来源丨https://zhuanlan.zhihu.com/p/231302709 本文仅用于学术分享,如有侵权,请联系后台作删文处理 通过深入了解自己手头 GPU 的计算能力上限,能够在买新卡时做出更理性判断。本文深入GPU架构,重点介绍了其中的ampere架构。另外,作者还对比了不同GPU之间的峰值计算能力,增加读者对硬件资源的了解。
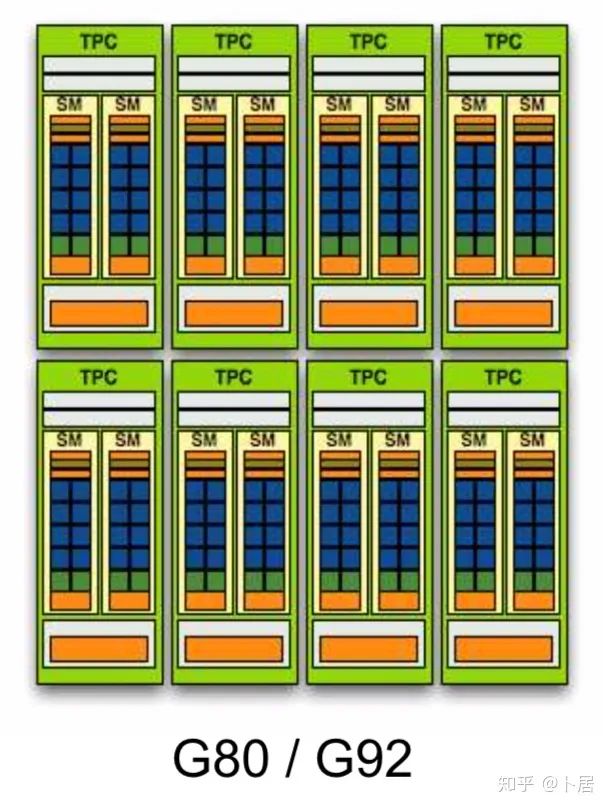
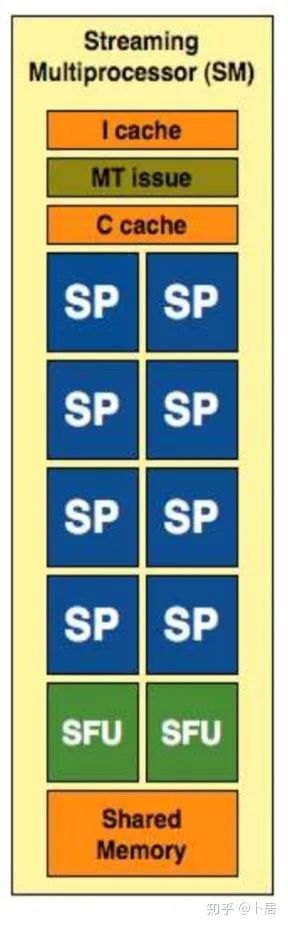
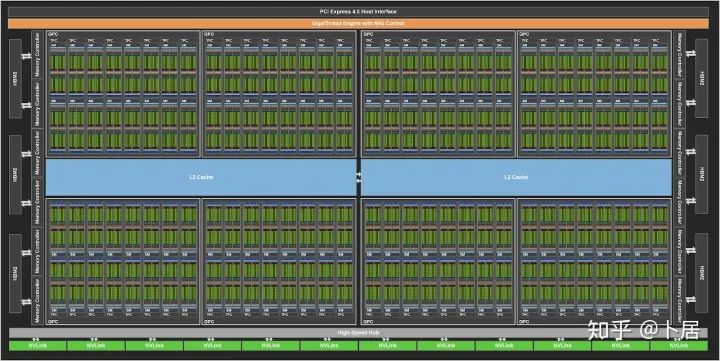
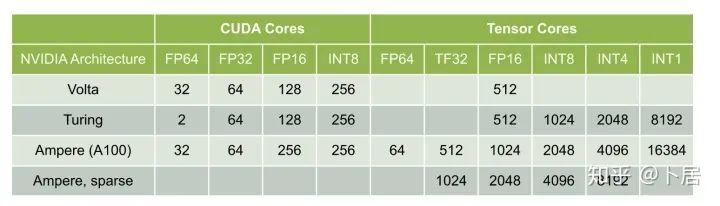
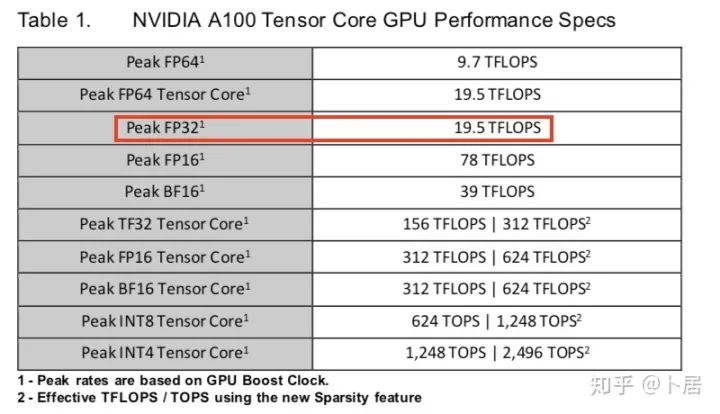
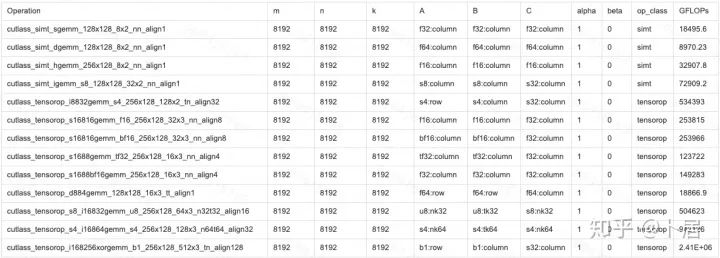
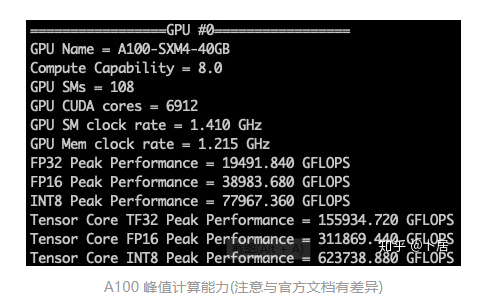
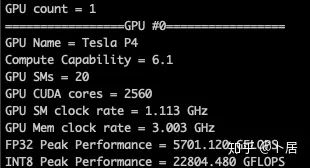
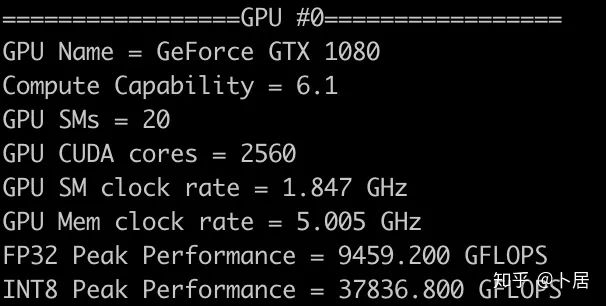
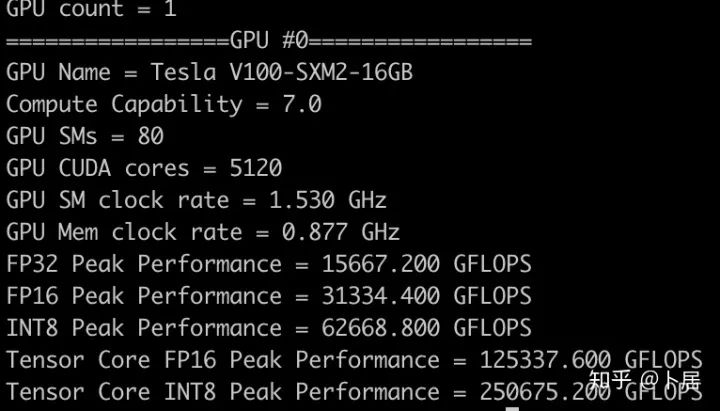
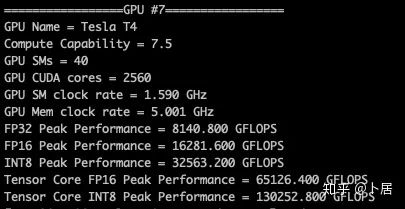
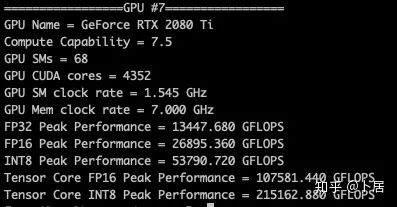
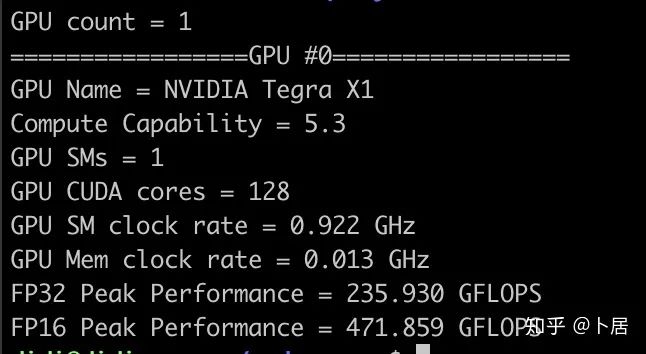
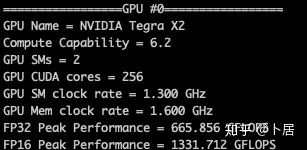
1、前言 2020年5月14日,在全球疫情肆虐,无数仁人志士前赴后继攻关新冠疫苗之际,NVIDIA 创始人兼首席执行官黄仁勋在自家厨房直播带货,哦不对应该是 NVIDIA GTC 2020 主题演讲中热情洋溢地介绍了新鲜出炉的基于最新 Ampere 架构的 NVIDIA A100 GPU,号称史上最豪华的烧烤。 NVIDIA A100 Tensor Core GPU 基于最新的 Ampere 架构,其核心为基于台积电 7nm 工艺制造的 GA100,内有 542 亿晶体管,裸片尺寸为 826mm^2,而前代 GV100 裸片尺寸 815mm^2,内有 211 亿晶体管,短短 3 年时间,得益于新工艺,芯片集成度翻了不止一倍! 从 NVIDIA 发布会内容以及白皮书中能看到一些夺目的数字,今天我们来解密这些数字是怎么得出来的。为此我们需要深入 GPU 架构一探究竟。 2、GPU 架构演变 图形处理器(GPU, Graphics Processing Unit),用来加速计算机图形实时绘制,俗称显卡,经常用于打游戏。自 NVIDIA 于 1999 年发明第一款 GPU GeForce 256,尔来二十有一年矣。 从图片看到 GeForce 256 衣着相当简朴,完全看不到 RTX 3090 的贵族气质,显示输出口仅支持 VGA,显存 32 MB,另外和主机的接口是早已不见踪影的 AGP,支持的图形 API 为 DirectX 7.0、OpenGL 1.2,目前主流游戏都跑不动,放到现在只能当摆设。 那时显卡还只是纯粹的显卡,硬件架构还是固定的渲染流水线,如下图所示。 渲染流水线中可被程序员控制的部分有两处:Geometry Processing 和 Pixel Processing,前者处理几何坐标变换,涉及矩阵乘计算;后者处理图像像素,涉及插值计算。有一些对科学有执着追求的人们试图用渲染流水线做一些除了打游戏之外更为正经的工作。于是,他们把计算输入数据伪造成顶点坐标或纹理素材,把计算机程序模拟为渲染过程,发挥异于常人的聪明才智,使用 OpenGL/DirectX/Cg 实现各类数值算法,将显卡这个为游戏做出突出贡献的可造之材打造为通用并行计算的利器,此时的 GPU 被赋能了更多工作内容,称作 GPGPU(General Purpose GPU)。 从事 GPGPU 编程的程序员十分苦逼,既要懂图形 API、GPU 架构,还要把各个领域算法摸清楚翻译为顶点坐标、纹理、渲染器这些底层实现,十分难以维护,今天一气呵成的代码,明天就形同陌路。程序如有 bug,调试工具奇缺,只能靠运气和瞪眼法。 为了彻底解放生产力,提高编程效率,NVIDIA 在 2006 年引入统一图形和计算架构以及 CUDA 工具,从此 GPU 就可以直接用高级语言编程,由程序员控制众多 CUDA 核心完成海量数值计算,GPGPU 业已成为历史。 GeForce 8800 是第一款支持 CUDA 计算的 GPU,核心为 G80,首次将渲染流水线中分离的顶点处理器与像素处理器替换为统一的计算单元,可用于执行顶点/几何/像素/通用计算等程序。G80 首次引入 SIMT(Single-Instruction Multiple-Thread) 执行模型,多个线程在不同计算单元上并发执行同一条指令,引入 barrier 和 shared memory实现线程间同步与通信。G80 架构图如下: G80/G92 架构图,G92 相比 G80 仅为工艺升级(90nm -> 65nm),架构没有变化 在 G80 中有 8 个 TPC(纹理处理簇,Texture Processing Clusters),每个 TPC 有 2 个 SM(流多处理器,Stream Multiprocessors),共计 16 个 SM。每个 SM 内部架构如下图: 每个 SM 内部有 8 个 SP(流处理器,Streaming Processor,后改称 CUDA Core),这是真正干活的单元,可以完成基本数学计算。8 个 SP 需要听口号统一行动,互相之间通过 shared memory 传递信息。 G80 架构比较简单,奠定了通用计算 GPU 的基础。接下来的 14 年,NVIDIA GPU 以大约每两年一代的速度逐步升级硬件架构,配套软件和库也不断丰富起来,CUDA Toolkit 最新已到 11.0,生态系统已颇为健壮,涵盖石油探测、气象预报、医疗成像、智能安防等各行各业, GPU 现已成为世界顶级超算中心的标配计算器件。 下表展示了从 2006 年至今支持 CUDA 计算的 GPU。有没有看到你手中的那一款? 架构起名是有讲究的,都是科学史上著名的物理学家、数学家(同时也是理工科同学的梦魇,多少次因为写错了计量单位被扣分):特斯拉、费米、开普勒、麦克斯韦、帕斯卡、伏打、图灵、安培。(那么接下来是?) 限于篇幅,我们不再深入探讨每种架构细节,直接跳跃到最新 Ampere 架构,看看世界顶级计算能力是如何炼成的。对历史感兴趣的读者可以继续研读扩展材料【6】。 3、Ampere 架构详解 从 Ampere 白皮书【1】看到 GA100 的总体架构图如下: 总体布局比较中正,八个 GPC 与 L2 Cache 坐落于核心地段,左右为外部存储接口,12 道显存控制器负责与 6 块 HBM2 存储器数据交互,顶部为 PCIe 4.0 控制器负责与主机通信,底部又有 12 条高速 NVLink 通道与其他 GPU 连为一体。 GA100 以及基于 GA100 GPU 实现的 A100 Tensor Core GPU 内部资源如下表所示: GPC —— 图形处理簇,Graphics Processing Clusters TPC —— 纹理处理簇,Texture Processing Clusters SM —— 流多处理器,Stream Multiprocessors HBM2 —— 高带宽存储器二代,High Bandwidth Memory Gen 2 实际上到手的 A100 GPU 是阉割版,相比完整版 GA100 少了一组 GPC 和一组 HBM2。至于为什么,要考虑这个芯片巨大的面积和工艺水平,以及整板功耗。由于少了这一组 GPC,导致后面一些奇奇怪怪的数字出现,等到了合适的时机再解释。 GA100 的 SM 架构相比 G80 复杂了很多,占地面积也更大。每个 SM 包括 4 个区块,每个区块有独立的 L0 指令缓存、Warp 调度器、分发单元,以及 16384 个 32 位寄存器,这使得每个 SM 可以并行执行 4 组不同指令序列。4 个区块共享 L1 指令缓存和数据缓存、shared memory、纹理单元。 每个 SM 除了 INT32、FP32、FP64 计算单元之外,还有额外 4 个身宽体胖的 Tensor Core,这是加速 Deep Learning 计算的重磅武器,已发展到第三代,每个时钟周期可做 1024 次 FP16 乘加运算,与 Volta 和 Turing 相比,每个 SM 的吞吐翻倍,支持的数据类型也更为丰富,包括 FP64、TF32、FP16、BF16、INT8、INT4、INT1(另外还有 BF16),不同类型指令吞吐见下表【2】所示: Volta/Turing/Ampere 单个 SM 不同数值类型指令吞吐 利用这张表我们可以计算出 GPU 峰值计算能力,公式如下: 其中 例如 A100 FP32 CUDA Core 指令吞吐 对照 NVIDIA Ampere 白皮书【1】 中有关 FP32 峰值计算能力的数字 19.5 TFLOPS,基本一致。 将剩下的指令吞吐数字代入公式中,可以得到 A100 其他数据类型的峰值计算能力,包括令人震惊的 TF32 和令人迷惑的 FP16 性能。 理论峰值计算能力只是一个上限,我们还关心 GPU 计算能力实测值,可以利用如下公式: 其中 其中 A、B、C、D 均为矩阵,各自尺寸以下标作为标识。完成上述公式计算所需总乘加次数为: 从前面两张图看到 Volta/Turing 架构 CUDA Core FP16 计算吞吐为 FP32 的 2 倍,而到了 Ampere 架构发生了阶跃,直接变 4 倍(256 vs 64,78 TFLOPS vs 19.5 TFLOPS),我们拿到物理卡后第一时间进行了不同精度 GEMM 评测,发现 FP16 性能相比 FP32 并非 4 倍,而是和 Turing 一样 2 倍左右,感觉更像是文档出现了谬误。 4、不同型号 GPU 峰值计算能力对比 我们可以通过翻阅 GPU 数据手册、白皮书获得不同型号 GPU 峰值计算能力,但这仅停留在纸面,对于管控系统而言需要借助工具来获取这些数值记录在设备数据库,之后调度器可根据计算需求以及库存情况进行计算能力分配。本节将提供这样一个工具来自动计算 GPU 峰值计算能力,基于 CUDA Runtime API 编写,对具体 CUDA 版本没有特殊要求。A100 上运行输出如下: 由此得到的 A100 理论峰值计算能力与上节 CUTLASS 实测结果能对号入座。 利用该工具,你可以更深入了解自己手头 GPU 的计算能力上限,买新卡时会做出更理性判断。下面展示 2016-2020 主流 GPU 型号及其理论峰值计算力: Tesla P4 峰值计算能力, P4 实际可以超频到 1.531 GHz,官方并未对超频性能做出承诺,用户需根据业务特点进行合理设置 Tesla P100(PCIe 版) 峰值计算能力, NVLink 版比这个结果要高一点 Tesla V100 峰值计算能力,忽略最后一行(系早期工具 bug) Tesla T4 峰值计算能力, 实测 T4 正常工作频率约为峰值的 70% RTX 2080 Ti, 2018, Turing Jetson Nano, 2019, Maxwell Jetson Xavier, 2018, Volta 如果上面结果中没有发现你的 GPU 装备,欢迎运行下面代码并将结果发在评论区。 5、本文代码 #include nvcc -I/usr/local/cuda/include -L/usr/local/cuda/lib64 -lcudart -o calc_peak_gflops calc_peak_gflops.cpp 如果提示 nvcc 命令未找到,请先安装 CUDA 并设置 PATH 环境变量包含 nvcc 所在目录(Linux 默认为 /usr/local/cuda/bin)。 export PATH=/usr/local/cuda/bin:$PATH 6、后记 通过获取 GPU 峰值计算能力,可以加深对手头的硬件资源了解程度,不被过度宣传的文章洗脑,多快好省地完成工作。 [1] https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/nvidia-ampere-architecture-whitepaper.pdfwww.nvidia.com [2] GPU Performance Background User Guidedocs.nvidia.com [3] https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/tesla-product-literature/NVIDIA-Kepler-GK110-GK210-Architecture-Whitepaper.pdfwww.nvidia.com [4] https://images.nvidia.com/content/pdf/tesla/whitepaper/pascal-architecture-whitepaper.pdfimages.nvidia.com [5] https://images.nvidia.com/content/volta-architecture/pdf/volta-architecture-whitepaper.pdfimages.nvidia.com
推荐阅读
添加极市小助手微信 (ID : cvmart2) ,备注: 姓名-学校/公司-研究方向-城市 (如:小极-北大-目标检测- 深圳),即可申请加入 极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解 等技术交流群: 每 月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、 与 10000+ 来自 港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流 ~ 觉得有用麻烦给个在看啦~