摘要:本文作者洪志龙(柏星)& 朱翥(长耕),分享了如何在 Flink 1.13 版本和 1.14 版本中对 Flink 调度大规模作业的性能进行了优化。主要内容包括:- 针对 Pipelined Region 构建的优化
Tips:点击「阅读原文」查看 FFA 2021 视频回放~随着 Flink 流批一体架构不断演进和升级,越来越多的用户开始选择用 Flink 来同时承载实时和离线的业务。离线业务和实时业务有一定差异性,其中比较关键的一点是 —— 离线作业的规模通常都远远大于实时作业。超大规模的流批作业对 Flink 的调度性能提出了新的挑战。在基于 Flink 1.12 版本部署大规模流批作业时,用户可能会遇到以下瓶颈:
- 需要大量内存来存储作业的执行拓扑图以及部署时所需的临时变量,并且在运行过程中会出现频繁的长时间 GC,影响集群稳定性;
经测试,对于一个并发度为 10k 的 word count 作业,在其部署时 JobManager 需要 30 GiB 内存,并且从提交作业到所有任务节点部署完毕所需的总时间长达 4 分钟。此外,对于大规模作业,任务部署的过程可能会长时间阻塞 JobManager 的主线程。当主线程阻塞时,JobManager 无法响应任何来自 TaskManager 的请求。这会使得 TaskManager 心跳超时进而导致作业出错失败。在最坏的情况下,作业从故障恢复 (Failover) 并进行新一轮部署时又会出现心跳超时,从而导致作业一直卡在部署阶段无法正常运行。为了优化 Flink 调度大规模作业的性能,我们在 Flink 1.13 版本和 1.14 版本进行了以下优化:
- 针对拓扑结构引入分组概念,优化与拓扑相关的计算逻辑,主要包括作业初始化、Task 调度以及故障恢复时计算需要重启的 Task 节点等等。与此同时,该优化降低了执行拓扑占用的内存空间;
- 引入缓存机制优化任务部署,优化后部署速度更快且所需内存更少;
- 基于逻辑拓扑和执行拓扑的特性进行优化以加快 Pipelined Region 的构建速度,从而降低作业初始化所需的时间。
为了评估优化的效果,我们对 Flink 1.12 (优化前) 和 Flink 1.14 (优化后) 进行了对比测试。测试作业包含两个节点,由全连接边相连,并发度均为 10k。为了通过 blob 服务器分发 ShuffleDescriptor,我们将配置项 blob.offload.minsize 的值修改为 100 KiB。该配置项指定了通过 blob 服务器传输数据的最小阈值,大小超过该阈值的数据将会通过 Blob 服务器进行传输。该配置项的默认值为 1 MiB,而测试作业中节点的 ShuffleDescriptor 大小约为 270 KiB。测试结果如表 1 所示:表 1 Flink 1.12 和 1.14 各流程时间对比
| 1.12
| 1.14
| 时间降低百分比(%) |
作业初始化
| 11,431ms | 627ms | 94.51% |
任务部署
| 63,118ms | 17,183ms | 72.78% |
故障恢复时计算重启节点
| 37,195ms | 170ms | 99.55% |
除了时间大幅缩短以外,内存占用也明显降低。在 Flink 1.12 版本上运行测试作业时,JobManager 需要 30 GiB 内存才能保证作业稳定运行,而在 Flink 1.14 版本上只需要 2 GiB 即可。与此同时,GC 情况也得以改善。在 1.12 版本上,测试作业在初始化和 Task 部署的过程中都会出现超过 10 秒的长 GC,而在 1.14 版本上均未出现,这意味着心跳超时等问题出现的概率更低,作业运行更为稳定。在 1.12 版本上,除去申请资源的时间,测试作业需要至少 4 分钟才能部署完成。而作为对比,在 1.14 版本上,除去申请资源的时间,测试作业在 30 秒内即可完成部署并开始运行。整体所需时间降低了 87%。鉴于此,对于需要部署运行大规模作业的用户,建议将 Flink 版本升级至 1.14 以提升作业调度和部署性能。
在 Flink 中,分发模式 (Distribution Pattern) 描述了上游节点与下游节点连接的方式,上游节点计算的结果会按照连边分发到下游节点。目前 Flink 中有两种分发模式:点对点 (Pointwise) 和全连接 (All-to-all)。如图 1 所示,当分发模式为点对点时,遍历所有边的计算复杂度为 O(N);当分发模式为全连接时,所有下游节点与上游节点都有连边,遍历所有边的计算复杂度为 O(N2),所需时间会随着规模增大而迅速增长。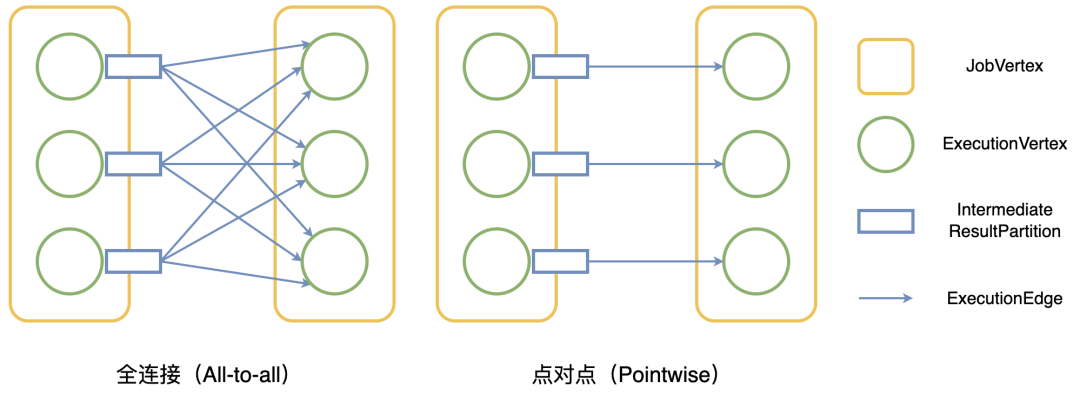
图 1 目前 Flink 的两种分发模式
Flink 1.12 版本使用执行拓扑边 (ExecutionEdge) 存储任务节点间连接的信息。当分发模式为全连接模式时,节点间一共会有 O(N2) 条边相连,当作业规模较大时会占用大量内存。对于两个全连接边相连且并发度为 10k 的节点,其连边数量为 1 亿,总共需要超过 4 GiB 内存来存储这些连边。在生产作业中可能会有多个全连接边相连的节点,这也就意味着随着作业规模的增长,所需内存也会大幅增长。从图 1 可以看到,对于全连接边相连的任务节点,所有上游节点所产生的结果分区 (Result Partition) 都是同构的,也就是说这些结果分区所连接的下游任务节点都是完全相同的。全连接边相连的所有下游节点也都是同构的,因为其所消费的上游分区都是相同的。鉴于节点间的 JobEdge 只有一种分发模式,我们可以按照分发模式对上游分区以及下游节点进行分组。对于全连接边,由于其所有下游节点都是同构的,我们可以将这些下游节点划分为一组,称为节点组 (ConsumerVertexGroup),全连接边相连的所有上游分区都与这个组连接。同样,所有同构的上游分区也被划分为同一组,称为分区组 (ConsumedPartitionGroup),全连接边相连的所有下游节点都与这个组相连。优化方案的基本思路为:将所有消费相同结果分区的下游节点放入同一个节点组中,同时将所有与相同下游节点相连的结果分区放入同一个分区组中,如图 2 所示。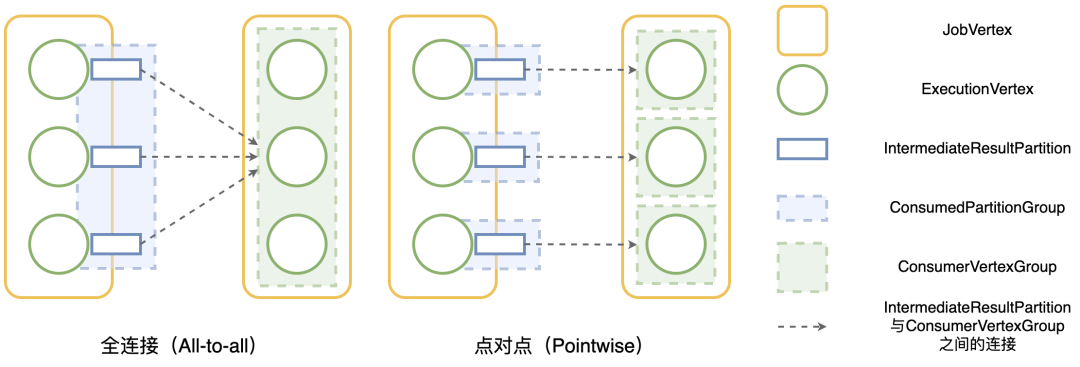
图 2 两种分发模式下如何对结果分区和任务节点进行分组在调度任务节点时,Flink 需要遍历每一个上游分区和下游节点间的所有连边。在优化前,由于连边的总数量为 O(N2),因此将所有边遍历一遍的总时间复杂度为 O(N2)。优化后,执行拓扑边被分组的概念所替代。鉴于所有同构的分区都连接到同一个下游节点组,当 Flink 需要遍历所有连边时,只需要将该节点组遍历一遍即可,不需要重复遍历所有节点,这样就使得计算复杂度从 O(N2) 降到 O(N)。对于点对点的分发模式,上游结果分区与下游节点逐一相连,因此分区组和节点组之间也是点对点相连,分组的数量级和执行拓扑边的数量级是一样的,也就是说,遍历所有连边的计算复杂度依旧是 O(N)。对于上文我们提到的 word count 作业,采用上述的分组方式取代执行拓扑边可以将执行拓扑的内存占用从 4 GiB 降至 12 MiB 左右。基于分组的概念,我们对作业初始化、任务调度以及故障恢复时计算需要重启的节点等耗时较长的计算逻辑进行了优化。这些计算逻辑都涉及到对上下游之间所有连边进行遍历的操作。在优化后,其计算复杂度都从 O(N2) 降为 O(N)。
对于 Flink 1.12 版本,当大规模作业内包含全连接边时,部署所有节点需要花费很长时间。此外,在部署过程中容易出现 TaskManager 心跳超时的情况,进而导致集群不稳定。目前任务部署包含以下几个阶段:
- JobManager 在主线程内为每一个 Task 创建任务部署描述符 (TaskDeploymentDescriptor,以下简称 TDD);
- JobManager 在异步线程内将这些 TDD 进行序列化;
- JobManager 通过 RPC 通信将序列化后的 TDD 发送至 TaskManager;
- TaskManager 基于 TDD 创建任务并执行。
TDD 包含了 TaskManager 创建任务 (Task) 时所需的所有信息。当任务部署开始时,JobManager 会在主线程内为所有任务节点创建 TDD。在创建过程中 JobManager 无法响应任何其他请求。对于大规模作业,这一过程可能会导致 JobManager 主线程长时间被阻塞,进一步导致心跳超时,从而触发作业故障。鉴于任务部署时所有 TDD 都是由 JobManager 负责发送至各 TaskManager,这导致 JobManager 可能会成为性能瓶颈。尤其是对于大规模作业,部署时产生的 TDD 会占用大量内存空间,导致频繁的长时间 GC,进一步加重 JobManager 的负担。因此,我们需要缩短创建 TDD 所需的时间,避免心跳超时的发生。此外,如果能够缩减 TDD 的大小,网络传输所需的时间也会缩短,这样可以进一步加快任务部署的速度。3.1 为 ShuffleDescriptor 添加缓存机制
ShuffleDescriptor 用于描述任务在运行时需要消费的上游结果分区的所有信息。当作业规模较大时,ShuffleDescriptor 可能是 TDD 中所占空间最大的一部分。对于全连接边相连的节点,当上游节点和下游节点的并发度都是 N 时,每一个下游节点需要消费 N 个上游结果分区,此时 ShuffleDescriptor 的总数量是 N2。也就是说,计算所有节点的 ShuffleDescriptor 的时间复杂度为 O(N2)。然而,对于同构的下游节点来说,他们所消费的上游结果分区是完全一样的,因此部署时所需要的 ShuffleDescriptor 内容也是一样的。鉴于此,在部署时不需要为每一个下游节点重复计算 ShuffleDescriptor,只需要将计算好的 ShuffleDescriptor 放入缓存以供复用即可。这样计算 TDD 的时间复杂度就可以从 O(N2) 降至 O(N)。为了缩减 RPC 消息的大小,进而降低网络传输的开销,我们可以对 ShuffleDescriptor 进行压缩。对于上文我们提到的 word count 作业,当节点并发度为 10k 时,每一个下游节点都会有 10k 个 ShuffleDescriptor,在压缩后其序列化值的总大小降低了 72%。3.2 通过 Blob 服务器分发 ShuffleDescriptor
Blob (Binary Large Object) 以二进制数据的形式存储大型文件。Flink 通过 blob 服务器在 JobManager 和 TaskManager 之间传输体积较大的文件。当 JobManager 需要将大文件传输至 TaskManager 时,它可以将文件传输至 blob 服务器 (同时会将文件传输至分布式文件系统),并且获得访问文件所需的 token。当 TaskManager 获取到 token 时,它们会从分布式文件系统 (Distributed File System,DFS) 下载文件。TaskManager 会同时将文件存储到本地 blob 缓存中方便之后重复读取。在任务部署的过程中,JobManager 负责将 ShuffleDescriptor 通过 RPC 消息分发到对应的 TaskManager 中。在发送完成后,RPC 消息会被垃圾回收器回收处理。但当 JobManager 创建 RPC 消息的速度大于发送的速度时,RPC 消息会逐渐堆积在内存中并且对 GC 造成影响,频繁触发长时间的 GC。这些 GC 会导致 JobManager 停摆,进一步拖慢任务部署的速度。为了解决这个问题,Flink 可以通过 blob 服务器来分发大体积的 ShuffleDescriptor。首先 JobManager 将 ShuffleDescriptor 发送至 blob 服务器,而 blob 服务器会将 ShuffleDescriptor 存储至 DFS 中,TaskManager 在开始处理 TDD 时会从 DFS 下载数据。这样 JobManager 不需要将所有 ShuffleDescriptor 始终存储在内存中直至对应的 RPC 消息发出。经过优化后,在部署大规模作业时长时间 GC 的频率会明显降低。且鉴于 DFS 为 TaskManager 提供了多个分布式节点下载数据,JobManager 网络传输的压力也得以缓解,不再成为瓶颈,这样可以加快任务部署的速度。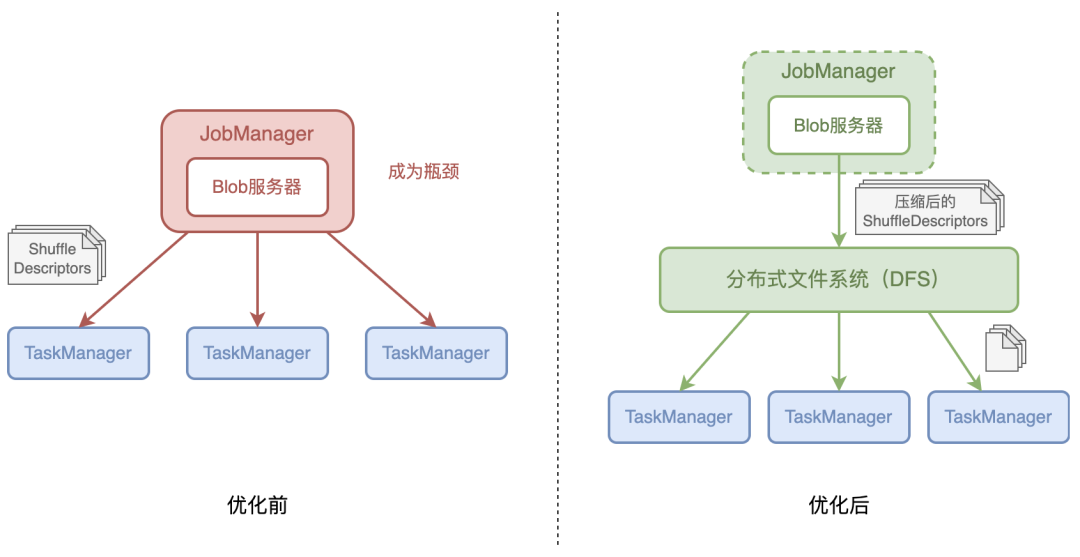
图 3 JobManager 将 ShuffleDescriptor 分发至 TaskManager为了避免缓存过多导致本地磁盘空间不足,当 ShuffleDescriptor 所对应的结果分区被释放时,在 blob 服务器上存储的对应缓存会被清理。此外我们为 TaskManager 上 ShuffleDescriptor 的缓存添加了总大小的限制。当缓存超过一定大小时,缓存会按照最近最少使用 (LRU) 的顺序移除。这样可以保证本地磁盘不会被缓存占满,特别是对于 session 模式运行的集群。四、针对 Pipelined Region 构建的优化
目前 Flink 中节点间有两种数据交换类型:pipelined 和 blocking。对于 blocking 的数据交换方式,结果分区会在上游全部计算完成后再交由下游进行消费,数据会持久化到本地,支持多次消费。对于 pipelined 数据交换,上游结果分区的产出和下游任务节点的消费是同时进行的,所有数据不会被持久化且只能读取一次。鉴于 pipelined 的数据流产出和消费同时发生,Flink 需要保证 pipelined 边相连的上下游节点同时运行。由 pipelined 边相连的节点构成了一个 region,被称为 Pipelined Region (以下简称 region)。在 Flink 中,region 是任务调度和 Failover 的基本单位。在调度的过程中,同一 region 内的所有 Task 节点都会被同时调度,而整个拓扑中所有 region 会按照拓扑顺序逐一进行调度。目前在 Flink 的调度层面有两种 region:逻辑层面的 Logical Pipelined Region 以及执行调度层面的 Scheduling Pipelined Region。逻辑 region 由逻辑拓扑 (JobGraph) 中的节点 JobVertex 构成,而执行 region 则由执行拓扑 (ExecutionGraph) 中的节点 ExecutionVertex 构成。类似于 ExecutionVertex 基于 JobVertex 计算产生,执行 region 是由逻辑 region 计算得到的,如图 4 所示。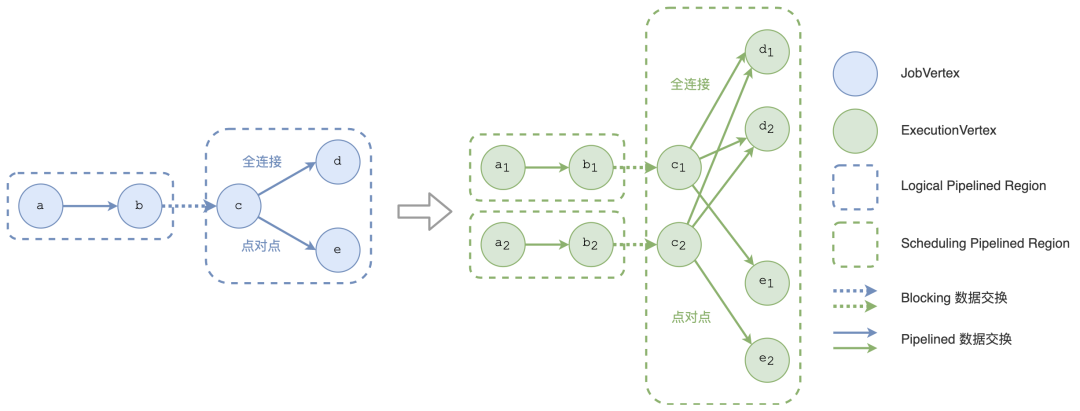
图 4 逻辑 region 以及执行 region在构建 region 的过程中会遇到一个问题:region 之间可能存在环形依赖。对于当前 region,当且仅当其所消费的上游 region 都产出全部数据后才能进行调度。如果两个 region 之间存在环形依赖,那么就会出现调度死锁:两个 region 都需要等对方完成才能调度,最终两个 region 都无法被调度起来。因此,Flink 通过 Tarjan 强连通分量算法来发现环形依赖,并将具有环形依赖的 region 合并成一个 region,这样就能解决调度死锁的问题。Tarjan 强连通分量算法需要遍历拓扑内的所有边,而对于全连接的分发模式来说,其边的数量为 O(N2),因此算法整体的计算复杂度为 O(N2),随着规模变大会显著增长,从而影响大规模作业初始化的时间。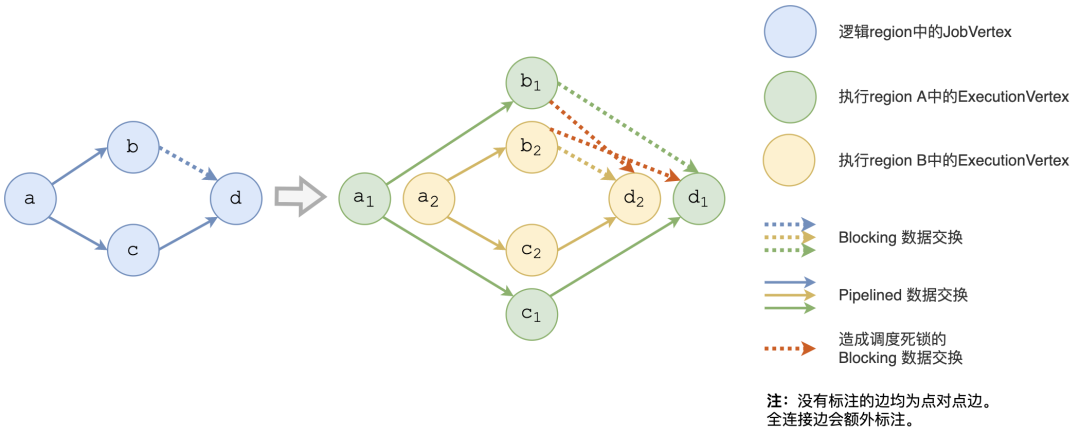
为了加快 region 的构建速度,我们可以基于逻辑拓扑和执行拓扑之间的关联进行优化。鉴于一个执行 region 只能由一个逻辑 region 中的节点派生,不会出现跨 region 的情况,Flink 在初始化作业时只需要遍历所有逻辑 region 并逐一转换成执行 region 即可。转换的方式跟分发模式相关。如果逻辑 region 内的节点间有任何全连接边,则整个逻辑 region 可以直接转换成一个执行 region。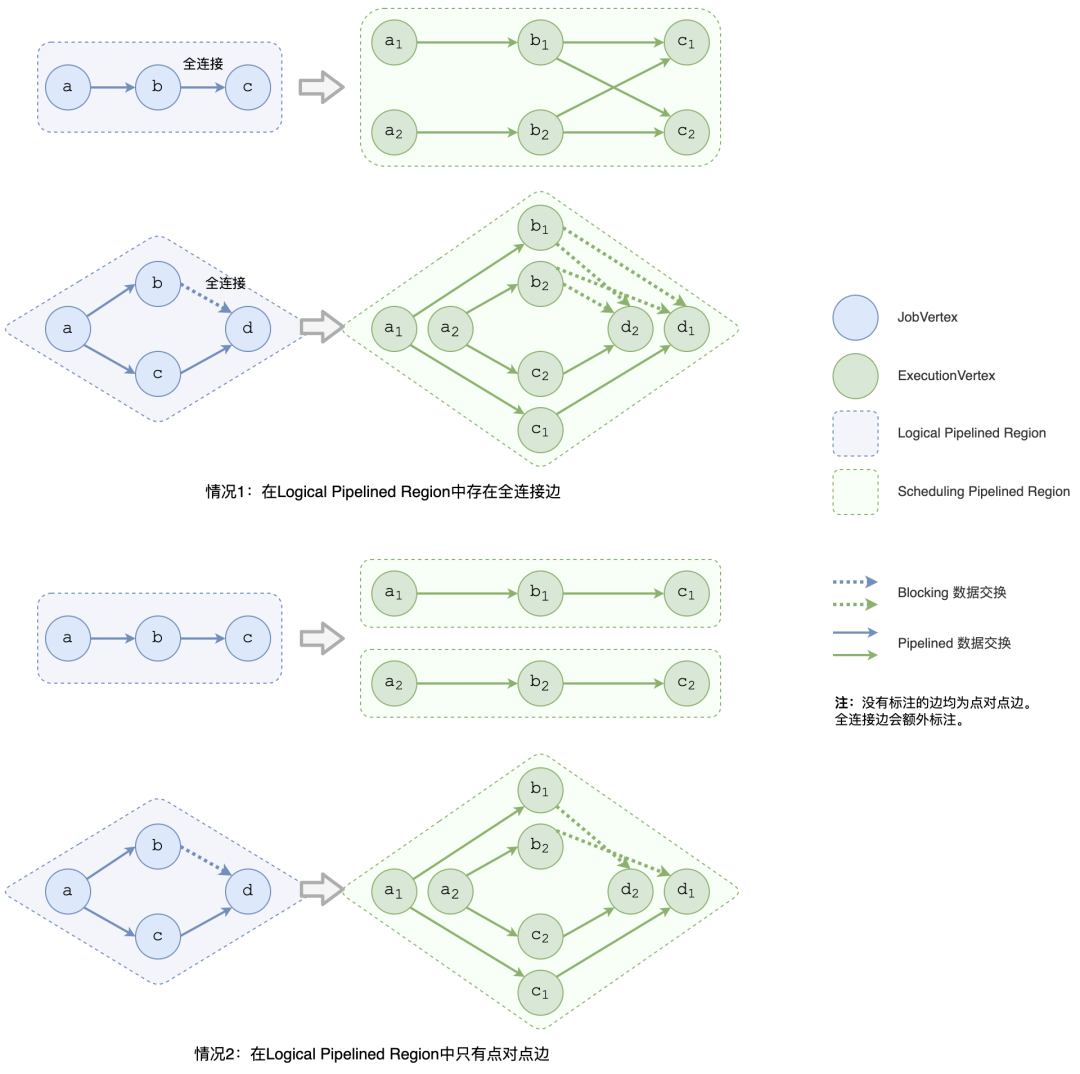
图 6 如何将逻辑 region 转换成执行 region如果全连接边采用的是 pipelined 数据交换,所有与之相连的上下游节点都必须同时运行,也就是说全连接边所连接的所有 region 都要合并成一个 region。如果全连接边采用的是 blocking 数据交换,则会引入环形依赖,如图 5 所示。在这种情况下所有与之相连的 region 都必须合并以避免调度死锁,如图 6 所示。鉴于只要有全连接边就直接生成一整个执行 region,在这种情况下不需要用 Tarjan 算法,整体计算复杂度只需要 O(N) 即可。如果在逻辑 region 内,所有节点间都只有点对点的分发模式,那么 Flink 依旧直接用 Tarjan 算法来检测环形依赖,鉴于点对点的分发模式其边数为 O(N),算法的时间复杂度也只有 O(N)。在优化后,将逻辑 region 转换成执行 region 的整体计算复杂度从 O(N2) 降为 O(N)。经测试,对于上文提到的 word count 作业,当两个节点间的连边为全连接边且数据交换方式为 blocking 时,构建 region 的总时间降低了 99%,从 8,257ms 降至 120ms。
FFA 2021 视频回放 & 演讲 PDF 获取
关注「Apache Flink」,回复:FFA2021
更多 Flink 相关技术问题,可扫码加入社区钉钉交流群~
 戳我,查看 FFA 2021 视频回放~
戳我,查看 FFA 2021 视频回放~
