
硬件 | 详解泊车感知的摄像头需求
点击左上方蓝字关注我们

1
前情回顾
上一篇我们聊了自动泊车功能中车位线识别的一些数据及算法,但是从数据的角度来说很多时候算法工程师需要用相机模组采集真实场景的图像而不是直接购买第三方或者下载开源数据集做训练。那么从数据源头出发我们需要根据算法的输入形式和感知的需求提出技术指标,筛选Sensor和镜头模组甚至进行定制化业务。
2
泊车感知的输入形式?
在目前L2~L4的方案中,摄像头作为核心传感器通常部署在车辆周围一周,甚至能有10多个摄像头配合感知周围环境。不同位置的摄像头用处也不同,前视+周视相机往往用于行车感知;鱼眼相机往往用于360环视和泊车感知;车内相机往往用于驾驶员监控。
扯得有点远了,回到主题我们说的是做泊车选用的摄像头问题。较为常规的做法是使用四颗鱼眼相机环视拼接然后在鸟瞰图上做停车位检测,障碍物检测等多任务:如下图所示:

鸟瞰图的输入形式保留了地面线条的几何特征,有利于车位线的检测。但是从上图中可以看出基于鸟瞰图的检测存在两个问题:
感知的范围局限在车身周围15米以内;
有高度的物体投影到鸟瞰图后形状扭曲;
另一种做法是使用每颗鱼眼相机输出的原始视图独立做感知,当然我们可以拿未做畸变校正的数据作为输入,也可以使用畸变校正后的数据作为输入。如下图所示:

通过原始视图可以看出车辆,树木等障碍物仍然保持物体较真实的特征,并且从图像中能够看到较远处的物体;但是地面的车位线,车道线等标志在鱼眼相机中无法维持直线等几何形态,给检测增加了一定难度。
从上面两种图像的输入形式对比出发,基于拼接的鸟瞰图适合做车位线检测,基于原始视图适合做障碍物检测,所以大多数做泊车感知时偏向于拆分成两个网络分别处理不同的任务。这种类似于松耦合的方案,两个不同的任务放在不同的网络中独立运算,然后将输出的感知结果进行过滤合并。
3
如何减少传感器的数量
由于传感器类型的不同,行车的感知和泊车的感知一般是分开来做的。但是从传感器简化的角度,行泊一体化将是未来趋势,那么势必就要考虑鱼眼和周视相机是否能统一的问题。
假如把周视广角相机和环视鱼眼相机合二为一了,接下来就是这些问题了:
需要几颗摄像头,安装在什么位置?
需要多大的视场角覆盖车身周围的环境?
需要多大的分辨率用于检测远中近的物体?
高分辨率的数据ISP能否处理,算法压力如何?
........
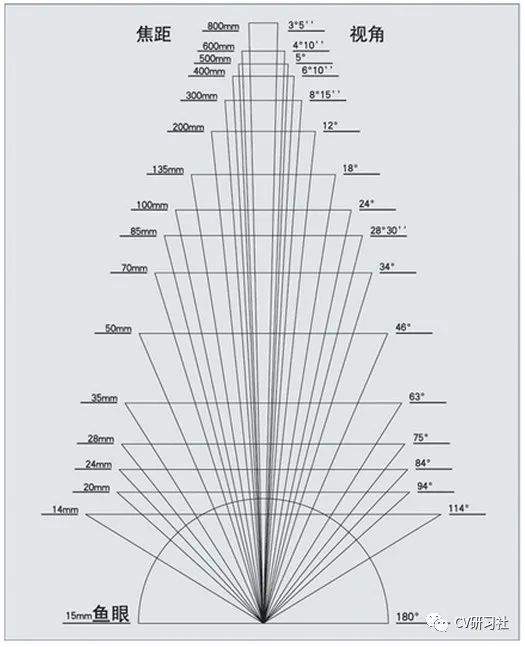
从硬件的角度可以定制传感器既具有鱼眼的超大FOV,又具有周视相机相对较高的PPD,能够兼顾80米甚至更远的障碍物。好奇的小伙伴肯定会问,焦距和视场角不是相互制约的吗?如下图所示:焦距越小,视场角越大。
但是挡不住模组厂商定制化业务的强大,只要有需求就有市场,有不少厂商把前视的多目摄像头整合在一个模组中用于感知。
从算法的角度需要考虑把周视相机做的的物体检测等功能和环视拼接后做的车位线检测等功能合并,这就回到上一小节提到的感知算法的图像输入形式了。功能上来说肯定是怎么做精度高就怎么来,分开多个网络各司其职完成任务,但是如果能统一输入形式,用一个模型多任务的处理所有任务,既简化了图像链路流程,又复用了一部分特征提取环节,小编觉得将是一个趋势,推荐都在原始视图上做感知功能,因为如果将一个障碍物检测的任务放在鸟瞰图上进行,那么越远处的立体物体扭曲就会越大。如图所示,在方圆5米内的车辆已然变形,何况60米处的障碍物。

4
影响摄像头性能的参数有哪些?
算法工程师需要根据功能需求提供技术要求给供应商选择合适的Sensor及镜头模组。那么有几个最常见的参数我们必须的了解:
分辨率:谈到摄像头,我们说的最多的就是分辨率是多少!通俗点说分辨率就是图像的大小,一般会用图像水平方向的像素点数 × 图像垂直方向的像素点数计算。比如业界说的标清的分辨率就是1280×720,也叫720P;高清的分辨率就是1920×1080,也叫1080P。
所以图像的分辨率越高,包含的像素越多,画面看起来就越清晰。描述分辨率的单位有以下几种:
dpi(点每英寸)
lpi(线每英寸)
ppi(像素每英寸)
ppd(像素每度)
其中ppd是算法工程师接触较多的一个指标,指视场角中的平均每 1° 夹角内填充的像素点的数量。如下图所示(图片来自于网络):
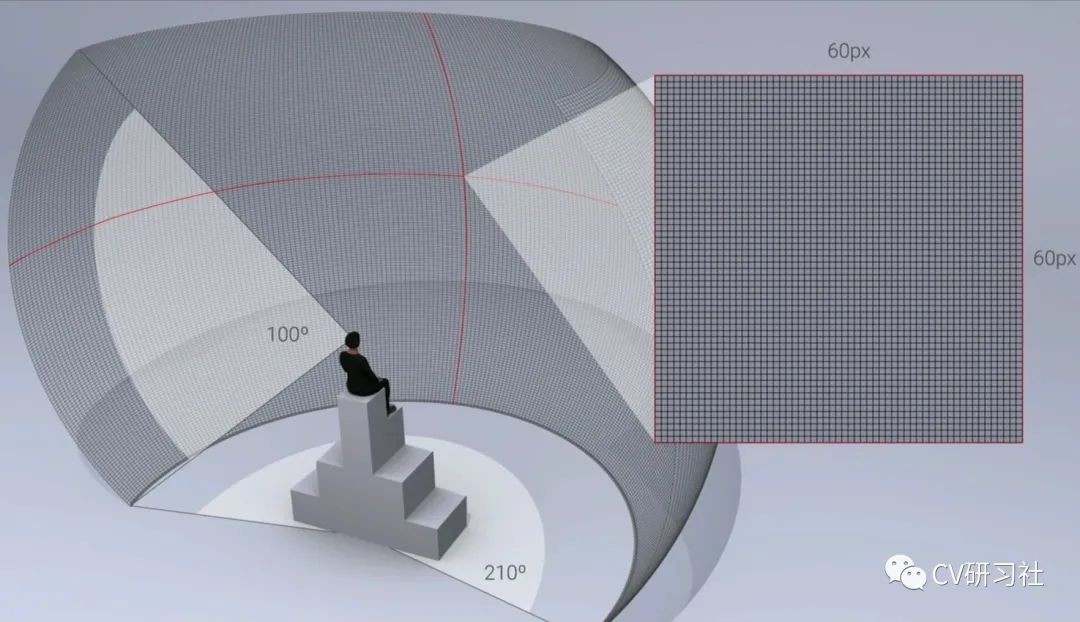
人眼观察周围环境时水平FOV是210°,垂直FOV是100°,当我们看手机时一般距离30~40cm,假设1°里面占据60个像素时,人眼是无法分辨像素颗粒度的。所以在VR等消费电子行业比较流行的说法是将60ppd的图像称为视网膜分辨率。
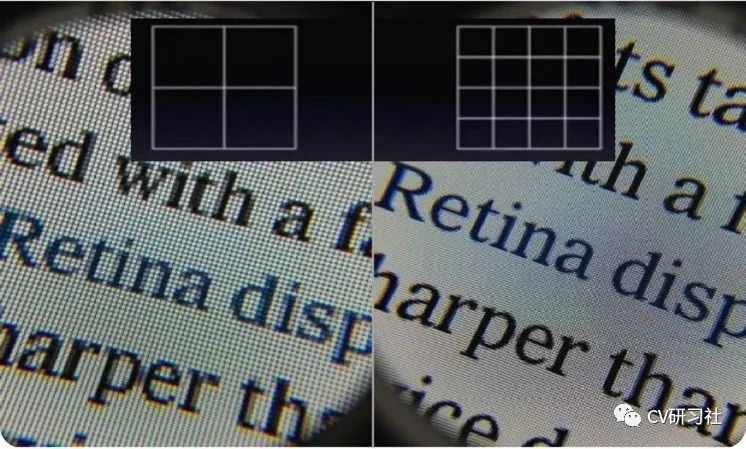
那么像素颗粒度是什么感觉?看看下图体会一下:
帧率:这是另一个常用的参数指标,一般指摄像头在某种色彩空间中最大分辨率下能够支持的最高视频捕获能力。
对于人眼来说,一般运动场景下能到达15fps的帧率已经是连续运动的效果了;但是对于感知算法在高速场景下还是需要摄像机满足30fps及以上的帧率。
相机的各个参数之间都有其关联性,比如上面说的ppd就和分辨率及视场角密切相关。那么帧率与分辨率和视场角有没有什么关系呢?
为了提高帧率,首先我们会考虑是否可以缩小视场角,如若不行,是否可以减少分辨率。在很多镜头的datasheet中会出现pixel binning mode。分辨率的下采样模式其实有两种:
Binning Mode
Skipping Mode
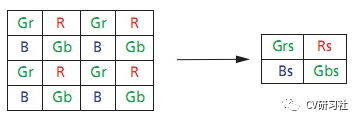
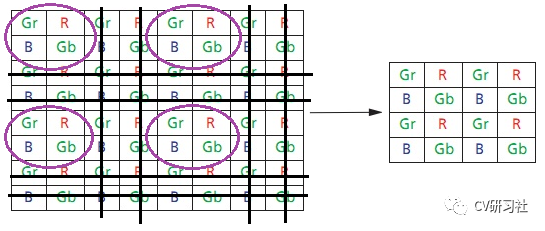
Binning Mode是将相邻的相同颜色单位电荷相加后输出一个信号。采用这种电荷合并的方式可以提供暗处对光感应的灵敏度。如下图所示(将四个相同颜色的B合并成Bs,其他雷同):
Skipping Mode是删除相邻的行列,起到隔行列抽样的效果。如下图所示:
动态范围:指图像最亮和最暗部分的相对比值。当在强光源照射下的高亮度区域及阴影、逆光等相对亮度较低的区域在图像中同时存在时,摄像机输出的图像会出现明亮区域因曝光过度成为白色,而黑暗区域因曝光不足成为黑色,严重影响图像质量。如果Sensor内的HDR达到一定的DB后,即可缓解此类情况。如下图所示:

还有好多比较重要的参数就不一一列举了,比如MTF:即调制传递函数,用于描述镜头的性能。
Distortion:物体通过光学系统后实际像高与理想像高的差值,离光轴越远的点畸变越大。
RI:即相对照度,用于描述光学系统成像面均衡性。
SNR:即信噪比,用于描述成像的抗干扰能力。
感光部件:CCD或者CMOS两种;
滤光片类型:RGGB、RCCB、RCCC等
这两个参数在之前的一篇文章里小编简单介绍过。
5
镜头的定制原则
首先考虑一下人是如何观察周围事物的,人的视力分为中心视力和周边视力:
中心视力较为敏锐,在中央处非常小的区域内,集中了绝大多数的视锥细胞,负责颜色和细节的感知,只有在这一小块区域,人们才能真正看清楚东西的细节和色彩,但需要较亮的光线下才起作用;
周边视力相对不敏锐,主要是视杆细胞,负责探知微弱光线,暗视下起主要作用。
在AI领域,摄像头一直被作为眼睛观察周围事物,所以从仿生学角度,也应该对镜头做相应定制化设计。当然有的同学会说,既然是物理元器件就可以人工堆性能,保持视场角不变的情况下,不断增加图像分辨率是否就可以了?
那么就存在分辨率过高,会导致图像文件太大、传输慢、耗流量、网速低的时候显示不出来等等问题,高分辨率可能会大大降低传输和运算速度,而这将是一个比“提高几乎看不出来的区别的细节”更严重的问题。
镜头的定制原则可以参考ADAS行业前视多目相机的目的,通常配一个HFOV~30°的长焦远视摄像头,一个中距离HFOV~52°主摄像头,一个近距离HFOV~120°的短焦广角摄像头。如果定制一款摄像头将不同角度内分布不同的数量的像素点是否可以将上述三目摄像机统一呢!根据需求测试测试PPD吧!
END
整理不易,点赞三连↓