
数据库索引设计(基础篇)
点击蓝色“有关SQL”关注我哟
加个“星标”,天天与10000人一起快乐成长

索引在数据库中,毋庸置疑扮演了极其重要的角色。
在这篇文章中,我们即将要讨论这些和索引相关的事情:
优化器是如何选择索引的;
应该如何正确的建立索引;
如何判断优化器选择了正确的索引;
如何找出哪些已经不再被使用的索引;
简介:
索引可以帮助查询更快的定位到所需的记录上,从而避免整表扫描。如果索引引用的列,可以完全包含查询所需的字段,这类索引叫做 覆盖索引(convering index),完全不用回读(针对非聚集索引表)便可满足查询需求。一些常规需求,比如排序,分组和 distinct 都可以有效利用索引。
这里有个概念特别要注意,回读。官方给出的正式名称,叫做 bookmark lookup. 在 SQL Server 中,有两种形式的表存在:聚集索引表和堆表(clustered index 和 heap table).为表建立的非聚集索引,叶子节点存储的除了索引值,还有指向原表的 RID(file id + page id + row id)或者聚集索引值。一旦查询使用到了索引,而索引包含的列中,找不到查询需要的列,那么优化器会给出访问原表的方法,即用索引存储的 RID 或者键值,回到原表去读一边。此时的读,被称为回读,用的是随机读(random read), 一次磁头的转动假如就为一条记录,实际上却扫描了一个扇区,由此可见有多么浪费资源。
索引选用机制
B-Tree(Balanced Tree),索引引入它的目的就是为了建立快速查询的结构。索引数据页的叶子节点页,有可能并不是按照逻辑顺序排好序的,因为有碎片冲刷,长时间数据页是被打散了的。此时按照这种页码去扫描,出来的结果肯定是不对的。因此引入 B-Tree, 即确保了索引最终提供正确的逻辑顺序,也加快了速度。
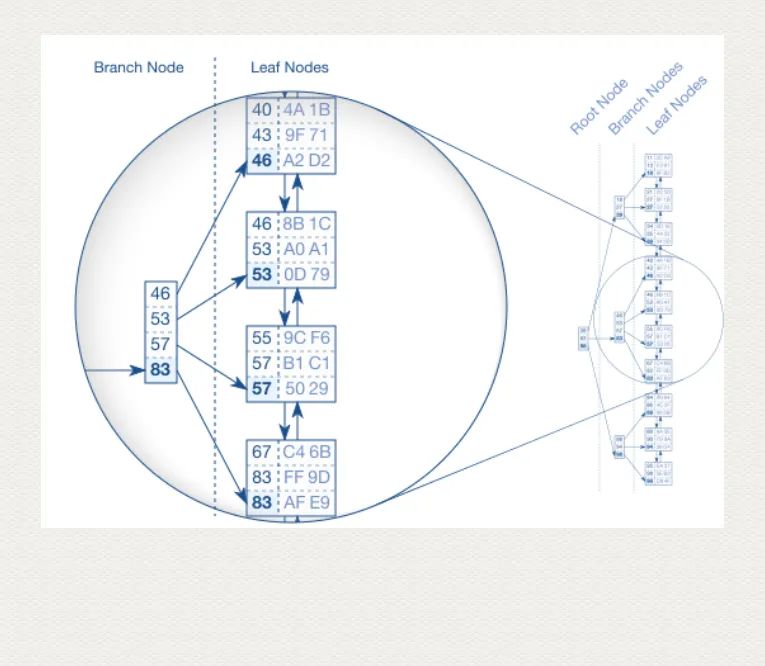
(摘自:https://use-the-index-luke.com/sql/anatomy/the-tree)
上面的 [46,53,57,83]是B-Tree 中的一个节点,此节点上的数据必须保证时时刻刻都按照索引顺序排列,SQL Server 靠锁来维持对这些节点的独占。正因为这些节点保证了数据的顺序性,因此底层索引数据页就不用严格按照索引顺序排列了,由第二底层的数据页指针,指向最终存储的索引数据页,就可以保证逻辑的顺序正确了。
索引的使用,一般是和条件查询绑定的。如果想要发挥索引的作用,就必须用已经被索引的字段做条件查询。比如以下这些判断条件语句,是可以有效利用索引的:
ProductID = 771
UnitPrice<3.975
LastName='Allen'
LastName LIKE 'Brown%'
总结一下,等值比较或不等值比较,包括 =,<,>,<=,>=,!=,!<,!>,BETWEEN 和 In,执行计划都可以安排索引作为数据访问的途径。但以下表达式,却会阻扰索引的使用:
ABS(ProductID)=771
UnitPrice + 1 <3.975
LastName LIKE '%Allen'
UPPER(LastName) = 'Allen'
我们只需比较两者的执行计划,就可以知道,判断条件的字段上加了函数或者表达式,索引就无法再使用了。
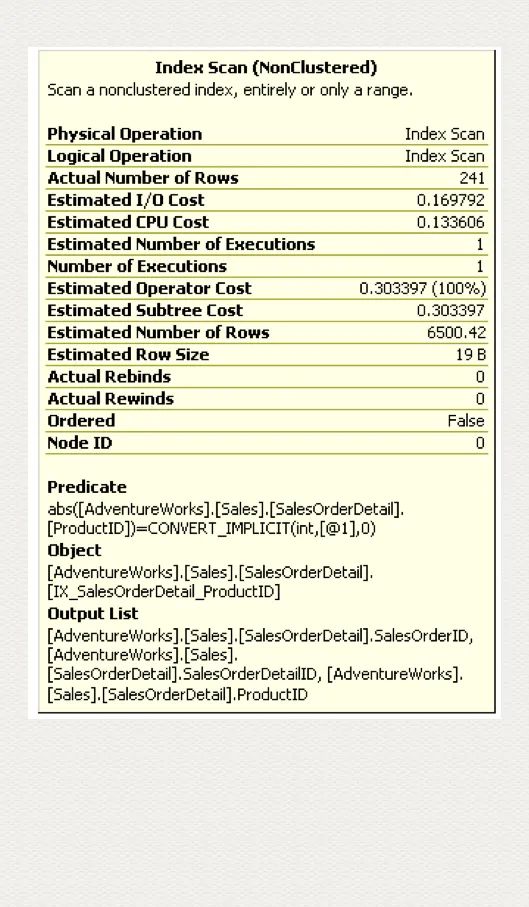
Predicate 表达式中,一旦索引字段(ProductID) 加了 abs() 函数,索引就失效了。
多列组合索引,情况就会复杂一些。当前列的条件判断是否能有效利用索引,取决于前一列使用的条件判断是否是等值判断。比如下列的判断条件,SQL Server 都是可以利用索引对两列字段做 seek 操作的,前提是索引按照判断条件字段的前后顺序建立的:(
以下的场景,均假设了按顺序建立了 ProductID + SalesOrderID, LastName + FirstName 的索引)
ProductID = 771 AND SalesOrderID > 34000LastName = 'Smith' AND FirstName = 'lan'
当第二列使用了函数或者复杂表达式,或者第一列使用了复杂表达式,那么就仅仅能使用索引去做第一列的 seek:
ProductID = 771 AND ABS(SalesOrderID) = 34000ProductID < 771 AND SalesOrderID = 34000LastName >'Smith' AND FirstName = 'lan'
又或者前一列用了函数或者表达式,那么整个索引就失效了:
ABS(ProductID) = 771 AND SalesOrderID = 34000LastName LIKE '%Smith' AND FirstName='lan'
看下第一列可以走索引的 seek 而第二列却不能利用 seek 的例子:
SELECT ProductID, SalesOrderID, SalesOrderDetailIDFROM Sales.SalesOrderDetailWHERE ProductID = 771 AND ABS(SalesOrderID) = 45233
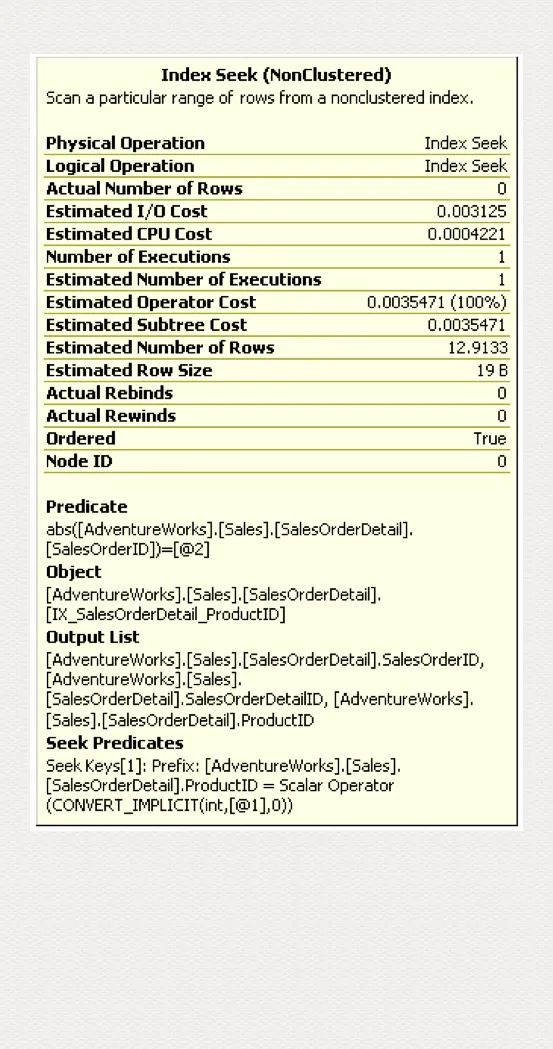
注意:Seek Predicates 显示有效利用了索引第一列 ProductID 的条件判断,而 Predicate 就显示索引第二列无法使用 seek 操作
数据库引擎优化顾问(The Database Engine Tuning Advisor)
大多数的商业数据库都会提供一个优化组件,帮助建立有效的索引。SQL Server 中这个组件就是数据库引擎优化顾问(The Database Engine Tunning Advisor). 理论上可以有两种架构来设计这个优化顾问,一种是新建一个成本模型估算成本,另一种是利用现有的查询优化器来估算成本。新建一个优化器除去一些复杂的操作和部署不说,基于新成本模型估算出来的执行计划,显然也不会给现有的优化器来用,现有的优化器始终还是以自己得到的执行计划去操作数据。因此,宝都押在利用现有查询优化器来做出优化评估。
SQL Server 是第一家搭载物理对象设计器的商业数据库,从 SQL Server 7.0 开始使用 Index Tuning Wizard 到 SQL Server 2005 替换成了 Database Engine Tuning Advisor( DTA). 两个产品都使用了优化器本身的成本估算模型去分析当前优化策略。目的就是为了达到高度自治和调优。除了索引以外,DTA 也可以帮助引导建立物化视图( indexed view) 和 分区(partition)。
当然优化顾问只是评估,并不会自动替人工去创建索引。那么不建立索引的情况下,优化顾问是怎么去评估,得出一个合理的索引?其实本质上优化器选择哪一个索引,完全建立在元数据以及字段的 statistics 之上,在优化的过程中,索引数据存在不存在不重要。索引一旦选择完毕,在执行的时候,一定需要索引数据必须存在。
开启优化顾问,当然会对数据库的性能有一定额影响,所以安排好适当时间。
所以在 DTA(Database Engine Tuning Advisor) 调优的过程中,SQL Server 不会真的去创建 DTA 认为完美的索引,而是给出一种叫做假设索引(hypothetical index),这类索引在 SQL Server 7 的 Index Tuning Wizard 当中也有用过。就如名字一样,hypothetical index 不是一种真实的索引,不以任何形式存在于数据库中,因为 DTA 一旦用完,这些索引就被丢弃了。他们只包含 statistics,只能用未归档的 CREATE INDEX 语句的 WITH STATISTICS_ONLY 选项来创建,且这个命令只有在 SQL Server Profiler 里面看得到。
下面看个简单的例子,用来找出索引没有正确创建的场景。
1) 创建一张新表,没有任何索引存在
SELECT *INTO dbo.SalesOrderDetailFROM Sales.SalesOrderDetail
2) 将下面的查询保存成文件
SELECT *FROM dbo.SalesOrderDetailWHERE ProductID = 897
3) 使用 DTA 来辅助分析缺少的索引
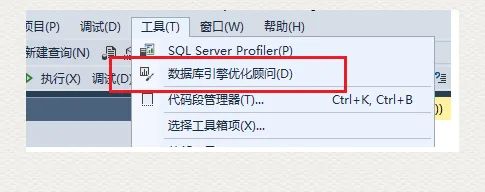
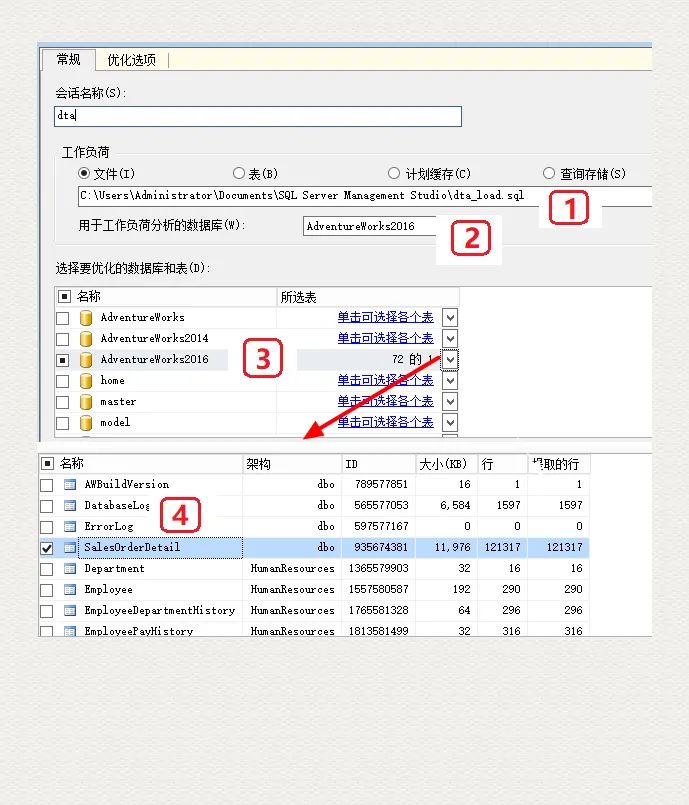
如上图所示,打开 DTA(Database Engine Tuning Advisor),在 Workload File 选项下面,定位到刚才新建的文件;选择需要测试的数据库 AdventureWorks; 点击 Start Analysis 命令执行。
等待 DTA 完成,打开这张表分析:
SELECT *FROM msdb..DTA_reports_query

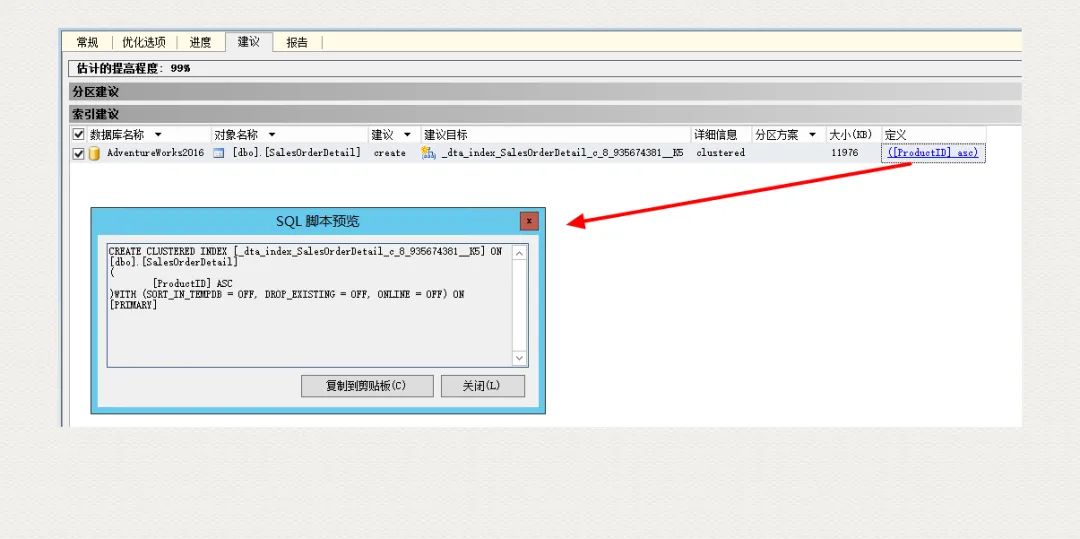
由此可见 ,DTA 帮我们推荐了个新的索引,据此索引生成的执行计划,成本只有 0.00332754. 而当前环境下,成本居然高达 1.24414. 通过打开预估执行计划窗口,这成本可以很容易得到。

我们根据 DTA 推荐的 Index Recommendations 创建索引,之后再执行上面的条件查询,很显然效率高很多。
hypothetical index 还可以通过 WITH STATISTICS_ONLY 创建:
CREATE CLUSTERED INDEX clx_ProductIDON dbo.SalesOrderDetail(ProductID)WITH STATISTICS_ONLY
查询索引的字典表:
SELECT name,type_desc,is_hypotheticalFROM sys.indexesWHERE object_id = object_id(N'dbo.SalesOrderDetail')AND name = 'cix_ProductID'
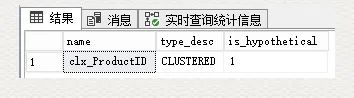
这里的 is_hypothetical 是 1, 代表的是一个假设的索引,并不真正存在。
Missing Indexes Feature(特性)
除了 DTA(Database Engine Tuning Advisor), SQL Server 还提供了一种方法来检测哪些索引对当前的查询是用的。这种方法称为 Missing Index 特性。这个方法不需要 DBA 去判断是否要进行调优,不需要严格指定请求文件,它很轻量,早在 SQL Server 2005 就已经推出来了。
在优化过程中,查询优化器会自动填补一个最优的索引,如果这个索引不存在,会在 xml 执行计划或者 GUI 执行计划里突出显示出来,并且会在缓冲中一直保留到下次重启,通过查询 sys.dm_db_missing_index 动态性能视图就可以看到统计情况。当优化器提示徐亚更好的索引满足查询时,实际上它在告诉我们两件事:1)当前的执行计划不是最优的;2)应该考虑新建索引来满足当前查询。当然, missing index 有自己不足,后面会讲到,更详细的解说可以参考官方在线文档, limitations of the Missing indexes Feature.
通过下面的这个小例子,我们一起探讨下 missing index 的使用场景:
如果你是从上面的例子一路看下来的,请 drop 表 dbo.SalesOrderDetail。
1)新建表 dbo.SalesOrderDetail
SELECT *INTO dbo.SalesOrderDetailFROM Sales.SalesOrderDetail
2) 运行下面的查询
SELECT *FROM dbo.SalesOrderDetailWHERE SalesOrderID = 43670 AND SalesOrderDetailID > 112
通过查询运行时执行计划及其属性,可知这类查询被称作 TRIVIAL optimization level.
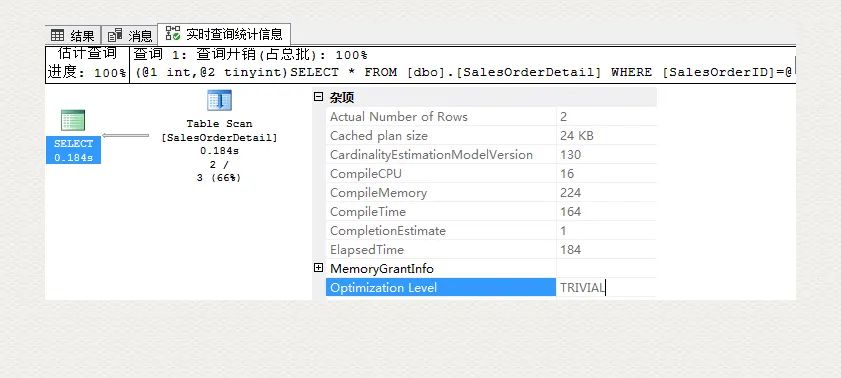
针对 TRIVIAL 级别的计划,查询优化器并不会给出最优的索引(基于哪个列,按照什么顺序)。由上图可见, GUI 并没有提示缺少什么样的索引。
基于此,我们可以通过增加无关的索引,来避免查询优化器评定查询为 TRIVIAL 级别。如下:
CREATE INDEX IX_ProductIDON dbo.SalesOrderDetail(ProductID)
此时,我们已经可以看到 GUI 提示“缺少索引”的告警了,且 Optimization Level 为 FULL.

这里解释下,什么是 trivial plan. 一句话概括就是简单的不能再简单的查询计划。比如:
SELECT ProductIDFROM dbo.SalesOrderDetailWHERE ProductID = 987
刚才我们已经在表 dbo.SalesOrderDetail 上面以 ProductID 字段为索引键,创建了索引 IX_ProductID. 因此仅查询 ProductID 且有条件表达式时,不再需要其他复杂的判断,走 index seek 即可。此时,执行计划就被称为 trivial plan.
处理了 trivial plan 的尴尬,剩下的事情,就是按照提示,我们判断这索引是不是要加,还是修改之前的索引,使其符合当下的查询:
SELECT *FROM dbo.SalesOrderDetailWHERE SalesOrderID = 43670 AND SalesOrderDetailID > 112

在 [MissingIndexes] 栏位下,我们可以看到 Impact, MissingIndex, Optimization Level 三个大栏。
Impact 是指 missing index 能在多大程序上影响现有的查询;
Missing Index 给出了优化器建议的索引字段和索引顺序;
Optimization Level 如果显示了 FULL, 表达的意思就是有优化调整空间
按照提示,我们新建索引:
CREATE INDEX IDX_ORD_DETAIL_IDON dbo.SalesOrderDetail(SalesOrderID,SalesOrderDetailID)
再执行上面的语句 :
SELECT *FROM dbo.SalesOrderDetailWHERE SalesOrderID = 43670 AND SalesOrderDetailID > 112
对比前后执行计划,这一次索引真排上用场了:
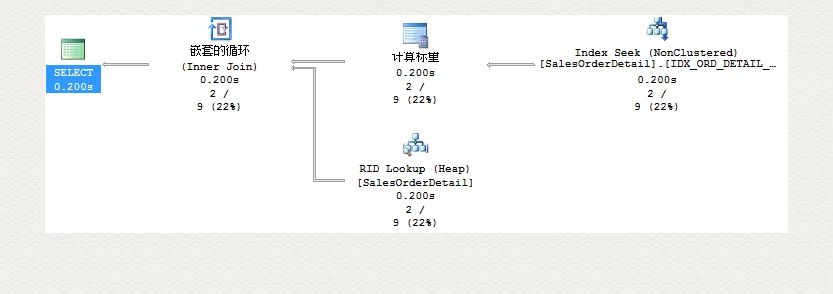
无用的索引(Unused Indexes)
在应用系统中,总有些表,索引,存储过程随着管理的松懈,慢慢遗留了下来。如何对这些无用(不再用)的数据库对象做处理,便成为了难题。本章讨论如何对无用的索引做处理。
为什么要处理掉这些无用的索引呢?首先,索引是表一样存在的数据库对象,占用了数据库磁盘空间;第二,在更新数据表的时候,索引会实时更新,对并发性能产生很大影响;第三,大量的索引,给优化器带来很大的运算压力。
判断索引无用的方法,核心是使用一张动态性能试图(DMV: Dynamic Management View), 即 sys.dm_db_index_usage_stats.
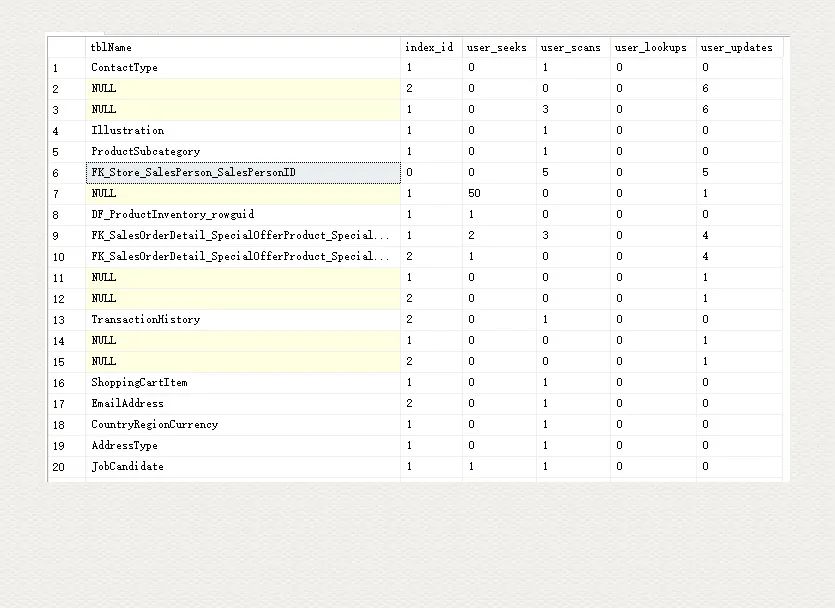
这张试图记录了所有 seek, scan, lookup, update 等操作的次数,还有最后一次的执行时间。除了索引(非聚集索引)使用频次统计之外,还有包括堆表和聚集表。和 sys.indexes 里面的规定一致,index_id 为 0 的即为堆表,index_id 为 1 的即为聚集索引表,大于等于 2 的为非聚集索引,这些 index_id 为 2 的索引才是我们要考虑去移除的。想想为什么?
SELECT object_name(object_id) as tblName, index_id, user_seeks, user_scans, user_lookups, user_updatesFROM sys.dm_db_index_usage_stats WITH(NOLOCK)
往期精彩: