
什么是数据库的索引?
索引
当数据库中数据量比较少的时候,哪怕全部检索也可以很快,但如果数据量达到了百万,千万,上亿的时候,还是全表扫描,那么数据查询的速度会慢的让人无法忍受。
索引的作用,就是为了加快数据查询,类似于我们查不认识的字时,使用字典的目录一样,在字典里面快速查询出不认识的字。字典可以根据读音的首字母,偏旁部首,笔画来查询。同样的,索引也有Hash索引,B-Tree索引,GIN索引等不同索引类型,根据查询的场景不同,可以选择创建对应的索引类型。
索引分类
数据结构实现
Postgresql支持丰富的索引类型,并且根据索引框架支持用户开发自定义的索引,下面列举下常用的索引类型及适用范围
| 索引类型 | 实现方法 | 适用范围 |
|---|---|---|
| b-tree | 使用b-tree数据结构来存储索引数据 | 等值查询或范围查询,以及in、between、is null、order by等,默认索引类型 |
| hash | 基于hash表实现 | 等值查询,尤其索引列值非常长的情况 |
| gist | 使用一种平衡的树形结构访问方法 | 多维数据类型和集合数据类型 |
| gin | 通用倒排索引,存储的是键值与倒排表 | 数组、jsonb、全文检索、模糊查询等 |
| brin | 块范围索引 | 索引列的值与物理存储相关性很强,比如时序数据 |
mysql的索引类型和数据库引擎相关性较强,不过最常用的B树索引是支持的
| 索引类型 | MyISAM | InnoDB |
|---|---|---|
| b-tree | yes | yes |
| hash | no | no |
| R-Tree | yes | no |
| Full-Text(类似gin) | yes | no |
聚簇索引与非聚簇索引
InnoDB 默认创建的主键索引是聚族索引(Clustered Index),其它索引都属于辅助索引(Secondary Index),也被称为二级索引或非聚族索引。
联合索引与单列索引
create index i1 on t2 (c1);
create index i2 on t2 (c1,c2);
pg的多列(联合)索引仅支持b-tree、gist、gin、brin类型,其中b-tree的多列索引,仅在索引的第一个字段出现在查询条件中才有效(最左匹配原则),而其他类型的多列索引可以支持任意字段查询 对于多字段查询,多列索引要比单列索引的查询速度快,可以避免回表查询,但对于单字段查询,多列索引就要比单列索引查询速度慢了,这里需要根据表的实际查询sql类型、频率,综合考虑是否需要使用多列索引。
部分索引
部分索引是指支持在指定条件的记录上创建索引,通过where条件指定这部分记录,比如:
postgres=# create table test(id int, c1 varchar(10));
CREATE TABLE
postgres=# insert into test select generate_series(100001,100100),'invalid';
INSERT 0 100
postgres=# create index i1 on test (c1) where c1 = 'invalid';
CREATE INDEX
postgres=# explain analyze select * from test where c1 = 'invalid';
QUERY PLAN
----------------------------------------------------------------------------------------------------------
Index Scan using i1 on t3 (cost=0.14..4.16 rows=1 width=11) (actual time=0.035..0.079 rows=100 loops=1)
Planning Time: 0.485 ms
Execution Time: 0.135 ms
(3 rows)
实际上对于数据分布不均的字段,创建正常的索引,在查询占比较小值时也是可以走索引的,查询占比较大值时无法走索引,如下所示,部分索引的优势在于索引体积小,维护代价也比较小
函数索引
函数索引指可以使用一个函数或者表达式的结果作为索引的字段,比如:
postgres=# create index i1 on test ((lower(c1)));
CREATE INDEX
postgres=# explain analyze select * from test where lower(c1) = 'xxx';
QUERY PLAN
--------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on test (cost=20.29..783.05 rows=500 width=37) (actual time=0.063..0.063 rows=0 loops=1)
Recheck Cond: (lower(c1) = 'xxx'::text)
-> Bitmap Index Scan on i1 (cost=0.00..20.17 rows=500 width=0) (actual time=0.060..0.060 rows=0 loops=1)
Index Cond: (lower(c1) = 'xxx'::text)
Planning Time: 0.406 ms
Execution Time: 0.095 ms
(6 rows)
postgres=# explain analyze select * from test where c1 = 'xxx';
QUERY PLAN
--------------------------------------------------------------------------------------------------
Seq Scan on test (cost=0.00..2084.00 rows=1 width=37) (actual time=19.016..19.016 rows=0 loops=1)
Filter: (c1 = 'xxx'::text)
Rows Removed by Filter: 100000
Planning Time: 0.121 ms
Execution Time: 19.048 ms
(5 rows)
此时如果直接使用c1字段作为查询条件是无法走索引的,同理如果创建的是普通索引,在查询时对字段加上了函数或者表达式,都不会走索引,我们应始终避免出现这样的问题
排序索引
在涉及order by操作的sql时,b-tree索引返回的结果是有序的,可以直接返回,而其他索引类型,需要对索引返回结果再进行一次排序。b-tree索引的默认排序为升序,空值放在最后,创建索引时可以指定排序方式,如按倒序排序时,空值默认是放在最前的,但往往我们的查询并不想展示空值的结果,此时可以在创建索引时指定排序desc nulls last以达到和查询sql切合的目的。
索引非银弹
索引需要占用额外的物理空间,如果表中的数据变化,也需要同步维护索引中的数据,对数据库的性能会有一定影响。考虑到索引的维护代价、空间占用和查询时回表的代价,不能认为索引越多越好。索引一定是按需创建的,并且要尽可能确保足够轻量。一旦创建了多字段的联合索引,我们要考虑尽可能利用索引本身完成数据查询,减少回表的成本。不能认为建了索引就一定有效,对于后缀的匹配查询、查询中不包含联合索引的第一列、查询条件涉及函数计算等情况无法使用索引。此外,即使SQL本身符合索引的使用条件,MySQL也会通过评估各种查询方式的代价,来决定是否走索引,以及走哪个索引。
数据库基于成本决定是否走索引
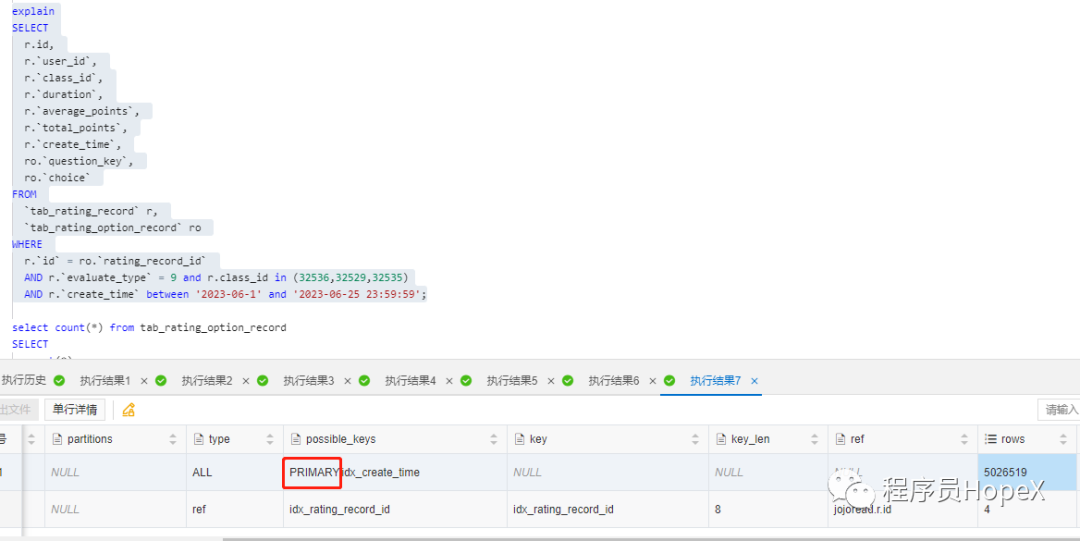
查询数据可以直接在聚簇索引上进行全表扫描,也可以走二级索引扫描后到聚簇索引回表。那么PostgreSQL/MySQL到底是怎么确定走哪种方案的呢。在满足能走索引的条件下,最终是否走索引由计划器生成的执行计划决定,PostgreSQL/MySQL中执行计划是完全基于代价估计的,如果估算的代价为全表扫描最优,则不会使用索引扫描
这里的代价,包括IO成本和CPU成本:
IO成本,是从磁盘把数据加载到内存的成本。默认情况下,读取数据页的IO成本常数是1(也就是读取1个页成本是1)。
CPU成本,是检测数据是否满足条件和排序等CPU操作的成本。默认情况下,检测记录的成本是0.2。基于此,我们分析下全表扫描的成本。
全表扫描,就是把聚簇索引中的记录依次和给定的搜索条件做比较,把符合搜索条件的记录加入结果集的过程。要计算全表扫描的代价需要两个信息:
1.聚簇索引占用的页面数,用来计算读取数据的IO成本;
2.表中的记录数,用来计算搜索的CPU成本。
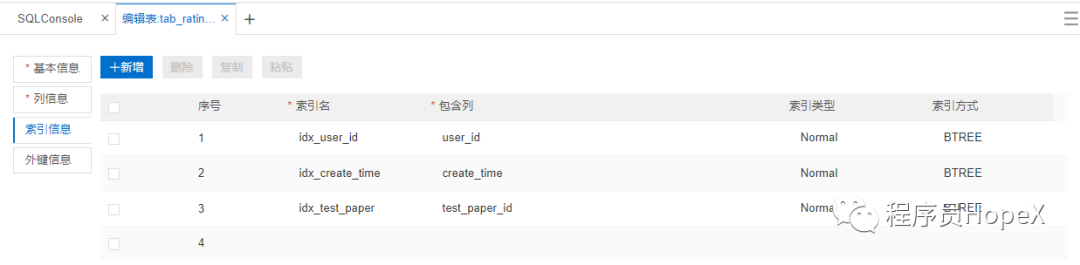
有时会因为统计信息的不准确或成本估算的问题,实际开销会和MySQL统计出来的差距较大,导致MySQL选择错误的索引或是直接选择走全表扫描,这个时候就需要人工干预,使用强制索引了。
索引失效
对于 Hash 索引实现的列,如果使用到范围查询,那么该索引将无法被优化器使用到。Hash 索引只有在“=”的查询条件下,索引才会生效。如果涉及范围查询则应建立b-tree索引
以 % 开头的 LIKE 查询将无法利用节点查询数据,这种情况下需要考虑gin索引或者es这种全文检索的方式
使用复合索引时,需要使用索引中的最左边的列进行查询,才能使用到复合索引。
例如我们在 order 表中建立一个复合索引 idx_user_order_status(order_no, status, user_id),如果我们使用 order_no、order_no+status、order_no+status+user_id 以及 order_no+user_id 组合查询,则能利用到索引;而如果我们用 status、status+user_id 查询,将无法使用到索引,这也是我们经常听过的最左匹配原则。
如果查询条件中使用 or,且 or 的前后条件中有一个列没有索引,那么涉及的索引都不会被使用到。
常见慢sql情况
没有创建索引,建表的时候一定不要忘记建立可能的索引,创建索引需要按照ESR原则进行
索引失效的情况,如查询字段上使用表达式导致索引失效比如在c1字段上存在一个b-tree索引,where c1+1 > 10000这个查询条件不会走索引,而where c1 > 10000-1可以走索引。
查询列表数据不分页,对于列表展现数据,在数据量特别大的情况,一次性返回所有数据一般不具有实际的业务意义,此时应通过limit offset进行分页,这样有机会利用到索引扫描和排序,降低全表扫描的影响,同时也能减小返回数据包过大的负担。
count (*) 时order by做无用排序由于列表展现与列表查数经常成对儿出现,有可能在复用列表展现的sql时在查数时也加入了排序操作,此时无论是否加上排序操作,得到的最终结果是一致的,但加上排序时大大增加了得到目标结果的代价。
跨表进行分组、排序,当涉及到跨表分组、排序时,需要把两个表的结果集汇总到一起进行排序、分组,这里的消耗是非常大的,此时可以考虑去冗余部分字段,使分组、排序操作在一个表中完成,这样能够利用到索引,起到优化效果。
慢sql对数据库cpu消耗极大,严重时甚至会宕机
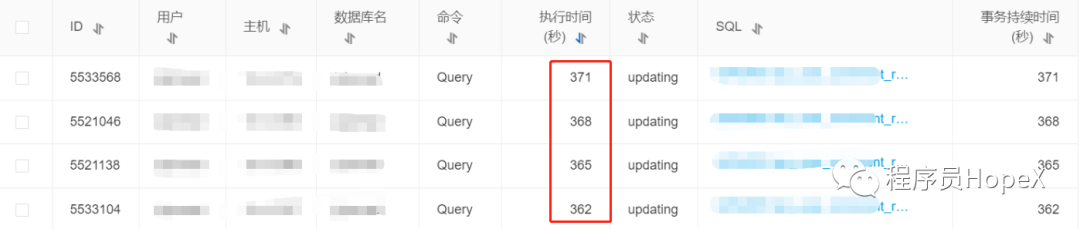
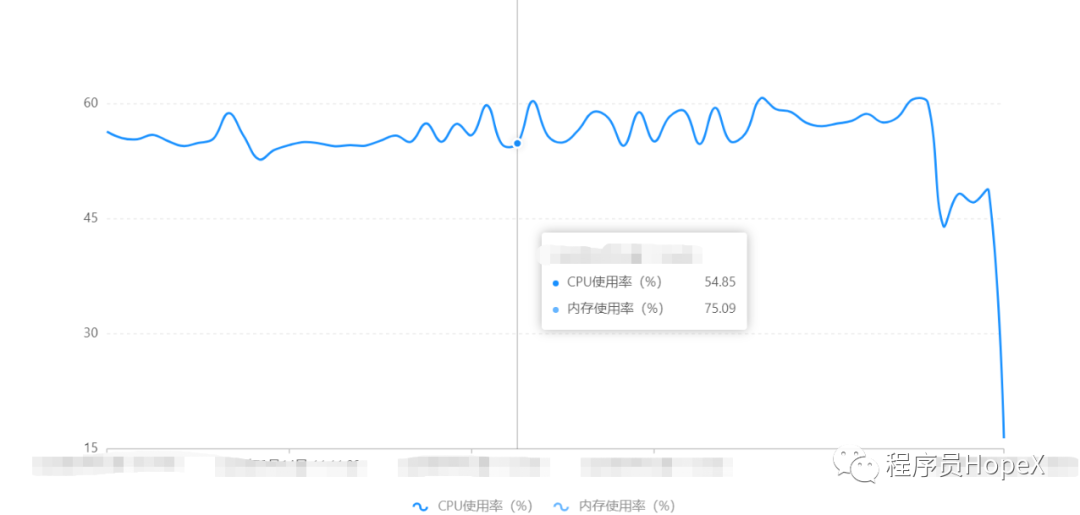
索引优化
子查询优化
实际的业务sql中,往往要涉及多个表进行关联查询,这里既可以使用子查询,也可以使用表连接,一般我们认为子查询方式的查询层次较多,且关联时的结果集较大,所以性能会差一些,执行计划器会对子查询进行逻辑优化,将子查询上提到父查询中,与父查询合并,过滤出较小的结果集再进行关联
子查询类型是否支持优化
any,some,exists,not exists基本支持,in部分情况支持,all,not in不支持.
写法优化
连接优化裁剪 利用left join消除无用的连接,当连表查询时,只输出左表字段,且连接条件的右表字段具有唯一性,那么可以使用left join消除部分连接
union all 代替 unionunion all不会进行去重,union会去重,如果在明确查询结果不存在重复数据时,union all的效率会高很多
避免使用select * 首先,如果select的字段被索引字段覆盖,那么可能就会使用仅索引扫描,这种扫描性能会更高一些。其次,select字段的多少直接影响着结果集数据包的大小,对于前台来说数据包越大,返回就越慢。还有对于一些复杂的查询,比如涉及子查询、连接、分组、聚合、排序等,过程中如果select字段过多,那么大概率会影响sql整体使用的work_mem,超出work_mem时则需使用磁盘,性能更低。
创建合适的索引
单表索引不应该超过5个。复合索引字段数量一定不可超过4个。复合索引字段数量多主要有以下2个影响:1.字段数量越多,对查询的要求越苛刻。查询必须按照索引的命中规则来安排。2.字段数量越多,索引的体积越大。数据的扇出度(单次IO能得到的数据条数)越低,IO效率也越低,而且索引被更新的概率越大,由于二级索引大部分情况下是随机更新,所以会引起B+树的平衡维护操作。
ESR原则
E 即Equal。查询中等于条件的字段优先考虑。S 即Sort,排序字段其次考虑。R 即Range,范围查询字段最后考虑 在经常用于查询的字段上创建索引,在经常用于连接的字段上创建索引,在经常用于排序的字段上创建索引
在选择性好的字段上创建索引
低基数字段不应该建立单独的索引。(该字段的不重复值个数低于总行数的 10%的称为低基数字段)。比如性别字段,只有男、女两种取值,认为选择性不好,不建议创建索引分布不均匀的字段不应该建立索引。如果一定需要,应该避免使用分布较高的值作为查询条件。分布不均匀指不同的列值占总体的比例差异很大(通常超过50%),即某一个列值或者某几个列值在整个数据集合中占比非常大。例如幼儿园学生年龄分段:年龄段占比3~5:95% ,6~8:3%, 9~12:1%,12~20:1%,20以上0%
适当创建联合索引,并将选择性好的字段作为第一个字段
对于频繁更新的表避免创建过多索引
高频更新字段不应该建立索引,高频更新字段,会以更新频率同步去更新索引。这会引起索引的删除、插入操作。频繁地删除索引上的数据,索引页会造成大量的空洞,进而引发树的平衡维护。
不建议在小表上创建索引
一定不可存在冗余索引。
例如 同时存在 idx_A_B(A,B) ,idx_A(A) 两个索引
索引单行长度不应该 超过200字节
按数据页16K计算,我们期望单个索引页至少应该存纳70个索引。默认的innodb的页上会留有1/16的空闲区域。这个空闲区域的主要作用是减少树的平衡操作。
InnoDB是如何存储和查询数据的
MySQL把数据存储和查询操作抽象成了存储引擎,不同的存储引擎,对数据的存储和读取方式各不相同。MySQL支持多种存储引擎,并且可以以表为粒度设置存储引擎。因为支持事务,我们最常使用的是InnoDB。
虽然数据保存在磁盘中,但其处理是在内存中进行的。为了减少磁盘随机读取次数,InnoDB采用页而不是行的粒度来保存数据,即数据被分成若干页,以页为单位保存在磁盘中。InnoDB的页大小,一般是16KB。
各个数据页组成一个双向链表
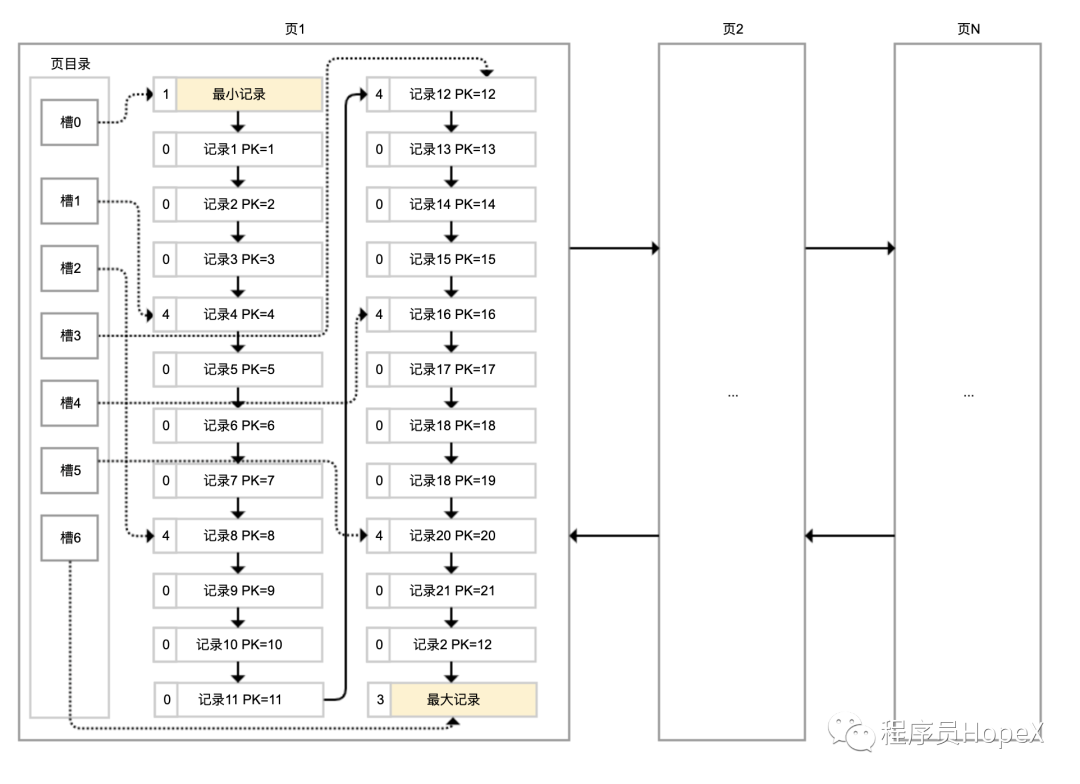
每个数据页中的记录按照主键顺序组成单向链表;每一个数据页中有一个页目录,方便按照主键查询记录。
数据页的结构如下:
页目录通过槽把记录分成不同的小组,每个小组有若干条记录。如图所示,记录中最前面的小方块中的数字,代表的是当前分组的记录条数,最小和最大的槽指向2个特殊的伪记录。有了槽之后,我们按照主键搜索页中记录时,就可以采用二分法快速搜索,无需从最小记录开始遍历整个页中的记录链表。
如果要搜索主键(PK)=15的记录:先二分得出槽中间位是(0+6)/2=3,看到其指向的记录是12<15,所以需要从#3槽后继续搜索记录;再使用二分搜索出#3槽和#6槽的中间位是(3+6)/2=4.5取整4,#4槽对应的记录是16>15,所以记录一定在#4槽中;再从#3槽指向的12号记录开始向下搜索3次,定位到15号记录。
B+树
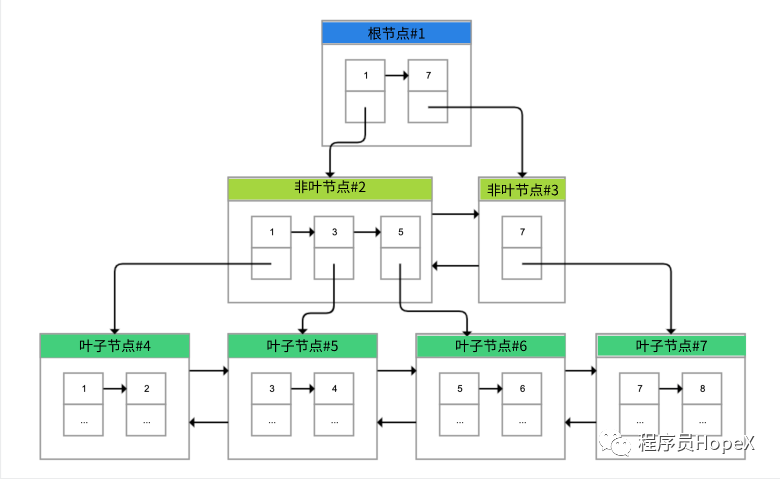
B+树的特点包括:1.最底层的节点叫做叶子节点,用来存放数据;2.其他上层节点叫作非叶子节点,仅用来存放目录项,作为索引;3.非叶子节点分为不同层次,通过分层来降低每一层的搜索量;4.所有节点按照索引键大小排序,构成一个双向链表,加速范围查找。因此,InnoDB使用B+树,既可以保存实际数据,也可以加速数据搜索,这就是聚簇索引。如果把上图叶子节点下面方块中的省略号看作实际数据的话,那么它就是聚簇索引的示意图。由于数据在物理上只会保存一份,所以包含实际数据的聚簇索引只能有一个,这也就是为什么主键只能有一个的原因。
InnoDB会自动使用主键
(唯一定义一条记录的单个或多个字段)作为聚簇索引的索引键(如果没有主键,就选择第一个不包含NULL值的唯一列)。上图方框中的数字代表了索引键的值,对聚簇索引而言一般就是主键。
我们再看看B+树如何实现快速查找主键。
比如,我们要搜索PK=4的数据,通过根节点中的索引可以知道数据在第一个记录指向的2号页中,通过2号页的索引又可以知道数据在5号页,5号页就是实际的数据页,然后再通过二分法查找页目录马上可以找到记录的指针。
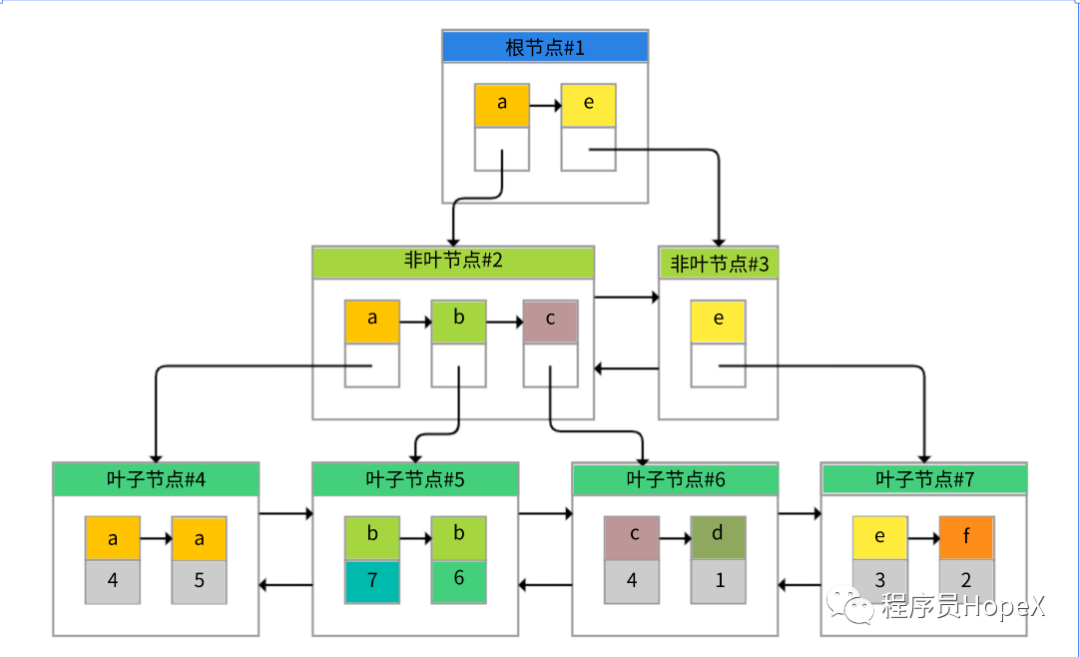
为了实现非主键字段的快速搜索,就引出了二级索引,也叫作非聚簇索引、辅助索引。
二级索引,也是利用的B+树的数据结构,如下图所示:
这次二级索引的叶子节点中保存的不是实际数据,而是主键,获得主键值后去聚簇索引中获得数据行。这个过程就叫作回表。比如有个索引是针对用户名字段创建的,索引记录上面方块中的字母是用户名,按照顺序形成链表。如果我们要搜索用户名为b的数据,经过两次定位可以得出在#5数据页中,查出所有的主键为7和6,再拿着这两个主键继续使用聚簇索引进行两次回表得到完整数据。
🍭 总结
以上就是索引的创建及使用时注意事项,最后汇总了一些索引优化方式,并分析InnoDB是如何存储和查询数据的。下一期将用2个真实案例分析索引在实际生产中的注意事项。
——End——