
一文全览系列 | 自动驾驶感知的多传感器融合算法综述

Paper: https://arxiv.org/pdf/2202.02703.pdf
导读
本文讨论了自动驾驶系统感知中的多模态融合问题。尽管这是一个很重要的任务,但由于原始数据的噪声、信息的未充分利用以及多模态传感器的不对齐等问题,达到较高性能并不容易。本文进行了一次文献综述,分析了超50篇利用激光雷达和摄像头等传感器的论文,试图解决自动驾驶中的目标检测和语义分割任务。与传统的融合方法不同,我们提出了一种新的分类方法,将融合模型划分为两个主类和四个次类,并对当前的融合方法进行了深入的研究,并对未来的研究机会进行了深入探讨。 总而言之,我们希望为自动驾驶感知任务中的多模态融合方法提供一个新的分类体系,并引发对未来基于融合技术的思考。
本文的组织结构如下:
引言:简要讲述了之前文章的融合方法分类固化以及本文提出的新颖分类方法; 感知和任务比赛:简要介绍了自动驾驶中的感知任务,包括但不限于目标检测、语义分割,以及几个广泛使用的开放数据集和基准; LiDAR 和图像的表示:总结了作为下游模型输入的所有数据格式。与图像部分不同,激光雷达部分的输入格式可能因为输入而变化,包括不同的特征设计和表示; 融合方法:详细描述了融合方法论,相比传统方法,这是一种将所有当前工作分为两个主类和四个次类的创新和清晰的分类体系; 多模态融合机会:深入分析了一些剩余问题、研究机会和可能的未来工作,关于自动驾驶中的多模态传感器融合,我们可以轻松地感知到一些有见地的尝试,但仍然有待解决; 总结:对全文内容的总结。
后续本公众号将会持续更新自动驾驶系列文章,详细介绍自动驾驶相关的技术方案实现以及相关的应用,欢迎大家多多关注!
引言
感知是自动驾驶汽车的基本模块[1]。该任务包括但不限于2D/3D目标检测,语义分割,深度补全和预测,这些任务都依赖于安装在车辆上的传感器来采样环境中的原始数据。目前大多数现有的方法[2]分别对由激光雷达和摄像机捕获的点云和图像数据进行感知任务,并取得了较好的成果。
然而,单模态数据的感知存在固有的缺陷[3]。例如,摄像机数据主要在前视低位捕获[4]。在更复杂的场景中,物体可能被遮挡,给目标检测和语义分割带来严峻挑战。此外,由于机械结构的限制,激光雷达在不同距离上具有不同的分辨率[5],并且容易受到极端天气(如雾天和大雨)的影响。尽管两种模态的数据在单独使用时在各个领域都有优秀表现,但激光雷达和摄像机的互补性使得它们的结合可以在感知方面取得更好的性能[6]。
近年来,自动驾驶中感知任务的多模态融合方法迅速发展[7],从更先进的跨模态特征表示和不同模态下更可靠的传感器到更复杂和更强大的深度学习模型以及多模态融合技术。然而,只有少数文献综述[8]专注于多模态融合方法本身的方法论,大多数文献遵循将它们分为早期融合、深度融合和后期融合三个主要类别的传统规则,关注深度学习模型中融合特征的阶段,无论是在 数据级别、特征级别还是对象级别。首先,这样的分类法不能清楚定义每个层次中的特征表示。其次,它表明激光雷达和摄像机两个部分在处理过程中始终是对称的,混淆了在激光雷达部分融合对象级特征和在摄像机部分融合数据级特征的情况[9]。综上所述,传统的分类法可能直观但是简单化,难以总结越来越多新兴的多模态融合方法,阻碍了研究人员从系统角度研究和分析它们。
本文将对关于自动驾驶中多模态传感器融合论文进行简要综述。我们提出了一种新颖的分类方法,将超过50篇相关论文按照融合阶段的角度划分为两个主类和四个次类。这项工作的主要贡献可以总结如下:
我们提出了一种自动驾驶感知任务中多模态融合方法的创新分类体系,包括两个主类:强融合和弱融合,以及强融合中的四个次类:早期融合,深度融合,后期融合和非对称融合,这些类别都是通过激光雷达和摄像机的特征表示明确定义的。 我们对激光雷达和摄像机部分的数据格式和表示进行了深入研究,讨论了它们的不同特征。 我们详细分析了融合的剩余问题,并介绍了关于多模态传感器融合方法的几个潜在研究方向,这些可能会启发未来的研究工作。
感知任务和比赛
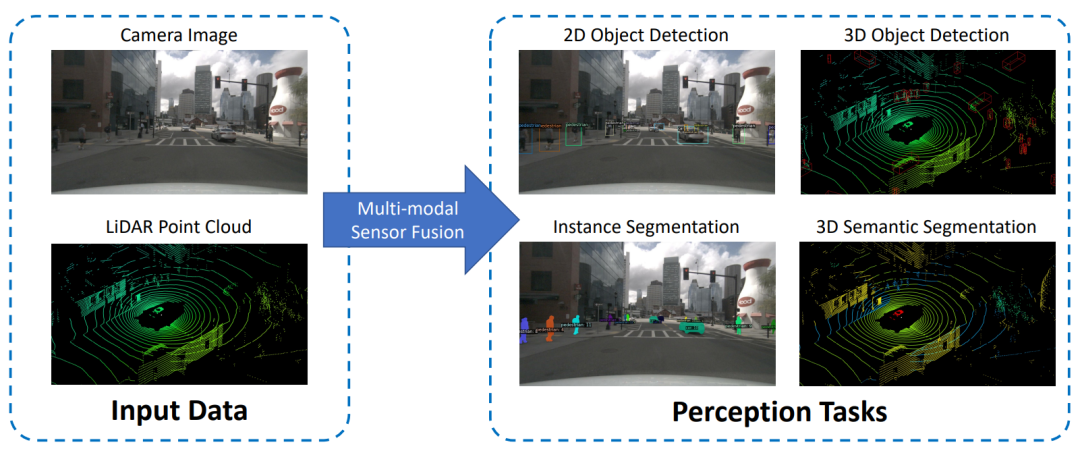
在这一部分中,我们首先将介绍自动驾驶中常见的感知任务。此外,我们还要简要介绍一些广泛使用的开放基准数据集。
多传感器融合感知任务
总的来说,自动驾驶感知任务包括了目标检测、语义分割、深度补全和预测等[10]。在此,我们主要关注前两项任务作为最集中的研究领域之一。此外,它们还涵盖诸如检测障碍物、交通灯、交通标志等任务,以及车道或可行驶空间的分割。我们还简要介绍了其余的任务。自动驾驶感知任务的概述如图1所示。
目标检测
自动驾驶汽车理解周围环境是至关重要的。自动驾驶车辆需要检测道路上的静止和移动障碍物以保证安全行驶。目标检测是传统的计算机视觉任务,在自动驾驶系统中广泛使用[11]。研究人员建立了这样的框架进行障碍物检测(汽车、行人、骑车人等)、交通灯检测、交通标志检测等。
一般来说,目标检测使用由参数表示的矩形或立方体来紧密限制预定义类别的实例,如汽车或行人,需要在定位和分类方面都做到出色。由于缺少深度通道,2D目标检测通常表示为(,,,,),而3D目标检测边界框通常表示为(,,,,,,,)。
语义分割
除了目标检测之外,许多自动驾驶感知任务可以被表述为语义分割。例如,空间检测[12]是许多自动驾驶系统的基本模块,它将地面像素分类为可行驶和不可行驶部分。一些车道检测[13]方法也使用多类语义分割掩模来表示道路上的不同车道。
语义分割的本质是将输入数据的基本组件,如像素和3D点,聚类到包含特定语义信息的多个区域。具体来说,语义分割是指给定一组数据,如图像像素={,,,}或LiDAR 3D点云={,,,}和一组预定义的候选标签={,,,,},我们使用模型为每个像素或点分配选定的k个语义标签之一或所有的概率。
其他感知任务
除了上面提到的目标检测和语义分割之外,自动驾驶感知任务还包括物体分类、深度补全和预测。物体分类主要解决了通过模型给出点云和图像确定类别的问题。深度补全和预测任务主要关注预测给定LiDAR点云和图像数据的每个像素距离观察者的距离。尽管这些任务可能受益于多模态信息,但在这些领域中并没有广泛讨论融合模块。因此,我们在本文中选择省略这两个任务。
尽管本文中没有涵盖其他许多感知任务,但大多数可以视为目标检测或语义分割的相关任务。因此,我们在本文中主要关注这两项研究工作。
开放比赛和数据集
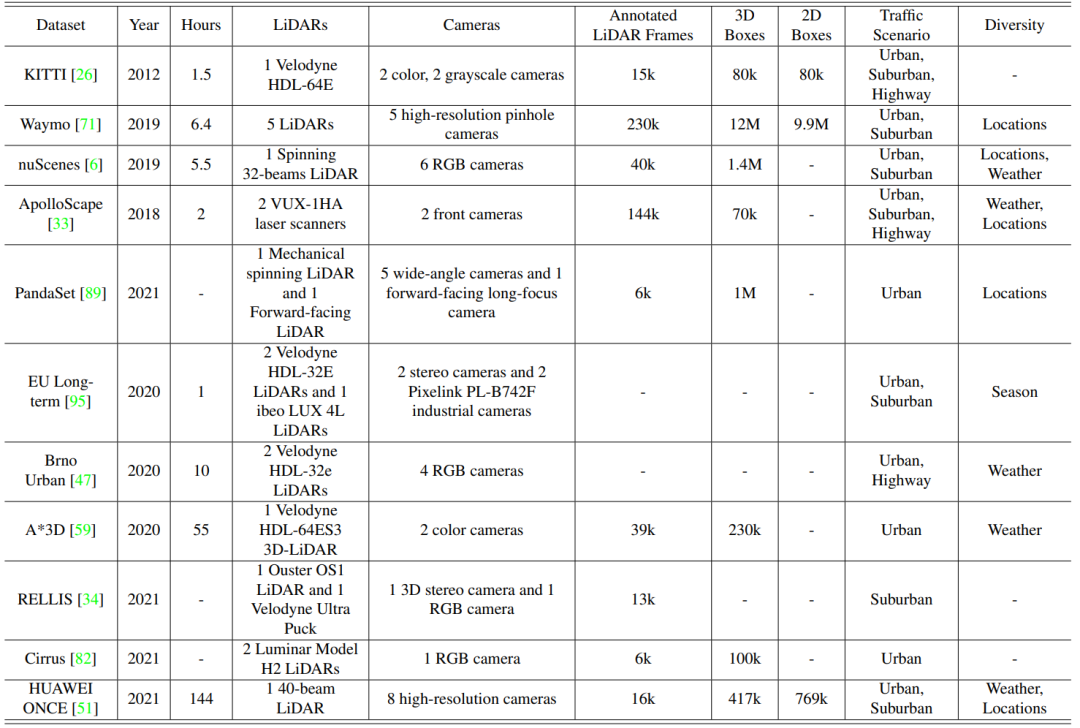
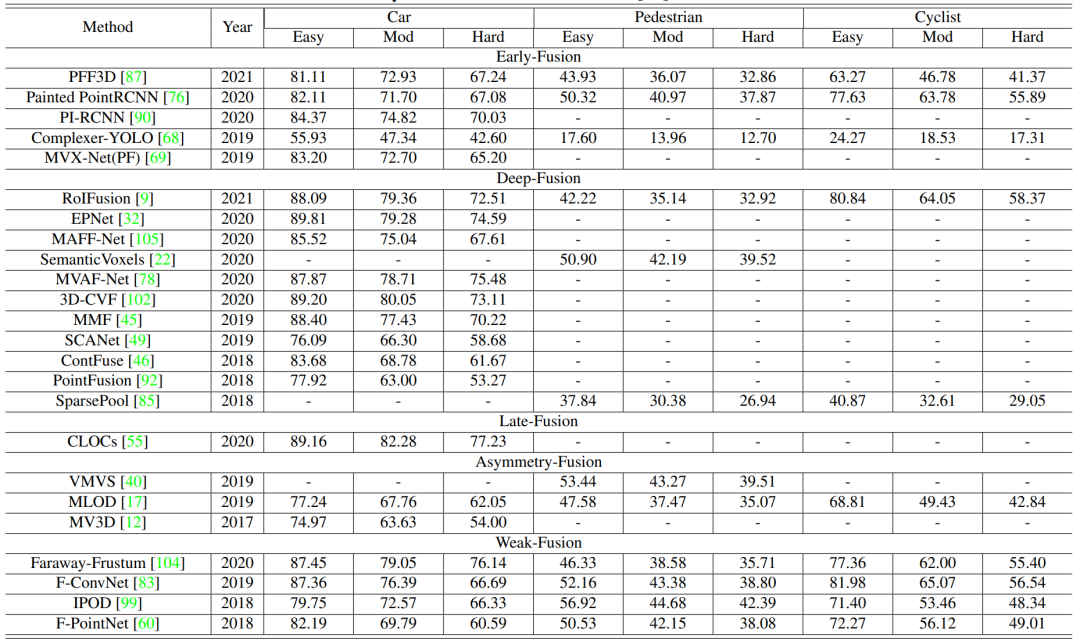
超过十个数据集[14]与自动驾驶感知相关。然而,只有三个数据集常用,包括KITTI、Waymo和nuScenes[15]。在这里,我们在表1中总结了这些数据集的详细特征。
KITTI开放基准数据集是自动驾驶中最常用的目标检测数据集之一,包含2D、3D和鸟瞰视图检测任务。配备四个高分辨率视频摄像机、一个Velodyne激光扫描仪和一个最先进的定位系统,KITTI收集了7481张训练图像和7518张测试图像以及相应的点云。其中三种目标被标记为汽车、行人和骑车者,具有超过20万个3D目标注释,分为三类:简单、中等和困难的检测难度。对于KITTI目标检测任务,平均精度通常用于模型性能比较。此外,平均方向相似度也用于评估联合检测目标和估计其3D方向的性能。
作为常用于自动驾驶基准的最大开放数据集之一,Waymo开放数据集由五个LiDAR传感器和五个高分辨率针孔相机收集。具体来说,有79个场景用于训练,202个用于验证,150个场景用于测试。每个场景持续20秒,注释在车辆、骑车者和行人中。对于评估3D目标检测任务,Waymo包括四个指标:AP/L1、APH/L1、AP/L2、APH/L2。更具体地说,AP和APH表示两种不同的性能测量,而L1和L2包含具有不同检测难度的对象。至于APH,它与AP类似,但是会经过航向精度加权计算。
NuScenes开放数据集包含1000个驾驶场景,其中700个用于训练,150个用于验证,150个用于测试。配备了摄像机、LiDAR和雷达传感器,nuScenes在每个关键帧中注释了23种目标类别,包括不同类型的车辆、行人和其他。NuScenes使用AP、TP进行检测性能评估。此外,它提出了一个创新的标量分数作为nuScenes检测分数(NDS),由AP、TP进行计算,分离不同的错误类型。
LiDAR 和图像的表示
本节主要讨论了深度学习模型在处理LiDAR和图像数据时的预处理操作。首先介绍了LiDAR和图像数据的表示方式,然后讨论了数据融合的方法和模型。在图像分支中,大多数现有方法将原始数据的格式保留在下游模块的输入中。然而,LiDAR分支高度依赖数据格式,这强调了不同的特征并且对下游模型设计有重大影响。因此,本文总结了三种点云数据格式:基于点、基于体素和基于2D映射,它们适用于不同的深度学习模型。
图像表示
在2D或3D物体检测和语义分割任务中,单目摄像机是最常用的数据采集传感器,它提供了丰富的纹理信息,对于每个图像像素,它具有多个通道的特征向量={, , , ...},通常包含红色,蓝色,绿色通道或其他手动设计的特征,如灰度通道。
然而,直接在3D空间中检测物体是非常具有挑战性的,因为深度信息有限,很难由单目摄像机提取。因此,许多工作使用双目或立体摄像机系统通过空间和时间空间来利用额外的3D物体检测信息,如深度估计,光流等。对于极端驾驶环境,如晚上或雾天,一些工作还使用红外摄像机来提高鲁棒性。
基于点的点云表示
对于3D感知传感器,LiDAR使用激光系统扫描环境并生成点云。它在世界坐标系中采样点,表示激光射线和不透明表面的交点。一般来说,大多数LiDAR的原始数据是四元数格式,其中表示每个点的反射率。不同的纹理导致不同的反射率,这能为模型提供了额外的信息。
为了整合LiDAR数据,一些方法直接使用点进行特征提取[16]。然而,点的四元数表示存在冗余或速度缺陷。因此,许多研究人员[17]试图将点云转换为体素或2D投影,然后将其馈送到下游模块中。
基于体素的点云表示
一些工作通过将3D空间离散化为3D体素来使用3D CNN,表示为={,,...},其中每个表示一个特征向量={,}。表示体素化立方体的中心,而表示基于统计的局部信息。
局部密度是一种常用的特征,它由局部体素中的3D点的数量定义[18]。局部偏移通常定义为点的实际坐标和局部体素中心之间的偏移。还有一些其他特征包括局部线性和局部曲率[19]。
最近的工作可能考虑更合理的离散化方式,如基于圆柱体的体素化,但与上面提到的基于点的点云表示不同,基于体素的点云表示显着减少了非结构化点云的冗余[20]。此外,能够使用3D稀疏卷积技术,感知任务不仅可以获得更快的训练速度,而且可以获得更高的准确性。
基于2D映射的点云表示
有些工作不是提出新的网络结构,而是利用复杂的2D CNN骨干来编码点云。具体来说,他们试图将LiDAR数据投影到图像空间中,作为两种常见类型,包括相机平面图(CPM)和鸟瞰图(BEV)[21]。
CPM可以通过外参标定来获得,将每个3D点投影到相机坐标系中。由于CPM具有与相机图像相同的格式,它们可以自然地融合,使用CPM作为额外通道。然而,由于投影后LiDAR的分辨率较低,CPM中许多像素的特征已经损坏。因此,已经提出了一些方法来上采样特征图,而其他方法则采用留空的方式[22]。
与直接将LiDAR信息投影到前视图图像空间的CPM不同,BEV映射提供了场景的俯视图。它被检测和定位任务使用的原因有两点。首先,与安装在挡风玻璃后面的相机不同,大多数LiDAR都在车顶上,遮挡较少。其次,在BEV中,所有物体都放在地面上,模型可以在不扭曲长度和宽度的情况下生成预测。BEV组件可能会不一致,一些是直接从高度,密度或强度转换为基于点或基于体素的特征[23],而其他则通过特征提取器模块在柱子中学习LiDAR信息的特征。
融合方法
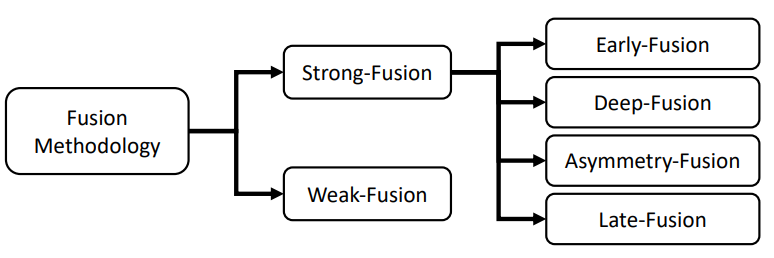
在本节中,我们将回顾LiDAR-相机数据融合的不同方法。从传统分类的角度来看,所有多模态数据融合方法都可以方便地分为三种范式,包括数据级融合(早期融合),特征级融合(深度融合)和对象级融合(后期融合)。
数据级融合或早期融合方法通过空间对齐直接融合不同模态的原始传感器数据。特征级融合或深度融合方法通过连接或元素逐位乘法在特征空间中混合跨模态数据。对象级融合方法结合每种模态中模型的预测结果并做出最终决策。
然而,最近的工作[24]不能轻易地归类为这三类。因此,本文提出了一种新的分类法,将所有融合方法划分为强融合和弱融合,我们将在详细阐述。我们在图2中展示了它们之间的关系。
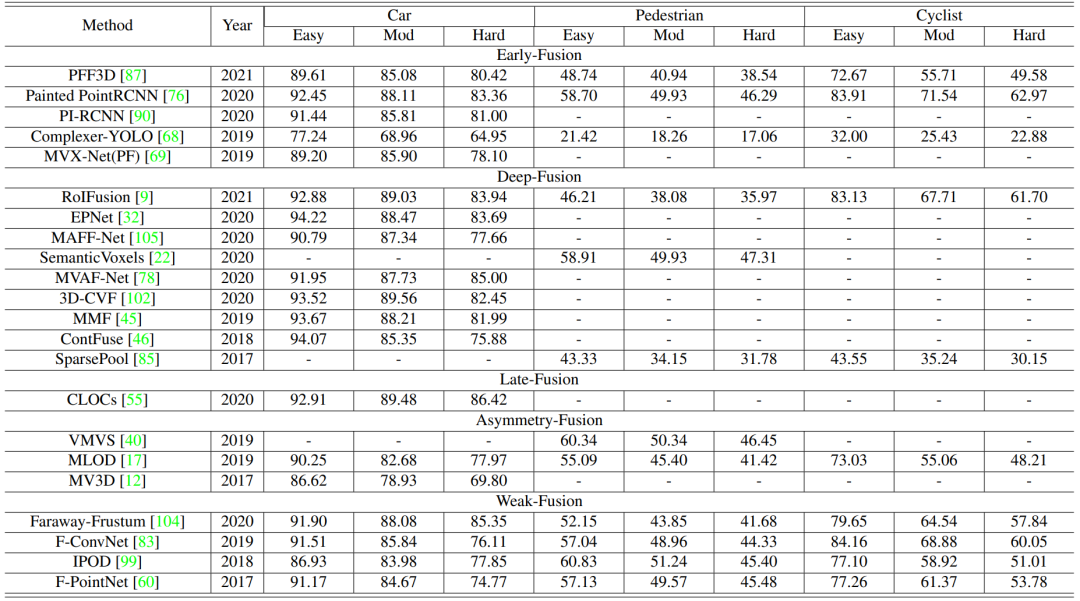
对于性能比较,我们主要关注KITTI基准中的两个主要任务,即3D检测和鸟瞰图目标检测。表2和表3分别在KITTI测试数据集的BEV和3D设置上呈现了最近多模态融合方法的实验结果。
强融合
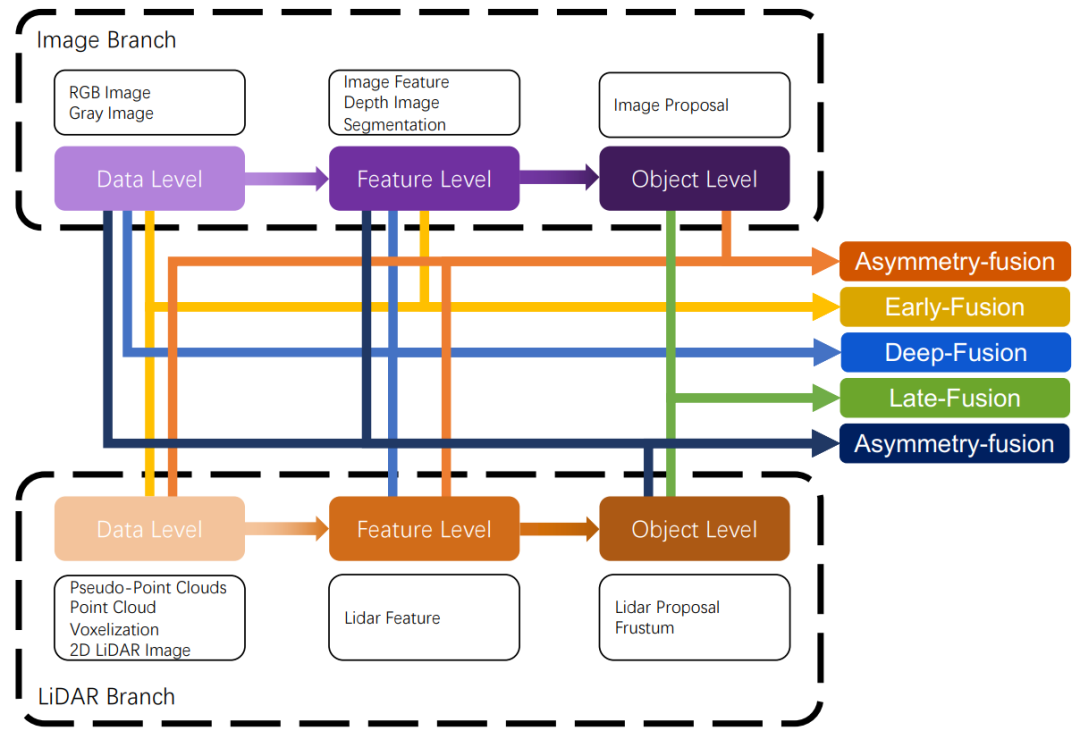
我们将强融合划分为四类,即早期融合、深度融合、后期融合和非对称融合,通过LiDAR和相机数据表示的不同组合阶段。作为最研究的融合方法,强融合在近年来取得了许多杰出成就[25]。从图3中的概述可以很容易地发现,强融合中的每个次类高度依赖于LiDAR点云,而不是相机数据。接下来我们将进行具体讨论。
早期融合
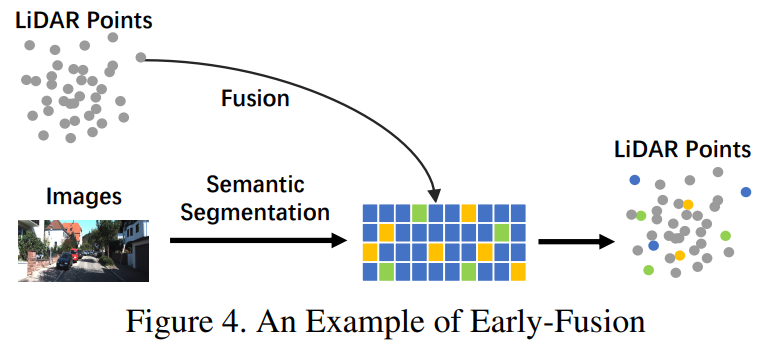
与数据级融合的传统定义不同,早期融合是一种在每种模态中通过空间对齐和投影直接融合数据的方法,早期融合在数据级别融合LiDAR数据和在数据级别或特征级别融合相机数据。早期融合示意图如图4所示。
在上述LiDAR分支中,点云可以以反射率为3D点、体素化张量、前视图/距离视图/鸟瞰图、以及伪点云的形式使用。尽管这些数据具有不同的固有特征,这些特征与后面的LiDAR后端高度相关,但这些数据大多通过基于规则的处理而生成,除了伪点云[26]。此外,这些LiDAR数据表示形式都可以直接可视化,因为在此阶段的数据仍然具有可解释性。
对于图像路径,严格的数据级定义应该仅包含RGB或灰度数据,其缺乏普适性和合理性。与早期融合的传统定义相比,我们在此将相机数据扩大到数据级和特征级数据。值得注意的是,我们将图像分支中的语义分割任务结果作为特征级表示,因为这些“对象级”特征与整个任务的最终对象级不同。
PI-RCNN[27]将图像分支中的语义特征与原始LiDAR点云融合在一起,其在目标检测任务中获得了更好的性能。Complexer-yolo[28]和SegVoxelNet[29]也利用语义特征,但与上述方法不同,它将原始LiDAR点云预处理为体素化张量,以进一步利用更先进的LiDAR后端信息。Sensor Fusion[30]将3D LiDAR点云转换为2D图像,并在图像分支中融合特征级表示,利用成熟的CNN技术实现更好的性能。Fast and Accurate 3D Object Detection[31]将原始RGB像素与体素化张量融合在一起,而Kda3d[26]则将从图像分支生成的伪点云与LiDAR分支中的原始点云直接组合在一起,完成目标检测任务。
基于VoxelNet的MVX-Net[32]提出了一种点融合方法,该方法直接将对应像素的图像特征向量附加到体素化向量上。PointFusion[33]提出了密集融合,即将每个原始点与图像分支中的全局特征相附加。Multimodal CNN Pedestrian Classification[34]专注于使用CNN进行2D行人检测。作为早期融合,它在输入CNN之前直接融合不同分支。MAFF-Net[35]提出了一种名为点关注融合的融合方法,该方法将图像特征融合到LiDAR点云中的体素化张量中。
深度融合
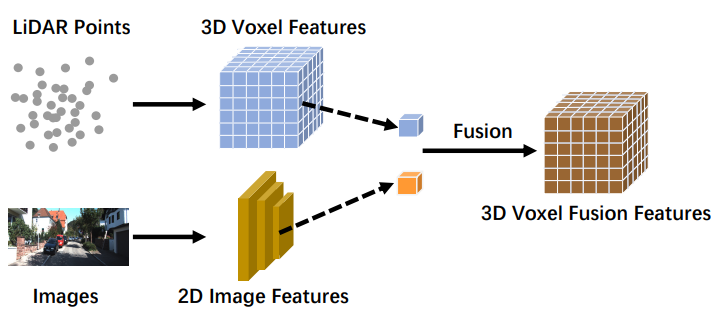
深度融合方法在LiDAR分支的特征层级上融合跨模态数据,但对图像分支进行数据层级和特征层级融合。例如,一些方法使用特征提取器分别获取LiDAR点云和相机图像的嵌入(embedding)表示,并通过一系列下游模块融合两种模态的特征[36]。然而,与其他强融合方法不同,深度融合有时以级联方式融合特征[37],其既利用原始信息,又利用高层语义信息。深度融合示意图如图5所示。
Pointfusion[33]提出了全局融合,将全局LiDAR特征与图像分支中的全局特征进行像素级相加。MVX-Net[32]提出了体素融合方法,该方法将ROI池化图像特征向量附加到LiDAR点云中每个体素的密集特征向量。MAFF-Net[35]提出了另一种名为密集关注融合的方法,该方法融合了多个分支的伪图像。SCANet[38]提出了两种深度融合方法。EPNet[36]是一种深度LIDAR-Image融合,估算相应图像特征的重要性以减少噪声影响。[3]展示了一种极端天气中的多模态数据集,并以深度融合的方式融合了每个分支,大大提高了自动驾驶模型的鲁棒性。
后期融合
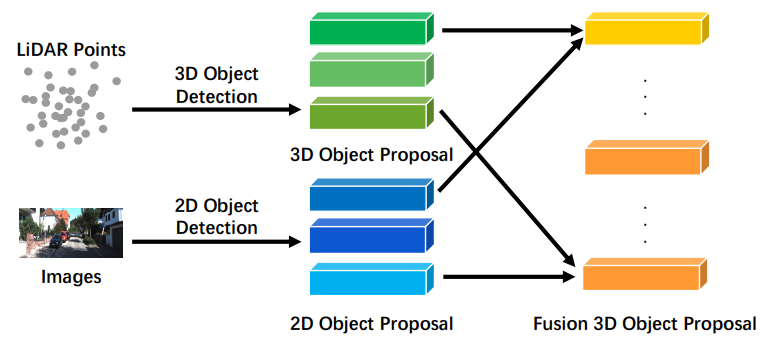
后期融合,也叫对象级融合,指的是融合每种模态管道结果的方法。例如,一些后期融合方法利用LiDAR点云分支和相机图像分支的输出,并基于两种模态的结果进行最终预测[39]。注意,这两个分支建议应该具有与最终结果相同的数据格式,但质量、数量和精度不同。后期融合可以被视为一种集成方法,利用多模态信息来优化最终结果。后期融合示意图如图6所示。如上所述,[39]利用后期融合来第二次细化每个3D区域提议的分数,结合图像分支中的2D提议和LiDAR分支中的3D提议。此外,对于每个重叠区域,它使用了置信度分数、距离和IoU等统计特征进行去重。Multimodal vehicle detection[40]专注于2D目标检测,通过结合了两个分支的提议,以及置信度分数等特征,模型输出最终的IoU分数。Road Detection through CRF[41]、multi-modal crf model[42]通过结合分割结果来解决道路检测问题。如[34]中的后期融合,它将同一3D检测提议的不同分支的分数计算出一个最终分数。
非对称融合
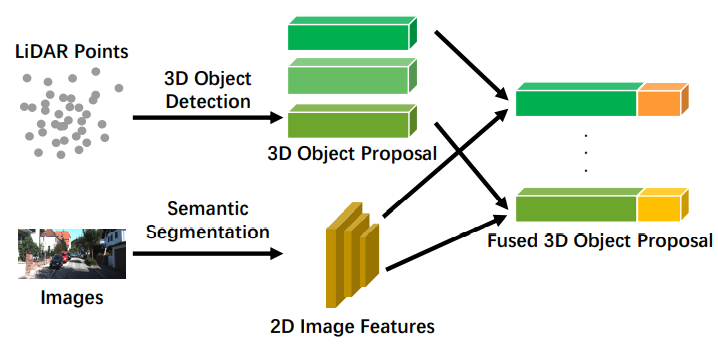
除了早期融合、深度融合和后期融合之外,一些方法用不同的方式来处理跨模态分支,因此我们定义了从一个分支融合对象级信息,而从其他分支融合数据级或特征级信息的不对称融合方法。与强融合中的其他方法不同,非对称融合中至少有一个分支占主导地位,而其他分支提供辅助信息来进行最终任务。非对称融合示意图如图7所示。特别是与后期融合相比,尽管它们可能使用[39]提取相同的特征,但非对称融合只有一个分支的提议,而后期融合有所有分支的提议。
这种融合方法是合理的,因为使用卷积神经网络在相机数据上的表现非常出色,它能在点云中过滤语义上无用的点,并在锥体视角下提升3D LiDAR主干的性能,如[9]。它提取原始点云中的锥体,并配合相应的像素RGB信息输出3D边界框的参数。然而,一些工作另辟蹊径,使用LiDAR主干来指导多视图风格的2D主干,并获得更高的精度。virtual multi-view synthesis[43]专注于基于3D检测提议提取的多视图图像的行人检测,进一步使用CNN来细化先前的提议。[23]和MLOD[44]使用其他分支中的ROI特征来细化仅由LiDAR分支预测的3D提议。Pose-rcnn[45]专注于2D检测,利用LiDAR分支中的3D区域提议,并重新投影到2D提议,再结合图像特征进行进一步细化。3D Object Proposals using Stereo Imagery[46]通过统计和基于规则的信息提出3D潜在边界框。结合图像特征,它输出最终的3D提议。LiDAR guided model[47]专注于小物体检测,通过特别收集的数据集实现,它本质上是一个2D语义分割任务,结合LiDAR的提议和原始RGB图像来输出最终结果。
弱融合
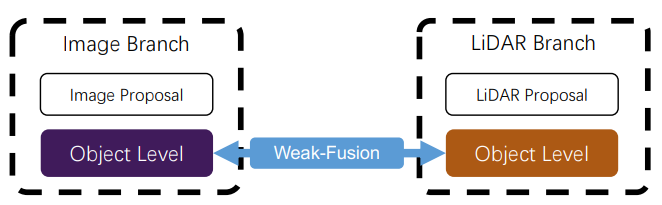
与强融合不同,弱融合方法不能直接从多模态分支中融合数据/特征/对象,而是以其他方式操作数据。基于弱融合的方法通常使用基于规则的方法来利用一种模态的数据作为监督信号来指导另一种模态的交互。图8展示了弱融合模式的基本框架。例如,图像分支中CNN的2D提议可能导致原始LiDAR点云中的出现锥体。然而,与上面提到的非对称融合结合图像特征不同,弱融合直接将这些选定的原始LiDAR点云输入到LiDAR主干中输出最终结果[48]。
其他弱融合方法[49]在每次仅选择两个分支中的一个模型来预测最终结果,然后使用强化学习策略来优化2D目标的实时检测性能。在General Pipeline[50]中,通过图像分支中的2D检测提议生成多个3D框提议,然后模型输出具有检测分数的最终3D检测框。RoarNet[51]使用图像预测2D边界框和3D姿态参数,并进一步使用对应区域中的LiDAR点云进行细化。
其他融合方法
有些工作不能简单地被定义为上面提到的融合类型,因为它们在整个模型框架中拥有多种融合方法,如深度融合和后期融合的结合[22],而[[25]]]()则将早期融合和深度融合结合在一起。这些方法在模型设计视图上存在冗余,这不是融合模块的主流。
多模态融合的机会
自动驾驶中感知任务的多模态融合方法近年来取得了快速的进展,从更高级的特征表示到更复杂的深度学习模型[7,8]。然而,仍有一些问题需要解决。我们在这里概括了未来要做的一些关键和必要的工作,分为以下几个方面。
更多的先进融合方法
目前的融合模型存在对齐问题和信息丢失问题[52]。此外,平面融合操作[53]也阻碍了感知任务性能的进一步提高。我们将它们归纳为两个方面:像素不对齐和信息丢失,更合理的融合操作。
像素不对齐和信息丢失
相机和激光雷达的本质和外在是截然不同的。两种模态的数据都需要在新的坐标系下重新组织。传统的早期和深度融合方法使用外在校准矩阵将所有激光雷达点直接投影到对应的像素或反之[6],[30],[32]。然而,由于传感器噪声,这种像素的对齐并不够准确。因此,可以看出,除了这种严格对应关系之外,一些利用周围信息作为补充的工作[27]可以取得更好的性能。
此外,在输入和特征空间转换过程中还存在一些其他信息丢失。通常,维度降维操作将不可避免地导致大量信息丢失,例如,将3D激光雷达点云映射到2D BEV图像。因此,通过将两种模态数据映射到专门设计用于融合的高维表示中,未来的工作可以在信息损失较少的情况下有效地利用原始数据。
更多合理的融合操作
目前的研究工作使用直观的方法融合跨模态数据,如连接和元素对元素相乘[32],[25]。这些简单的操作可能无法将具有大分布差异的数据融合起来,并因此难以缩小两种模态之间的语义差距。一些工作试图使用更加精心设计的级联结构来融合数据并提高性能[23,37]。在未来的研究中可以加大探索能融合具有不同特性的特征,如双线性映射[54]等机制。
多源信息利用
前视图单帧是自动驾驶感知任务的典型场景。然而,大多数框架在没有经过精心设计的辅助任务的情况下利用有限信息,以进一步理解驾驶场景。我们将它们归纳为更多潜在有用信息和自监督表示学习。
更多潜在有用信息
现有的方法[8]缺乏有效地使用来自多维度和多源的信息。其中大多数关注前视图多模态数据的单帧。因此其他有意义的信息没有得到充分利用,如语义,空间和场景上下文信息。
一些模型[6,27,53]尝试使用从图像语义分割任务中获得的结果作为附加特征,而其他模型可能利用神经网络主干的中间层特征[37]。在自动驾驶场景中,许多显式语义信息的下游任务可显著提高目标检测任务的性能。例如,车道检测可以直观地为检测车道间的车辆提供额外帮助,语义分割结果可以提高目标检测性能[6,27,53]。
因此,未来的研究可以通过各种下游任务(如检测车道,交通灯和标志)共同构建城市场景语义理解框架,以提升感知任务性能。
此外,当前的感知任务主要依赖于单帧,忽略了时间信息。最近基于LiDAR的方法Offboard 3d[55]结合了一系列帧来提高性能。时间序列信息包含序列化的监督信号,可以提供比使用单帧的方法更稳健的结果。
因此,未来的工作可能会更深入地利用时间、上下文和空间信息来对连续帧进行创新的模型设计。
自监督表示学习
互相监督的信号在从同一实际场景中采样的跨模态数据之间自然存在,但视角不同。然而,目前的方法无法挖掘每种模态之间的相关性,缺乏对数据的深入理解。在未来,研究可以集中在如何使用多模态数据进行自我监督学习,包括预训练,微调或对比学习。通过实施这些最先进的机制,融合模型将能对数据有更深入理解,并取得更好的结果,这在其他领域已经显示出一些有前途的迹象,在自动驾驶感知中则是一片空白[56]。
感知传感器中的内在问题
域偏差和分辨率与真实世界场景和传感器高度相关。这些意想不到的缺陷阻碍了自动驾驶深度学习模型的大规模训练和实施,需要在未来工作中解决。
数据域偏差
在自动驾驶感知场景中,不同传感器提取的原始数据伴随着严重的域相关特征。不同的摄像系统有它们的光学性质,而LiDAR可能因机械LiDAR到固态LiDAR而不同。更重要的是,数据本身可能存在域偏差,如天气,季节或位置,即使它是由同一传感器捕获的。结果,检测模型无法平稳地适应新场景。这些缺陷阻止了大规模数据集的收集和原始训练数据的可重用性。因此,在未来工作中找到消除域偏差并自适应地集成不同数据源的方法是至关重要的。
数据分辨率的冲突
不同形态的传感器通常具有不同的分辨率[57]。例如,LiDAR的空间密度明显低于图像。由于无法找出完美的对应关系,因此无论采用哪种投影方法,都会丢失一些信息。这可能导致模型被特定模态的数据所主导,无论是由于特征向量的不同分辨率还是原始信息的不平衡。因此,未来的工作可以探索一种与不同空间分辨率传感器兼容的新数据表示系统。
总结
在本文中,我们回顾了50多篇有关自动驾驶感知任务的多模态传感器融合的相关论文。具体来说,我们首先提出了一种从融合角度更合理的分类方式来对这些论文进行分类。然后我们对LiDAR和相机的数据格式和表示进行了深入的分析,并描述了它们不同的特点。最后,我们对多模态传感器融合的剩余问题进行了详细分析,并介绍了几种新的可能方向,这可能会启发未来的研究工作。
References
the kitti vision benchmark suite: https://ieeexplore.ieee.org/document/6248074
[2]Deep learning for lidar point clouds in autonomous driving: https://ieeexplore.ieee.org/document/9173706
[3]Deep multimodal sensor fusion in unseen adverse weather: https://arxiv.org/abs/1902.08913
[4]3D-CVF: https://arxiv.org/abs/2004.12636
[5]X-view: https://arxiv.org/abs/2103.13001
[6]PointPainting: https://arxiv.org/abs/1911.10150
[7]Deep Learning for Image and Point Cloud Fusion in Autonomous Driving: https://arxiv.org/abs/2004.05224
[8]Multi-Modal 3D Object Detection in Autonomous Driving: https://arxiv.org/abs/2106.12735
[9]3D Object Detection Using Scale Invariant and Feature Reweighting Networks: https://arxiv.org/abs/1901.02237
[10]Waymo Open Dataset: https://arxiv.org/abs/1912.04838
[11]PointNet: https://arxiv.org/abs/1612.00593
[12]An Integrated Framework for Autonomous Driving: https://ieeexplore.ieee.org/document/8904020
[13]Road curb and lanes detection for autonomous driving on urban scenarios: https://ieeexplore.ieee.org/document/6957993
[14]Argoverse: 3D Tracking and Forecasting with Rich Maps: https://arxiv.org/abs/1911.02620
[15]nuScenes: A multimodal dataset for autonomous driving: https://arxiv.org/abs/1903.11027
[16]PointNet++: https://arxiv.org/abs/1706.02413
[17]Voxel R-CNN: https://arxiv.org/abs/2012.15712
[18]Fast ground filtering for TLS data via Scanline Density Analysis: https://www.sciencedirect.com/science/article/abs/pii/S0924271616306086
[19]Point cloud library: https://pointclouds.org/assets/pdf/pcl_icra2011.pdf
[20]PointPillars: https://arxiv.org/abs/1812.05784
[21]PIXOR: https://arxiv.org/abs/1902.06326
[22]Joint 3D Proposal Generation and Object Detection from View Aggregation: https://arxiv.org/abs/1712.02294
[23]Multi-View 3D Object Detection Network for Autonomous Driving: https://arxiv.org/abs/1611.07759
[24]Faraway-Frustum: https://arxiv.org/abs/2011.01404
[25]PointAugmenting: https://vision.sjtu.edu.cn/files/cvpr21_pointaugmenting.pdf
[26]Key-Point Densification and Multi-Attention Guidance for 3D Object Detection: https://www.mdpi.com/2072-4292/12/11/1895
[27]PI-RCNN: https://arxiv.org/abs/1911.06084
[28]Complexer-yolo: https://arxiv.org/abs/1904.07537
[29]SegVoxelNet: https://arxiv.org/abs/2002.05316
[30]Sensor Fusion for Joint 3D Object Detection and Semantic Segmentation: https://arxiv.org/abs/1904.11466
[31]Fast and Accurate 3D Object Detection for Lidar-Camera-Based Autonomous Vehicles Using One Shared Voxel-Based Backbone: https://ieeexplore.ieee.org/document/9340187
[32]MVX-Net: https://arxiv.org/abs/1904.01649
[33]PointFusion: https://arxiv.org/abs/1711.10871
[34]Multimodal CNN Pedestrian Classification: https://ieeexplore.ieee.org/document/8569666
[35]MAFF-Net: https://arxiv.org/abs/2009.10945
[36]EPNet: https://arxiv.org/abs/2007.08856
[37]Deep Continuous Fusion for Multi-Sensor 3D Object Detection: https://arxiv.org/abs/2012.10992
[38]SCANet: https://ieeexplore.ieee.org/document/8682746
[39]CLOCs: https://arxiv.org/abs/2009.00784
[40]Multimodal vehicle detection: https://www.sciencedirect.com/science/article/abs/pii/S0167865517303598
[41]Road Detection through CRF based LiDAR-Camera Fusion: https://ieeexplore.ieee.org/document/8793585
[42]Integrating Dense LiDAR-Camera Road Detection Maps by a Multi-Modal CRF Model: https://ieeexplore.ieee.org/document/8861386
[43]Improving 3D Object Detection for Pedestrians with Virtual Multi-View Synthesis Orientation Estimation: https://arxiv.org/abs/1907.06777
[44]MLOD: https://arxiv.org/pdf/1909.04163.pdf
[45]Pose-rcnn: https://ieeexplore.ieee.org/document/7795763
[46]3D Object Proposals using Stereo Imagery for Accurate Object Class Detection: https://arxiv.org/abs/1608.07711
[47]LiDAR guided Small obstacle Segmentation: https://arxiv.org/abs/2003.05970
[48]Frustum PointNets: https://arxiv.org/abs/1711.08488
[49]Modality-Buffet for Real-Time Object Detection: https://arxiv.org/abs/2011.08726
[50]A General Pipeline for 3D Detection of Vehicles: https://arxiv.org/abs/1803.00387
[51]RoarNet: https://arxiv.org/abs/1811.03818
[52]Cross-modal Matching CNN for Autonomous Driving Sensor Data Monitoring: https://ieeexplore.ieee.org/document/9607579
[53]SEG-VoxelNet: https://ieeexplore.ieee.org/document/8793492
[54]MUTAN: https://arxiv.org/abs/1705.06676
[55]Offboard 3D Object Detection from Point Cloud Sequences: https://arxiv.org/abs/2103.05073
[56]P4Contrast: https://arxiv.org/abs/2012.13089
[57]Domain Transfer for Semantic Segmentation of LiDAR Data using Deep Neural Networks: https://ieeexplore.ieee.org/document/9341508

扫码加入👉「集智书童」交流群
(备注:方向+学校/公司+昵称)




前沿AI视觉感知全栈知识👉「分类、检测、分割、关键点、车道线检测、3D视觉(分割、检测)、多模态、目标跟踪、NerF」
欢迎扫描上方二维码,加入「集智书童-知识星球」,日常分享论文、学习笔记、问题解决方案、部署方案以及全栈式答疑,期待交流!