
Flink 大规模作业调度性能优化
随着 Flink 流批一体架构不断演进和升级,越来越多的用户开始选择用 Flink 来同时承载实时和离线的业务。离线业务和实时业务有一定差异性,其中比较关键的一点是 —— 离线作业的规模通常都远远大于实时作业。超大规模的流批作业对 Flink 的调度性能提出了新的挑战。在基于 Flink 1.12 版本部署大规模流批作业时,用户可能会遇到以下瓶颈:
需要很长时间才能完成作业的调度和部署; 需要大量内存来存储作业的执行拓扑图以及部署时所需的临时变量,并且在运行过程中会出现频繁的长时间 GC,影响集群稳定性;
为了优化 Flink 调度大规模作业的性能,我们在 Flink 1.13 版本和 1.14 版本进行了以下优化:
针对拓扑结构引入分组概念,优化与拓扑相关的计算逻辑,主要包括作业初始化、Task 调度以及故障恢复时计算需要重启的 Task 节点等等。与此同时,该优化降低了执行拓扑占用的内存空间; 引入缓存机制优化任务部署,优化后部署速度更快且所需内存更少; 基于逻辑拓扑和执行拓扑的特性进行优化以加快 Pipelined Region 的构建速度,从而降低作业初始化所需的时间。
一、性能评测结果
1.12 | 1.14 | 时间降低百分比(%) | |
作业初始化 | 11,431ms | 627ms | 94.51% |
任务部署 | 63,118ms | 17,183ms | 72.78% |
故障恢复时计算重启节点 | 37,195ms | 170ms | 99.55% |
二、基于拓扑结构的优化
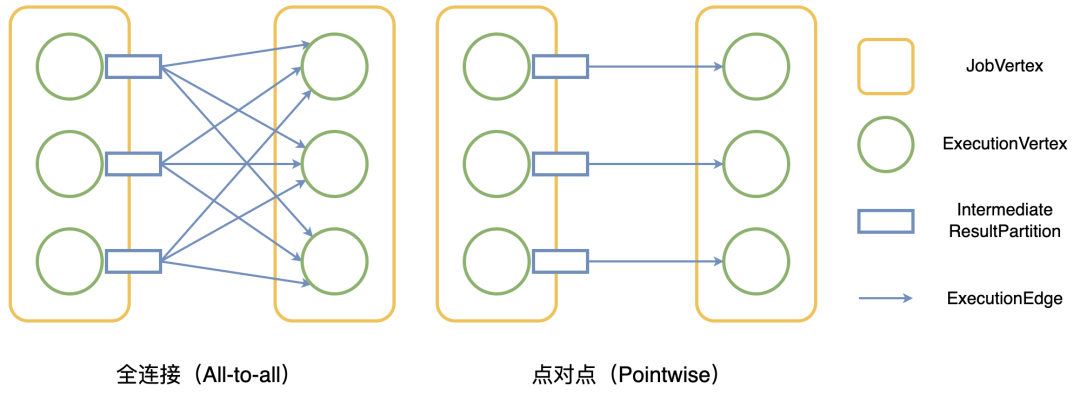
图 1 目前 Flink 的两种分发模式

三、优化任务部署
目前任务部署包含以下几个阶段:
JobManager 在主线程内为每一个 Task 创建任务部署描述符 (TaskDeploymentDescriptor,以下简称 TDD); JobManager 在异步线程内将这些 TDD 进行序列化; JobManager 通过 RPC 通信将序列化后的 TDD 发送至 TaskManager; TaskManager 基于 TDD 创建任务并执行。
3.1 为 ShuffleDescriptor 添加缓存机制
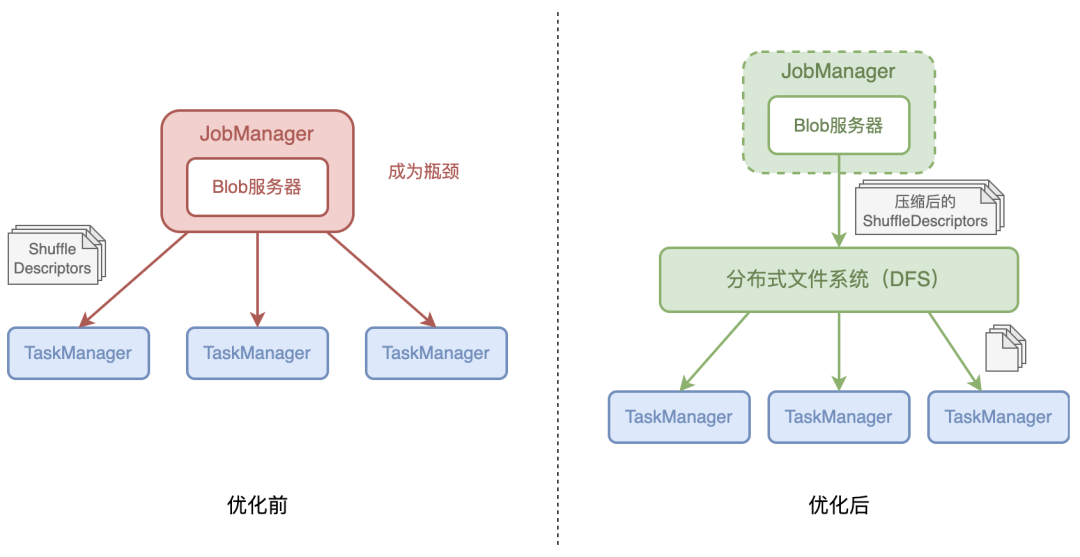
3.2 通过 Blob 服务器分发 ShuffleDescriptor
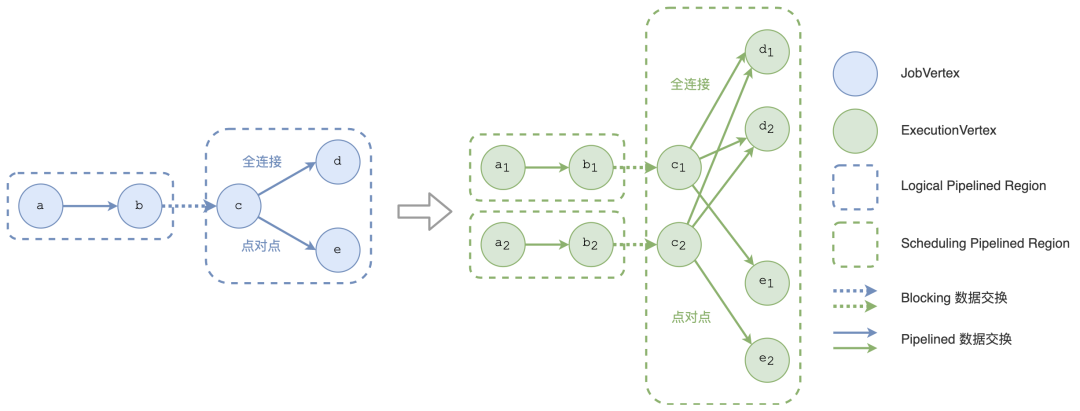
四、针对 Pipelined Region 构建的优化


评论