
机器学习模型什么时候需要做数据标准化?
机器学习
Author:louwill
Machine Learning Lab
一直都有朋友在做机器学习模型时有疑问:我的数据要不要做标准化处理?
这个问题笔者也思考过,只不过不够系统,观点也比较单一,所以才有了上图中的【变量单位之间数量级差异过大】的回答。就着这个话题,笔者查阅相关资料,相对这个问题进行一个详细的阐述。
什么是数据标准化
在完整的机器学习流程中,数据标准化(Data Standardization)一直是一项重要的处理流程。一般我们将数据标准化放在预处理过程中,作为一项通用技术而存在。但很多时候我们并不清楚为什么要对数据做标准化处理,是不是做了标准化模型表现就一定会提升。
数据标准化的直接定义如下公式所示:
即对数据集特征每一数据减去特征均值后除以特征标准差。数据标准化可以将对应特征数据变换均值为0方差为1。经过数据标准化之后,数据集所有特征有了同样的变化范围。
数据标准化一个最直接的应用场景就是:当数据集的各个特征取值范围存在较大差异时,或者是各特征取值单位差异较大时,我们是需要使用标准化来对数据进行预处理的。
举个例子,一个包含两个特征的数据,其中一个特征取值范围为5000~10000,另一个特征取值范围仅有0.1-1,实际在建模训练时,无论什么模型,第一个特征对模型结果的影响都会大于第二个特征,这样的模型是很难有效做出准确预测的。
与数据归一化的区别
数据归一化(Normalization)同样也是一项数据预处理技术。但一直以来,我们都是标准化和归一化傻傻分不清楚,并且存在长期混用的情况。数据归一化的计算公式如下:
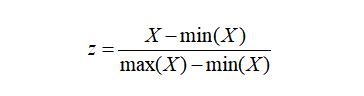
或者是:
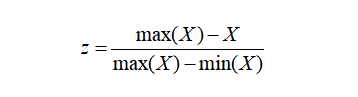
笔者查阅相关资料,发现对于这两种数据变换方法,一直没有统一的界定。很多时候都存在标准化和归一化概念混用的情况,有时候把z-score变换叫归一化,有时候又把min-max归一化叫标准化。通过比对,笔者认为标准化指的就是z-score变换,即前述第一个公式。归一化指的就是min-max变换,即前述第二或第三个公式。
数据标准化为了不同特征之间具备可比性,经过标准化变换之后的特征分布没有发生改变。数据归一化的目的是使得各特征对目标变量的影响一致,会将特征数据进行伸缩变化,所以数据归一化是会改变特征数据分布的。
哪些模型对标准化处理比较敏感?
机器学习中有部分模型是基于距离度量进行模型预测和分类的。由于距离对特征之间不同取值范围非常敏感,所以基于距离读量的模型是十分有必要做数据标准化处理的。
最典型基于距离度量的模型包括k近邻、kmeans聚类、感知机和SVM。另外,线性回归类的几个模型一般情况下也是需要做数据标准化处理的。决策树、基于决策树的Boosting和Bagging等集成学习模型对于特征取值大小并不敏感。所以这类模型一般不需要做数据标准化处理。另外有较多类别变量的数据也是不需要做标准化处理的。
结论
结论就是当数据特征取值范围或单位差异较大时,最好是做一下标准化处理。k近邻、kmeans聚类、感知机、SVM和线性回归类的模型,一般也是需要做数据标准化处理的。另外最好区分一下数据标准化和数据归一化。
参考资料:
https://towardsai.net/p/data-science/how-when-and-why-should-you-normalize-standardize-rescale-your-data-3f083def38ff
往期精彩:

喜欢您就点个在看!
