
算力猛兽:浪潮NF5468A5 GPU服务器深度测评


GHz主频,L3 Cache 256MB | |



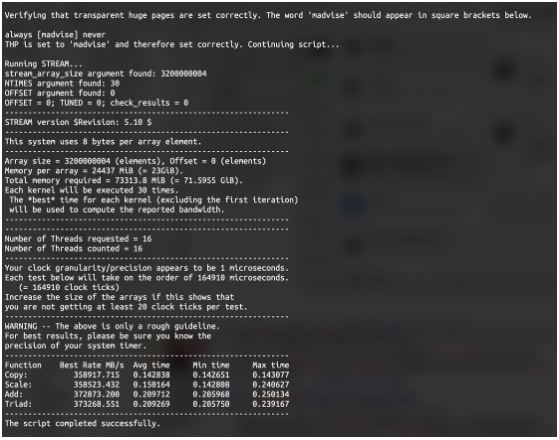
DDR4内存,同时可以看到服务器主板整齐排布了32个DDR4内存插槽,最大容量可达8TB,内存总带宽750GB/s,支持RDIMM/LRDIMM等类型的内存条。NF5468A5强劲的处理器性能、巨大的内存容量和带宽,特别适合AI计算、云计算、HPC以及企业各类业务的工作负载。

A100 PCIE 40GB GPU加速卡,由于每张卡功耗高达250W,服务器也给GPU板卡配置了单独供电线,保证GPU卡的稳定工作。为了满足PCIE卡的高功率运行,我们看到NF5468A5在GPU板上专门设计了4个用于大电流通流的bus bar,据浪潮的工程师介绍,bus bar的通流能力可以达到2880W,这对于各类PCIE加速卡的支持是非常强劲的。

A100 PCIE 40GB GPU

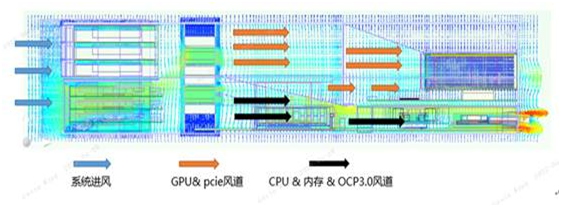

Switch只有1条与CPU PCIE通路比,带宽提升4倍,这种极致的互联架构设计,有助于提升GPU与CPU间数据通信的带宽,有效降低数据的处理延迟。
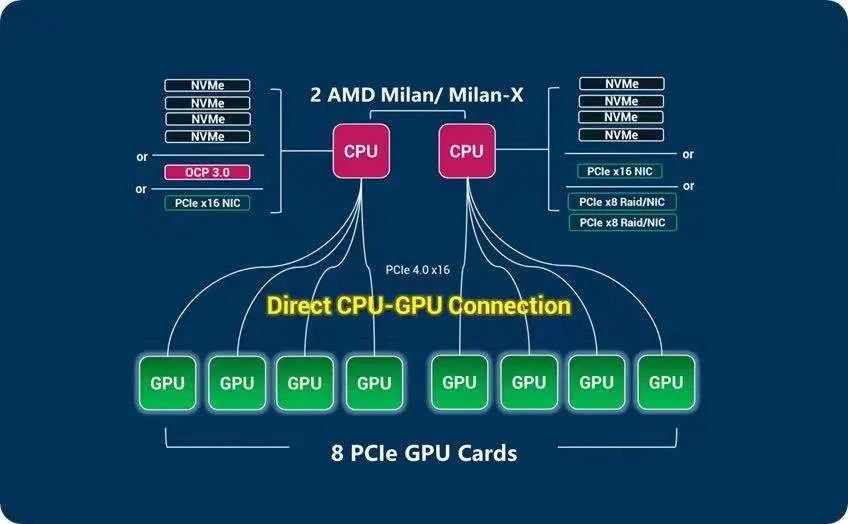
HPL测试
EPYC 7543处理器,这款处理器是32 核 64 线程,基准主频2.8GHz,L3 Cache 256MB,最大加速时钟频率最高可达3.7GHz,功耗225W。为了能够了解CPU实际性能,下面将采用HPL基准软件进行测试。
none --report-bindings --mca btl self,vader" # mpi_options="$mpi_options --map-by ppr:1:l3cache -x OMP_NUM_THREADS=4 -x OMP_PROC_BIND=TRUE -x OMP_PLACES=cores" # mpirun $mpi_options -app ./appfile_ccx |
/proc/sys/vm/drop_caches echo 1 > /proc/sys/vm/compact_memory echo 0 > /proc/sys/kernel/numa_balancing echo ‘always‘ > /sys/kernel/mm/transparent_hugepage/enabled echo ‘always‘ > /sys/kernel/mm/transparent_hugepage/defrag |
Thread Binding Options for AMD EPYC 7742/7763 Processor |
3 > /proc/sys/vm/drop_caches 1 > /proc/sys/kernel/numa_balancing |
A100 PCIE 40GB GPU,这款GPU采用Ampere架构,基于7nm制造工艺,包含了超过540亿个晶体管,拥有6912个CUDA核心,搭载了40GB
HBM2内存,具备1.6TB/s的内存带宽,FP64性能9.7 TFLOPS,FP32性能19.5
TFLOPS,FP16性能312 TFLOPS。
~/training_results_v1.0/NVIDIA/benchmarks/resnet/implementations /mxnet mlperf1.0-nvidia:image_classification . |
[1]="32-47,160-175" [2]="16-31,144-159" [3]="0-15,128-143" [4]="112-127,240-254" [5]="96-111,224-239" [6]="80-95,208-223" [7]="64-79,192-207") [1]="2" [2]="1" [3]="0" [4]="7" [5]="6" [6]="5" [7]="4") |
CONT=mlperf1.0-nvidia:image_classification DATADIR=/home/data/mxnet_imagenet/ LOGDIR=/home/resnet50/ |
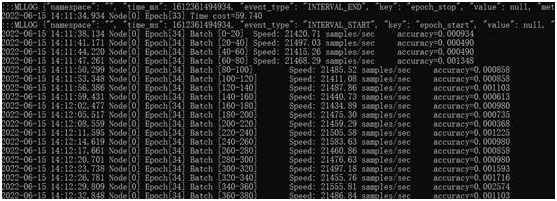
A100 40G GPU卡的服务器的最好成绩是36.2分钟。可以说,在同等GPU配置的服务器中,浪潮NF5468A5的ResNet50训练性能是最好的。
T4,这款精致的GPU卡只有75W,采用Turing架构, 在半高卡的尺寸内集成320个Turing Tensor Core和2560个Turing CUDA Core,配备16GB GDDR6,支持FP32/FP16/INT8/INT4等多种精度的运算,FP16的峰值性能为65T,INT8为130T,INT4为260T。

mlperf-inference-release.zip /mlperf-inference-release/closed/Inspur MLPERF_SCRATCH_PATH=/home/inspur/data/data_mlperf/ |
make run RUN_ARGS="--benchmark=resnet50 --scenarios=Offline --config_ver=default --test_mode=PerformanceOnly --fast" |
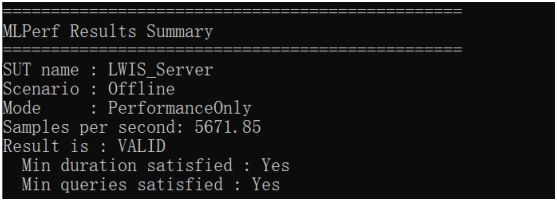


Ampere架构,采用8纳米工艺,拥有10496个CUDA核心,搭载了24 GB GDDR6X内存,384bit位宽。

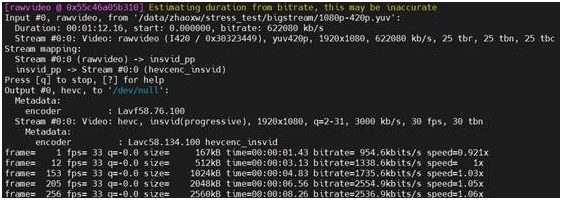
1080P视频转码性能。浪潮NF5468A5还有很多意想不到的潜能,笔者期待进一步的发掘,给大家带来更精彩的评测。

评论