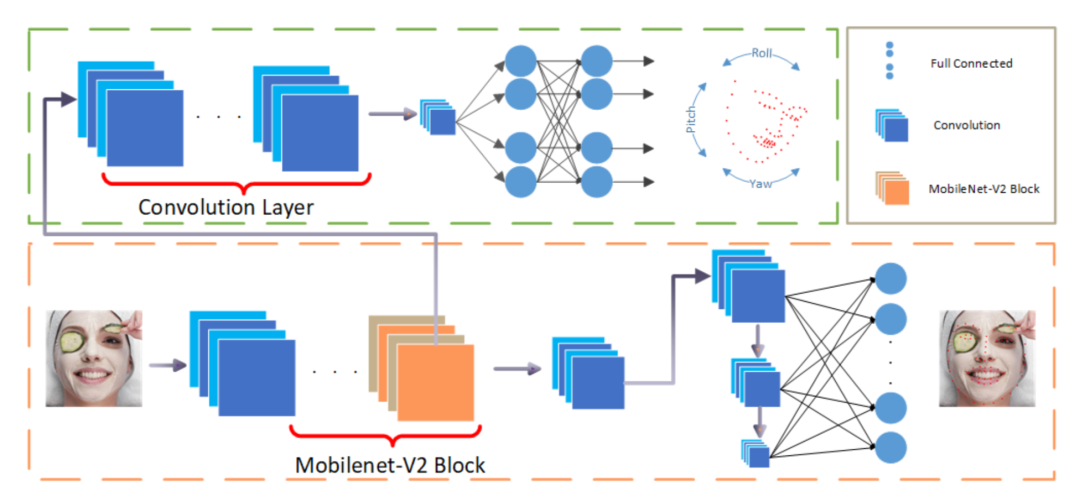
3、深度学习关键点检测方法


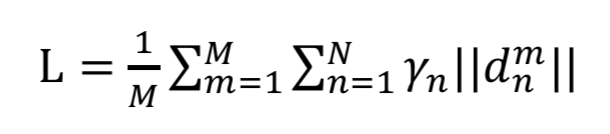
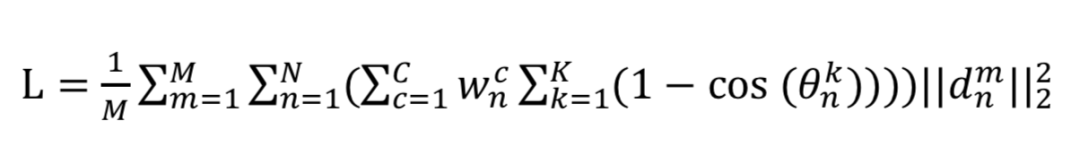
4、小结
极市赠书

本书由浅入深、全面系统地介绍人脸图像的各个研究方向和应用场景,包括但不限于基于深度学习的各个方向的核心技术。本书理论体系完备,讲解时提供大量实例,可供读者实战演练。本书涵盖的内容非常广泛,从基本的人脸数据集发展历史和人脸检测开始,分别讲述在此基础上进行的人脸图像处理的相关技术与应用,涉及身份识别、安全认证、人机交互和娱乐社交等领域。本书共11章,涵盖的主要内容有人脸图像与特征基础、深度学习基础、人脸数据集、人脸检测、人脸关键点检测、人脸识别、人脸属性识别、人脸属性分割、人脸美颜与美妆、人脸三维重建及人脸属性编辑。本书适合计算机视觉领域的初学者及所有在人脸图像算法领域想要有所提高的工程技术人员、学生和教职工阅读。读者既可以将本书作为核心算法书籍学习理论知识,也可以将本书作为工程参考手册查阅相关技术。
领取方式
点击右下角“在看”,并关注极市平台公众号,回复“赠书”,即可获取抽奖二维码。8月12日上午10点,极市将准时开奖。没有被抽到的开发者可以通过扫描下方二维码进行购买。
51篇最新CV领域综述论文速递!涵盖14个方向:目标检测/图像分割/医学影像/人脸识别等方向 让特征感受野更灵活,腾讯优图提出非对称卡通人脸检测,推理速度仅50ms 姿态估计:人体骨骼关键点检测综述(2016-2020)

评论