
免费薅 GPU 算力羊毛,速领!
趋动云

学校课题组没显卡?搭环境费时费力,经常卡 bug ?师兄正在跑实验,排队要到下个月?小破卡炼丹太慢,论文赶不上 DDL?考虑到 公子龙 粉丝对算力的需求,推荐一个正在做活动的 GPU 算力平台。它具有以下特点:
-
算力灵活、按需使用(想开几卡开几卡)
-
低上手门槛(几乎不需要学习什么新东西)
-
分布式优化(免去自己优化的烦恼)
-
协作共享(大小团队皆可笑开颜)
-
...
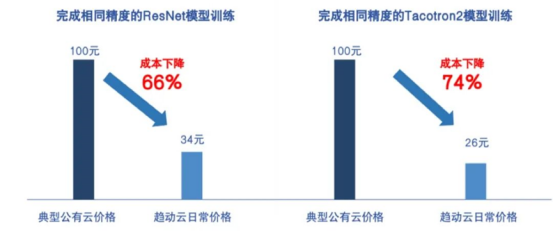
特别适合各位小伙伴用来做模型训练。除了训练速度快之外,平台提供了大量热门公开数据集,省去大家上传数据集的时间成本。它就是趋动云!(小声告诉你),平台为公子龙粉丝提供了不少的免费算力(面向新注册用户),欢迎在文末领取!
高性价比
相较市面上同类型公有云产品,趋动云算力拥有较高的性价比。采用分钟级的实时计费模式,具体可以见下表。另外趋动云算力最低价格0.49元/卡时,要比其它公有云包月后平摊价格还便宜。
| 基础版 | 活动价:元 |
| B1.small GPU: 1 gpu(s), 每个GPU显存: 6 GB CPU: 4 core(s), 内存: 12 GB | 0.49元/小时 |
| B1.8xlarge GPU: 8 gpu(s), 每个GPU显存: 24 GB CPU: 32 core(s), 内存: 96 GB | 15.92元/小时 |
| B2.small GPU: 1 gpu(s), 每个GPU显存: 6 GB CPU: 4 core(s), 内存: 12 GB | 0.69元/小时 |
| B2.8xlarge GPU: 8 gpu(s), 每个GPU显存: 24 GB CPU: 32 core(s), 内存: 96 GB | 22.32元/小时 |
| 标准版 | 活动价:元 |
| S2.large GPU: 1 gpu(s), 每个GPU显存: 24 GB CPU: 8 core(s), 内存: 48 GB | 3.18元/小时 |
| S2.8xlarge GPU: 8 gpu(s), 每个GPU显存: 24 GB CPU: 64 core(s), 内存: 384 GB | 25.45元/小时 |
| S3.large GPU: 1 gpu(s), 每个GPU显存: 24 GB CPU: 8 core(s), 内存: 48 GB | 4.46元/小时 |
| S3.8xlarge GPU: 8 gpu(s), 每个GPU显存: 24 GB CPU: 64 core(s), 内存: 384 GB | 35.69元/小时 |
| 高级版 | 活动价:元 |
| P1.small GPU: 1 gpu(s), 每个GPU显存: 20 GB CPU: 4 core(s), 内存: 12 GB | 2.12元/小时 |
| P1.8xlarge GPU: 8 gpu(s), 每个GPU显存: 80 GBCPU: 32 core(s), 内存: 96 GB | 67.92元/小时 |
| P2.large GPU: 1 gpu(s), 每个GPU显存: 80 GB CPU: 8 core(s), 内存: 48 GB | 13.58元/小时 |
| P2.8xlarge GPU: 8 gpu(s), 每个GPU显存: 80 GB CPU: 64 core(s), 内存: 384 GB | 108.65元/小时 |
灵活算力,按需使用
基于GPU池化技术,可以提供更灵活的算力选择,通过内置数十种算力规格,更准确匹配算力需求,采用按需使用模型,最低成本获得高性能的计算服务。

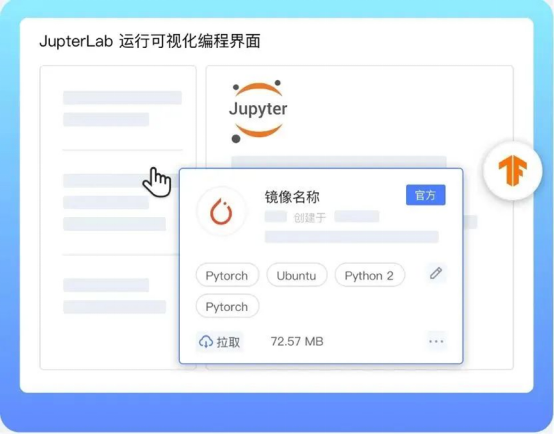
低上手门槛
无需手工配置训练环境的繁琐,平台内置常用框架镜像、公开数据集,可快速基于 JupyterLab 进行可视化编程界面、一键式离线任务提交,快速开启 AI 开发之旅。
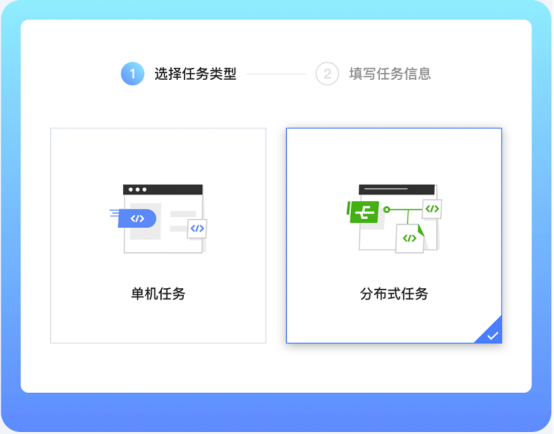
分布式优化
为分布式训练优化,支持一机多卡,多机多卡等多种分布式训练形态。支持运行 tensorflow、pytorch、hovorod等多种框架的分布式训练。
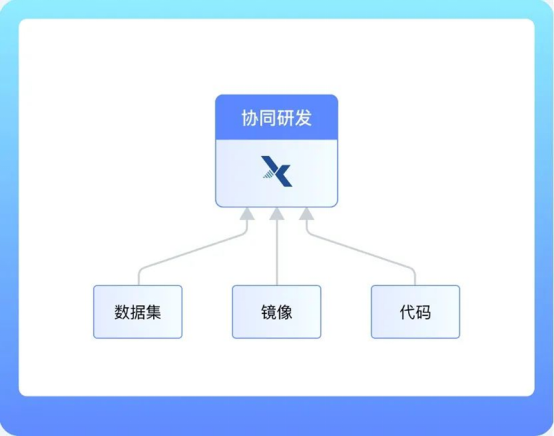
协作共享
数据集、镜像和代码共享,实现团队内部资源共享,协同研发。
快速集成
集成了 git 代码仓库,基于 S3 协议的云对象存储和 nfs 协议的文件存储,历史工作可以平滑过渡到平台上,免去迁移工作的烦恼。

写在最后
关于趋动云 GPU 平台公子龙专属注册地址(也可点击左下角阅读原文):
https://growthdata.virtaicloud.com/t/Da
也可扫码注册:

注册后可在“设置”->"资源配额"处查看当前厂家分配的计算和存储资源:我在账户看到的是16核CPU、48GB内存、2卡GPU等等。
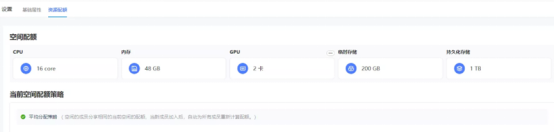
目前对于首次注册用户,账户会立刻激活价值168元的赠送算力,有效期1年哦。公子龙的粉丝福利:因为小助手太好说话,对于新注册用户,有更大算力需求的,可以联系他领取更多免费算力:
趋动云小助手