
Flink SQL 性能优化:multiple input 详解
优化案例解析:订单量统计
我们将以 TPC-DS q96 为例子详细介绍如何消除冗余 shuffle,该 SQL 意在通过多路 join 筛选并统计符合特定条件的订单量。
select count(*)from store_sales,household_demographics,time_dim, storewhere ss_sold_time_sk = time_dim.t_time_skand ss_hdemo_sk = household_demographics.hd_demo_skand ss_store_sk = s_store_skand time_dim.t_hour = 8and time_dim.t_minute >= 30and household_demographics.hd_dep_count = 5and store.s_store_name = 'ese'
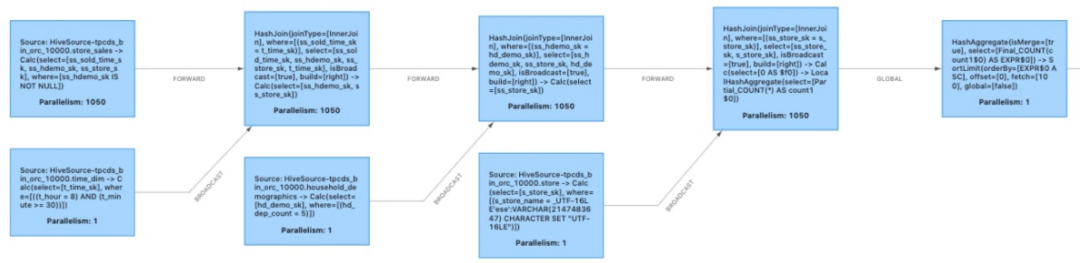
冗余 Shuffle 是如何产生的?
由于部分算子对输入数据的分布有要求(如 hash join 算子要求同一并发内数据 join key 的 hash 值相同),数据在算子之间传递时可能需要经过重新排布与整理。与 map-reduce 的 shuffle 过程类似,Flink shuffle 将上游 task 产生的中间结果进行整理,并按需发送给需要这些中间结果的下游 task。但在一部分情况下,上游产出的数据已经满足了数据分布要求(如连续多个 join key 相同的 hash join 算子),此时对数据的整理便不再必要,由此产生的 shuffle 也就成为了冗余 shuffle,在执行计划中以 forward shuffle 表示。
图 1 中的 hash join 算子是一种称为 broadcast hash join 的特殊算子。以 store_sales join time_dim 为例,由于 time_dim 表数据量很小,此时通过 broadcast shuffle 将该表的全量数据发送给 hash join 的每个并发,就能让任何并发接受 store_sales 表的任意数据而不影响 join 结果的正确性,同时提高 hash join 的执行效率。此时 store_sales 表向 join 算子的网络传输也成为了冗余 shuffle。同理几个 join 之间的 shuffle 也是不必要的。
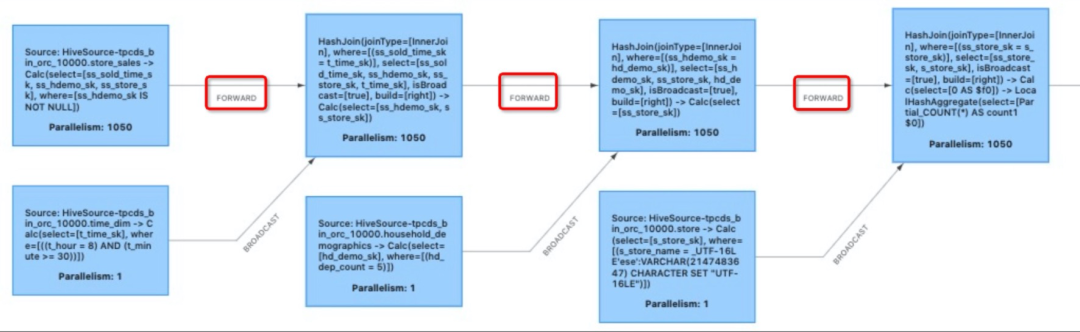
图 2 - 冗余的shuffle(红框标记)
Operator Chaining 能解决吗?
对 Flink 优化过程有一定了解的读者可能会知道,为了消除不必要的 forward shuffle,Flink 在早期就已经引入了 operator chaining 机制。该机制将并发相同的相邻单输入算子整合进同一个 task 中,并在同一个线程中一起运算。Operator chaining 机制在图 1 中其实已经在发挥作用,如果没有它,做 broadcast shuffle 的三个 Source 节点名称中被“->”分隔的算子将会被拆分至多个不同的 task,产生冗余的数据 shuffle。图 3 为 Operator chaining 关闭是的执行计划。

图 3 - Operator chaining关闭后的执行计划
多输入算子的解决方案:
Multiple Input Operator
如果我们能仿照 operator chaining 的优化思路,引入新的优化机制并满足以下条件:
该机制可以组合多输入的算子;
该机制支持多路输入(为被组合的算子提供输入)
我们就可以将用 forward shuffle 连接的的多输入算子放到一个 task 里执行,从而消除不必要的 shuffle。Flink 社区很早就关注到了 operator chaining 的不足,在 Flink 1.11 中引入了 streaming api 层的 MultipleInputTransformation 以及对应的 MultipleInputStreamTask。这些 api 满足了上述条件 2,而 Flink 1.12 在此基础上在 SQL 层中实现了满足条件 1 的新算子——multiple input operator,可以参考 FLIP 文档[1]。
Multiple input operator 是 table 层一个可插拔的优化。它位于 table 层优化的最后一步,遍历生成的执行计划并将不被 exchange 阻隔的相邻算子整合进一个 multiple input operator 中。图 4 展示了该优化对原本 SQL 优化步骤的修改。
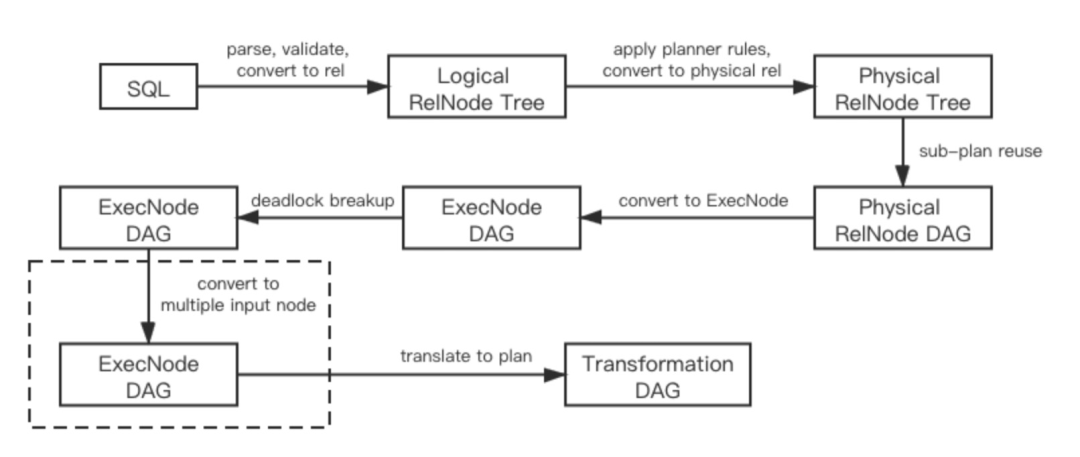
读者可能会有疑问:为什么不在现有的 operator chaining 上进行修改,而要另起炉灶呢?实际上,multiple input operator 除了要完成 operator chaining 的工作之外,还需要对各个输入的优先级进行排序。这是因为一部分多输入算子(如 hash join 与 nested loop join)对输入有严格的顺序限制,若输入优先级排序不当很可能造成死锁。由于算子输入优先级的信息仅在 table 层的算子中有描述,更加自然的方式是在 table 层引入该优化机制。
值得注意的是,multiple input operator 不同于管理多个 operator 的 operator chaining,其本身就是一整个大 operator,而其内部运算在外界看来就是一个黑盒。Multiple input operator 的内部结构在 operator name 中完全体现,读者在运行包含该 operator 的作业时,可以从 operator name 看到哪些算子以怎样的拓扑结构被组合进了 multiple input operator 中。
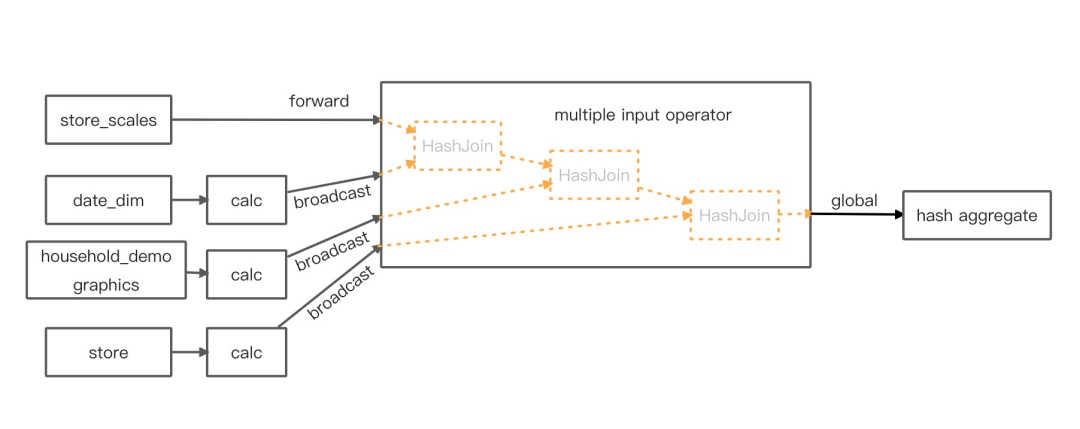
图 5 展示了经过 multiple input 优化后的算子的拓扑图以及 multiple input operator 的透视图。图中三个 hash join 算子之间的冗余的 shuffle 被移除后,它们可以在一个 task 里执行,只不过 operator chaining 没法处理这种多输入的情况,将它们放到 multiple input operator 里执行,由 multiple input operator 管理各个算子的输入顺序和算子之间的调用关系。
Source 也不能遗漏:Source Chaining
经过 multiple input operator 的优化,我们将图 1 中的执行计划优化为图 6,图 3 经过 operator chaining 优化后就变为图 6 的执行图。
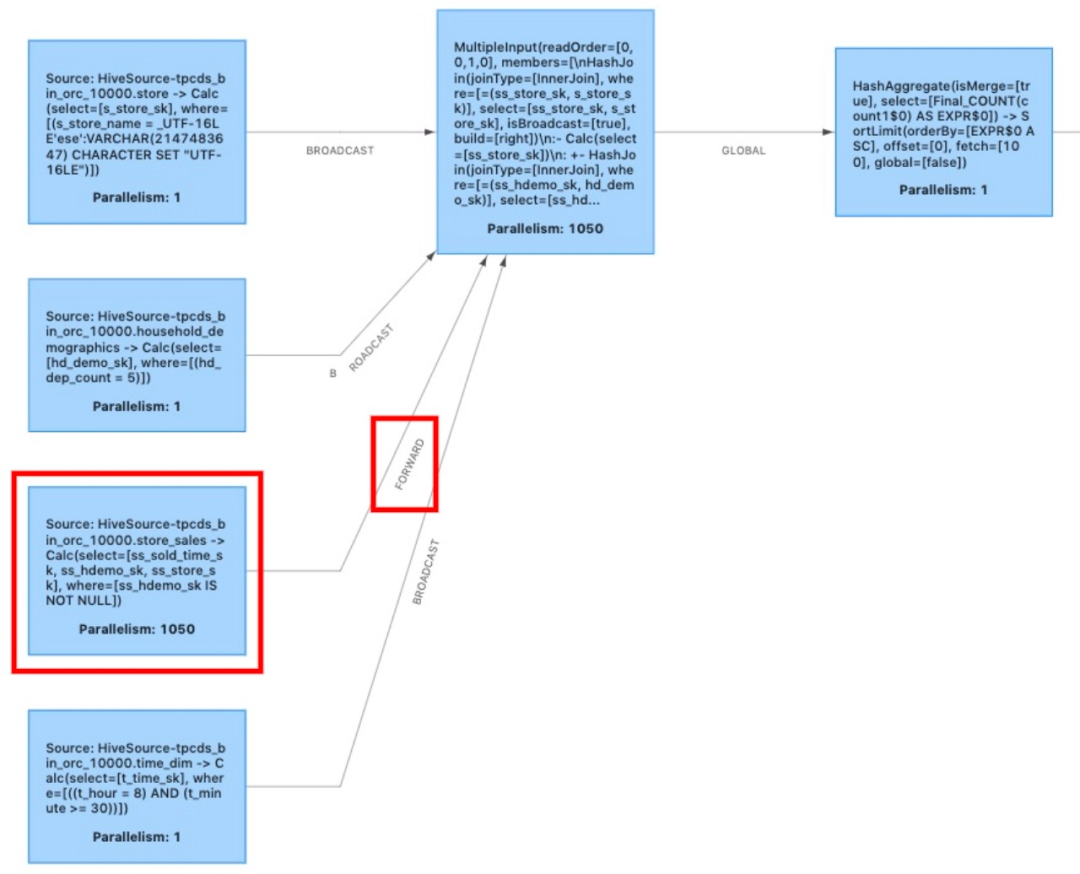
图 6 中从 store_sales 表产生的 forward shuffle(如红框所示)表示我们仍有优化空间。正如序言中所说,在大部分作业中,从 source 直接产生的数据由于没有经过 join 等算子的筛选和加工,shuffle 的数据量是最大的。以 10T 数据下的 TPC-DS q96 为例,如果不进行进一步优化,包含 store_sales 源表的 task 将向网络中传输 1.03T 的数据,而经过一次 join 的筛选后,数据量急速下降至 16.5G。如果我们能将源表的 forward shuffle 省去,作业整体执行效率又能前进一大步。
可惜的是,multiple input operator 也不能覆盖 source shuffle 的场景,这是因为 source 不同于其它任何算子,它没有任何输入。Flink 1.12 为此给 operator chaining 新增了 source chaining 功能,将不被 shuffle 阻隔的 source 合并到 operator chaining 中,省去了 source 与下游算子之间的 forward shuffle。
目前仅有 FLIP-27 source 以及 multiple input operator 可以利用 source chaining 功能,不过这已经足够解决本文中的优化场景。
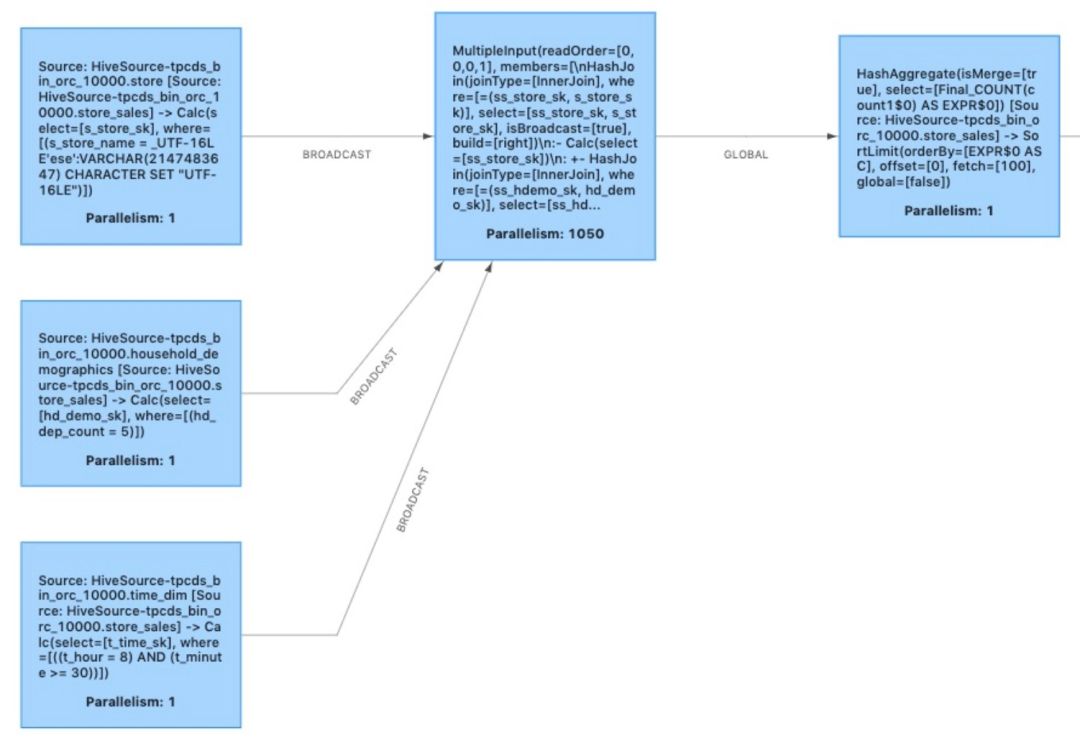
结合 multiple input operator 与 source chaining 之后,图 7 展示了本文优化案例的最终执行方案。
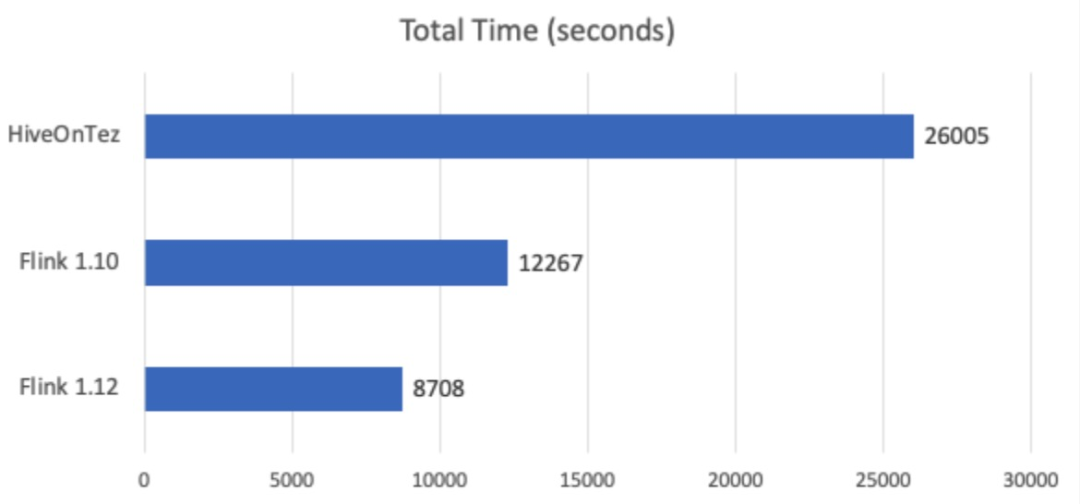
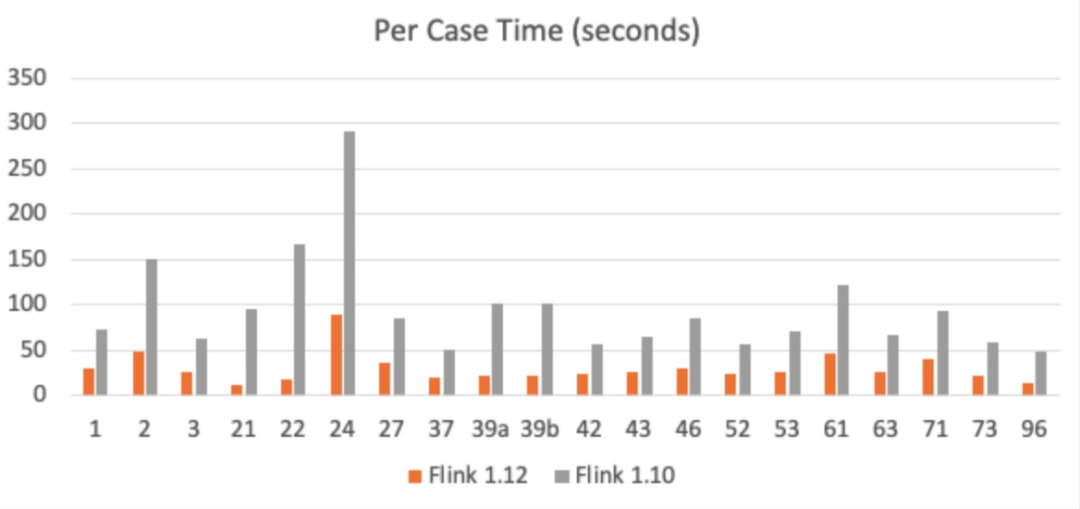
TPC-DS 测试结果
Multiple input operator 与 source chaining 对大部分作业,特别是批作业有显著的优化效果。我们利用 TPC-DS 测试集对 Flink 1.12 的整体性能进行了测试,与 Flink 1.10 公布的 12267s 总用时相比,Flink 1.12 的总用时仅为 8708s,缩短了近 30% 的运行时间!
未来计划
通过 TPC-DS 的测试效果看到,source chaining + multiple input 能够给我们带来很大的性能提升。目前整体框架已完成,常用批算子已支持消除冗余 exchange 的推导逻辑,后续我们将支持更多的批算子和更精细的推导算法。
另外,阿里云实时计算团队围绕 Apache Flink 为核心打造的实时大数据平台,在阿里巴巴内部提供全集团范围的流批一体数据分析服务,同时也通过阿里云向外界提供 Flink 企业级云产品,服务广大中小企业。我们的技术团队围绕开源大数据技术体系构建,包括来自 Apache Flink/Hadoop/HBase/Kafka/Hive/Druid 等多个顶级开源项目的众多 PMC/Committer 成员,加入实时计算团队将可以与众多技术大神共同探索大数据技术世界,感兴趣的同学请速联系:kete.yangkt@alibaba-inc.com。