
【数学基础】算法工程师必备的机器学习--线性模型(下)
作者信息:
华校专,曾任阿里巴巴资深算法工程师、智易科技首席算法研究员,现任腾讯高级研究员,《Python 大战机器学习》的作者。
编者按:
算法工程师必备系列更新啦!继上次推出了算法工程师必备的数学基础后,小编继续整理了必要的机器学习知识,全部以干货的内容呈现,哪里不会学哪里,老板再也不用担心你的基础问题!
第二章:线性模型
五、感知机
5.1 定义
感知机是二分类的线性分类模型,属于判别模型。
模型的输入为实例的特征向量,模型的输出为实例的类别:正类取值 +1, 负类取值-1。感知机的物理意义:将输入空间(特征空间)划分为正、负两类的分离超平面。 设输入空间(特征空间)为;输出空间为;输入 为特征空间的点;输出为实例的类别。
定义函数 为感知机。其中:
* 为权值向量, 为偏置。它们为感知机的参数。
sign为符号函数:感知机的几何解释: 对应特征空间 上的一个超平面 S ,称作分离超平面。
* 是超平面 S 的法向量, b 是超平面的截距。
超平面 S 上方的点判别为正类。 超平面 S 下方的点判别为负类。 超平面 S 将特征空间划分为两个部分:
5.2 损失函数
给定数据集,其中。
若存在某个超平面 S : , 使得将数据集中的正实例点与负实例点完全正确地划分到超平面的两侧,则称数据集 为线性可分数据集;否则称数据集 线性不可分。
划分到超平面两侧,用数学语言描述为:
根据感知机的定义:
1) 对正确分类的点
2) 对误分类的点
如果将感知机的损失函数定义成误分类点的中总数,则它不是 的连续可导函数,不容易优化。
因此,定义感知机的损失函数为误分类点到超平面 S 的总距离。
对误分类的点,则 距离超平面的距离为:
由于,以及,因此上式等于
不考虑
,则得到感知机学习的损失函数:其中:1) 为误分类点的集合。它隐式的与 相关,因为 优化导致误分类点减少从而使得 收缩。
2) 之所以不考虑因为感知机要求训练集线性可分,最终误分类点数量为零,此时损失函数为零。即使考虑分母,也是零。若训练集线性不可分,则感知机算法无法收敛。3) 误分类点越少或者误分类点距离超平面S 越近, 则损失函数 L 越小。
对于特定的样本点,其损失为:
因此给定训练集 ,损失函数 的连续可导函数。
若正确分类,则损失为 0 。 若误分类,则损失为 的线性函数。
5.3 学习算法
给定训练集 ,求参数:
5.3.1 原始形式
假设误分类点集合 是固定的,则损失函数 的梯度为:
通过梯度下降法,随机选取一个误分类点进行更新:
其中 是步长,即学习率。
通过迭代可以使得损失函数 不断减小直到 0 。
感知机学习算法的原始形式:
1) 输入:
a) 线性可分训练集
b) 学习率
2) 输出:
a) 感知机模型:
3) 步骤:
a) 选取初始值 。
b) 在训练集中选取数据 。若 则:
c)在训练集中重复选取数据来更新 直到训练集中没有误分类点。
5.3.2 性质
对于某个误分类点 ,假设它被选中用于更新参数。
则:
假设迭代之前,分类超平面为 ,该误分类点距超平面的距离为 。 假设迭代之后,分类超平面为 ,该误分类点距超平面的距离为 。
因此有 。这里要求,因此步长 要相当小。
几何解释 :当一个实例点被误分类时,调整 使得分离平面向该误分类点的一侧移动,以减少该误分类点与超平面间的距离,直至超平面越过所有的误分类点以正确分类。
感知机学习算法由于采用不同的初值或者误分类点选取顺序的不同,最终解可以不同。
5.3.3 收敛性
感知机收敛性定理:设线性可分训练集
1) 存在满足 的超平面: ,该超平面将 完全正确分开。且存在 ,对所有的 ,N 有:
其中 $2) 令,则感知机学习算法原始形式在 上的误分类次数 满足:
感知机收敛性定理说明了:
1) 当训练集线性可分时,感知机学习算法原始形式迭代是收敛的。
此时算法存在许多解,既依赖于初值,又依赖于误分类点的选择顺序。
为了得出唯一超平面,需要对分离超平面增加约束条件。
2) 当训练集线性不可分时,感知机学习算法不收敛,迭代结果会发生震荡。
5.3.4 对偶形式
根据原始迭代形式 :取初始值 均为 0。则 可以改写为:
这就是感知机学习算法的对偶形式。
感知机学习算法的对偶形式:
1) 输入:
线性可分训练集
学习率
2) 输出:
,其中。 感知机模型。
3) 步骤:
初始化: 。
在训练集中随机选取数据 ,若则更新:
在训练集中重复选取数据来更新 直到训练集中没有误分类点。
在对偶形式中, 训练集 仅仅以内积的形式出现,因为算法只需要内积信息。
可以预先将 中的实例间的内积计算出来,并以矩阵形式存储。即
Gram矩阵:与原始形式一样,感知机学习算法的对偶形式也是收敛的,且存在多个解。
第三章:支持向量机
支持向量机(
support vector machines:SVM)是一种二分类模型。它是定义在特征空间上的、间隔最大的线性分类器。间隔最大使得支持向量机有别于感知机。
如果数据集是线性可分的,那么感知机获得的模型可能有很多个,而支持向量机选择的是间隔最大的那一个。
支持向量机还支持核技巧,从而使它成为实质上的非线性分类器。
支持向量机支持处理线性可分数据集、非线性可分数据集。
当训练数据线性可分时,通过硬间隔最大化,学习一个线性分类器,即线性可分支持向量机(也称作硬间隔支持向量机)。 当训练数据近似线性可分时,通过软间隔最大化,学习一个线性分类器,即线性支持向量机(也称为软间隔支持向量机)。 当训练数据不可分时,通过使用核技巧以及软间隔最大化,学习一个非线性分类器,即非线性支持向量机。 当输入空间为欧氏空间或离散集合、特征空间为希尔伯特空间时,将输入向量从输入空间映射到特征空间,得到特征向量。支持向量机的学习是在特征空间进行的。
特征向量之间的内积就是核函数,使用核函数可以学习非线性支持向量机。 非线性支持向量机等价于隐式的在高维的特征空间中学习线性支持向量机,这种方法称作核技巧。 线性可分支持向量机、线性支持向量机假设这两个空间的元素一一对应,并将输入空间中的输入映射为特征空间中的特征向量。
非线性支持向量机利用一个从输入空间到特征空间的非线性映射将输入映射为特征向量。
欧氏空间是有限维度的,希尔伯特空间为无穷维度的。
欧式空间,具有很多美好的性质。
若不局限于有限维度,就来到了希尔伯特空间。
如果再进一步去掉完备性,就来到了内积空间。
如果再进一步去掉"角度"的概念,就来到了赋范空间。此时还有“长度”和“距离”的概念。
欧式空间希尔伯特空间 内积空间 赋范空间。
从有限到无限是一个质变,很多美好的性质消失了,一些非常有悖常识的现象会出现。
越抽象的空间具有的性质越少,在这样的空间中能得到的结论就越少
如果发现了赋范空间中的某些性质,那么前面那些空间也都具有这个性质。
一、 线性可分支持向量机
给定一个特征空间上的训练数据集 ,其中
为第 i 个特征向量,也称作实例; 为 的类标记;称作样本点。
当 时,称 为正例。
当 时,称 为负例。
假设训练数据集是线性可分的,则学习的目标是在特征空间中找到一个分离超平面,能将实例分到不同的类。
分离超平面对应于方程 , 它由法向量 和截距 决定,可以用 来表示。
给定线性可分训练数据集,通过间隔最大化学习得到的分离超平面为: ,
相应的分类决策函数:,称之为线性可分支持向量机。
当训练数据集线性可分时,存在无穷个分离超平面可以将两类数据正确分开。
感知机利用误分类最小的策略,求出分离超平面。但是此时的解有无穷多个。
线性可分支持向量机利用间隔最大化求得最优分离超平面,这样的解只有唯一的一个。
1.1 函数间隔
可以将一个点距离分离超平面的远近来表示分类预测的可靠程度:
一个点距离分离超平面越远,则该点的分类越可靠。 一个点距离分离超平面越近,则该点的分类则不那么确信。 在超平面 确定的情况下:
1) 能够相对地表示点 距离超平面的远近。
2) 的符号与类标记 的符号是否一致能表示分类是否正确
时,即 位于超平面上方,将 预测为正类。
此时若 则分类正确;否则分类错误。
时,即 位于超平面下方,将 预测为负类。
此时若 则分类正确;否则分类错误。
可以用 来表示分类的正确性以及确信度,就是函数间隔的概念。
符号决定了正确性。 范数决定了确信度。 对于给定的训练数据集 和超平面
定义超平面 关于样本点 的函数间隔为: 定义超平面 关于训练集 的函数间隔为:超平面 关于 中所有样本点 的函数间隔之最小值: 。
1.2 几何间隔
如果成比例的改变 和 ,比如将它们改变为和,超平面 还是原来的超平面,但是函数间隔却成为原来的100倍。
因此需要对分离超平面施加某些约束,如归一化,令,使得函数间隔是确定的。此时的函数间隔成为几何间隔。
对于给定的训练数据集 和超平面
1) 定义超平面 关于样本点 的几何间隔为:
2) 定义超平面 关于训练集 的几何间隔为:超平面 关于 中所有样本点 的几何间隔之最小值: 。
由定义可知函数间隔和几何间隔有下列的关系:
1) 当 时,函数间隔和几何间隔相等。
2) 当超平面参数, 等比例改变时:
超平面并没有变化。 函数间隔也按比例改变。 几何间隔保持不变。
1.3 硬间隔最大化
支持向量机学习基本思想:求解能够正确划分训练数据集并且几何间隔最大的分离超平面。几何间隔最大化又称作硬间隔最大化。
对于线性可分的训练数据集而言,线性可分分离超平面有无穷多个(等价于感知机),但几何间隔最大的分离超平面是唯一的。
几何间隔最大化的物理意义:不仅将正负实例点分开,而且对于最难分辨的实例点(距离超平面最近的那些点),也有足够大的确信度来将它们分开。
求解几何间隔最大的分离超平面可以表示为约束的最优化问题:
考虑几何间隔和函数间隔的关系,改写问题为:
函数间隔 的大小并不影响最优化问题的解。
假设将 按比例的改变为,此时函数间隔变成 (这是由于函数间隔的定义):
因此取,则最优化问题改写为:
这一变化对求解最优化问题的不等式约束没有任何影响。 这一变化对最优化目标函数也没有影响。 注意到和 是等价的,于是最优化问题改写为:
这是一个凸二次规划问题。
凸优化问题,指约束最优化问题:
其中:
1) 目标函数 和约束函数 都是 上的连续可微的凸函数。
2) 约束函数 是 上的仿射函数。
称为仿射函数,如果它满足
当目标函数 是二次函数且约束函数 是仿射函数时,上述凸最优化问题成为凸二次规划问题。
线性可分支持向量机原始算法:
求得最优解
由此得到分离超平面: ,以及分类决策函数 : 。
输入:线性可分训练数据集 ,
其中输出:
最大几何间隔的分离超平面
分类决策函数
算法步骤:
构造并且求解约束最优化问题:
可以证明:若训练数据集 线性可分,则可将训练数据集中的样本点完全正确分开的最大间隔分离超平面存在且唯一。
1.4 支持向量
在训练数据集线性可分的情况下,训练数据集的样本点中与分离超平面距离最近的样本点的实例称为支持向量。
支持向量是使得约束条件等号成立的点,即:
对于正实例点,支持向量位于超平面 对于负实例点,支持向量位于超平面 超平面 、 称为间隔边界, 它们和分离超平面 平行,且没有任何实例点落在 、 之间。
在、之间形成一条长带,分离超平面位于长带的中央。长带的宽度称为 、 之间的距离,也即间隔,间隔大小为 。
在决定分离超平面时,只有支持向量起作用,其他的实例点并不起作用。
如果移动支持向量,将改变所求的解。 如果在间隔边界以外移动其他实例点,甚至去掉这些点,则解是不变的。 由于支持向量在确定分离超平面中起着决定性作用,所以将这种分离模型称为支持向量机。
支持向量的个数一般很少,所以支持向量机由很少的、重要的训练样本确定。
1.5 对偶算法
将线性可分支持向量机的最优化问题作为原始最优化问题,应用拉格朗日对偶性,通过求解对偶问题得到原始问题的最优解。这就是线性可分支持向量机的对偶算法。
对偶算法的优点:
对偶问题往往更容易求解。 引入了核函数,进而推广到非线性分类问题。 原始问题:
定义拉格朗日函数:
其中 为拉格朗日乘子向量。
根据拉格朗日对偶性,原始问题的对偶问题是极大极小问题:
先求。拉格朗日函数分别为 求偏导数,并令其等于 0
代入拉格朗日函数:
对偶问题极大值为:
设对偶最优化问题的 的解为,则根据 `KKT` 条件有:
根据第三个式子,此时必有。同时考虑到,得到 :
分类决策函数写作: 。
上式称作线性可分支持向量机的对偶形式。
可以看到:分类决策函数只依赖于输入 和训练样本的内积。
于是分离超平面写作: 。 根据第一个式子,有: 。
由于 不是零向量(若它为零向量,则 也为零向量,矛盾),则必然存在某个 使得。
线性可分支持向量机对偶算法:
最大几何间隔的分离超平面
分类决策函数
1、构造并且求解约束最优化问题:
求得最优解 。
2、 计算 。
3、 选择 的一个正的分量 ,计算 。
4、 由此得到分离超平面: ,以及分类决策函数 :
算法步骤: 输入:线性可分训练数据集
输出:
只依赖于 对应的样本点 ,而其他的样本点对于 没有影响。
1) 将训练数据集里面对应于 的样本点对应的实例 称为支持向量。
2) 对于 的样本点,根据 ,有:
即 一定在间隔边界上。这与原始问题给出的支持向量的定义一致。
二、线性支持向量机
对于线性不可分训练数据,线性支持向量机不再适用,但可以想办法将它扩展到线性不可分问题。
2.1 原始问题
设训练集为 ,其中 。假设训练数据集不是线性可分的,这意味着某些样本点 不满足函数间隔大于等于 1 的约束条件。
即约束条件变成了:。
这里 称作惩罚参数,一般由应用问题决定。
1、 C 值大时,对误分类的惩罚增大,此时误分类点凸显的更重要
2、 C 值较大时,对误分类的惩罚增加,此时误分类点比较重要。3、 C 值较小时,对误分类的惩罚减小,此时误分类点相对不重要。对每个松弛变量 ,支付一个代价。目标函数由原来的变成: 对每个样本点 引进一个松弛变量,使得函数间隔加上松弛变量大于等于 1。 相对于硬间隔最大化,称为软间隔最大化。
于是线性不可分的线性支持向量机的学习问题变成了凸二次规划问题:
1) 这称为线性支持向量机的原始问题。
2) 因为这是个凸二次规划问题,因此解存在。
可以证明 的解是唯一的; 的解不是唯一的, 的解存在于一个区间。
对于给定的线性不可分的训练集数据,通过求解软间隔最大化问题得到的分离超平面为: ,
以及相应的分类决策函数: ,称之为线性支持向量机。线性支持向量机包含线性可分支持向量机。现实应用中训练数据集往往是线性不可分的,线性支持向量机具有更广泛的适用性。
2.2 对偶问题
定义拉格朗日函数为:
原始问题是拉格朗日函数的极小极大问题;对偶问题是拉格朗日函数的极大极小问题。
1) 先求 对的极小。根据偏导数为0:
得到:2) 再求极大问题:将上面三个等式代入拉格朗日函数:
于是得到对偶问题:
根据
KKT条件:则有: 。
1) 若存在 的某个分量,则有:。
若 的所有分量都等于 0 ,则得出 为零,没有任何意义。若 的所有分量都等于 C,根据,则要求。这属于强加的约束,
1、 根据 ,有。 2、 考虑 ,则有:2) 分离超平面为: 。
3) 分类决策函数为: 。
线性支持向量机对偶算法:
4) 输入:训练数据集 ,其中
5) 输出:
分离超平面
分类决策函数
求得最优解 。
1、 计算: 。
2、 选择 的一个合适的分量,计算: 。
可能存在多个符合条件的。这是由于原始问题中,对 b 的解不唯一。所以
实际计算时可以取在所有符合条件的样本点上的平均值。
3、 由此得到分离超平面:,以及分类决策函数: 。
选择惩罚参数 ,构造并且求解约束最优化问题: 算法步骤:
2.3 支持向量
在线性不可分的情况下,对偶问题的解 中,对应于 的样本点 的实例点 称作支持向量,它是软间隔的支持向量。
线性不可分的支持向量比线性可分时的情况复杂一些:
根据,以及,则:
1) 若 ,则, 则松弛量。此时:支持向量恰好落在了间隔边界上。
2) 若, 则,于是 可能为任何正数:
1、 若,则支持向量落在间隔边界与分离超平面之间,分类正确。2、 若,则支持向量落在分离超平面上。3、 若,则支持向量落在分离超平面误分类一侧,分类错误。
2.4 合页损失函数
定义取正函数为:
定义合页损失函数为: ,其中 为样本的标签值, 为样本的模型预测值。
则线性支持向量机就是最小化目标函数:
合页损失函数的物理意义:
1) 当样本点 被正确分类且函数间隔(确信度) 大于 1 时,损失为0
2) 当样本点 被正确分类且函数间隔(确信度) 小于等于 1 时损失为
当样本点 未被正确分类时损失为 可以证明:线性支持向量机原始最优化问题等价于最优化问题:
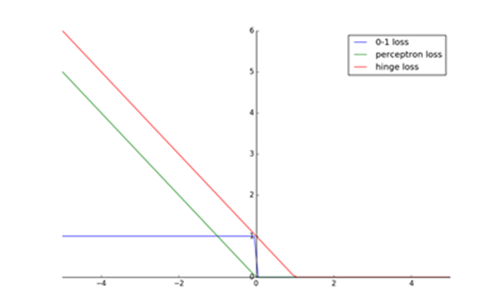
合页损失函数图形如下:
因为0-1损失函数不是连续可导的,因此直接应用于优化问题中比较困难。 通常都是用0-1损失函数的上界函数构成目标函数,这时的上界损失函数又称为代理损失函数。 感知机的损失函数为,相比之下合页损失函数不仅要分类正确,而且要确信度足够高(确信度为1)时,损失才是0。即合页损失函数对学习有更高的要求。
0-1损失函数通常是二分类问题的真正的损失函数,合页损失函数是0-1损失函数的上界。
理论上
SVM的目标函数可以使用梯度下降法来训练。但存在三个问题:合页损失函数部分不可导。这可以通过 sub-gradient descent来解决。收敛速度非常慢。 无法得出支持向量和非支持向量的区别。
往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/662nyZF
本站qq群704220115。
加入微信群请扫码进群(如果是博士或者准备读博士请说明):