
如何提高Flink大规模作业的调度器性能
在 Flink 1.12 中调度大规模作业时,需要大量的时间来初始化作业和部署任务。调度器还需要大量的堆内存来存储执行拓扑和主机临时部署描述符。例如,对于一个拓扑结构的作业,该作业包含两个与全对全边相连且并行度为 10k 的作业(这意味着有 10k 个源任务和 10k 个接收器任务,并且每个源任务都连接到所有接收器任务) ,Flink 的 JobManager 需要 30 GiB 的堆内存和超过 4 分钟的时间来部署所有任务。
此外,任务部署可能会长时间阻塞 JobManager 的主线程,JobManager 将无法响应来自 TaskManager 的任何其他请求。这可能会导致触发故障转移的心跳超时。在最坏的情况下,这将导致 Flink 集群无法使用,因为它无法部署作业。
为了提高大规模作业调度器的性能,我们在 Flink 1.13 和 1.14 中实施了多项优化:
引入消费组的概念来优化与拓扑复杂性相关的过程,包括初始化、调度、故障转移和分区释放。
这也减少了存储拓扑所需的内存;
引入缓存优化任务部署,使进程更快,占用内存更少;
利用逻辑拓扑和调度拓扑的特点,加快流水线区域的建设。
为了估计我们优化的效果,我们进行了几次实验来比较 Flink 1.12(优化前)和 Flink 1.14(优化后)的性能。我们实验中的作业包含两个与全对全边相连的顶点。这些顶点的并行度都是 10K。为了通过 blob 服务器分发临时部署描述符,我们将配置blob.offload.minsize设置为 100 KiB(默认值为 1 MiB)。这种配置意味着大于设置值的 blob 将通过 blob 服务器进行分发,我们测试作业中部署描述符的大小约为 270 KiB。我们的实验结果如下图所示:
| 程序 | 1.12 | 1.14 | 减少(%) |
|---|---|---|---|
| 作业初始化 | 11,431 毫秒 | 627ms | 94.51% |
| 任务部署 | 63,118 毫秒 | 17,183 毫秒 | 72.78% |
| 故障转移时要重新启动的计算任务 | 37,195 毫秒 | 170ms | 99.55% |
除了更快的速度外,内存使用量也显着减少。JobManager在Flink 1.12下部署测试作业需要30GiB堆内存,Flink 1.12下JobManager需要的最小堆内存只有2GiB。
长期垃圾收集的发生也较少。在使用 Flink 1.12 运行测试作业时,在作业初始化和任务部署期间都会发生持续时间超过 10 秒的垃圾回收。在 Flink 1.14 中,由于没有长期垃圾回收,心跳超时的风险也降低了,从而创造了更好的集群稳定性。
在我们的实验中,使用 Flink 1.12 的大规模作业过渡到运行需要 4 分钟以上(不包括分配资源所花费的时间)。在 Flink 1.14 中,花费的时间不超过 30 秒(不包括分配资源所花费的时间)。时间成本降低了87%。因此,对于正在运行大规模生产作业并希望获得更好调度性能的用户,请考虑将 Flink 升级到 1.14。
二、优化细节
上一部分简要介绍了我们为提高调度器性能所做的优化。与 Flink 1.12 相比,Flink 1.14 中调度大规模作业的时间成本和内存使用量显着降低。在第二部分,我们将详细阐述这些优化的细节。
分发模式描述了消费者任务如何连接到生产者任务。目前,Flink 中有两种分布模式:pointwise 和 all-to-all。当分布模式在两个顶点之间是逐点分布时,遍历所有边的计算复杂度为 O(n)。当分布模式为 all-to-all 时,遍历所有边的复杂度为 O(n 2 ),这意味着随着规模的增加,复杂度会迅速增加。
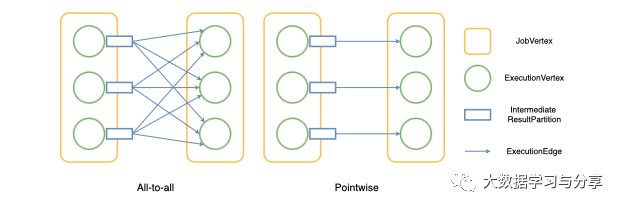
图 1 - Flink 中的两种分布模式
在 Flink 1.12 中,ExecutionEdge类用于存储任务之间的连接信息。这意味着对于 all-to-all 分布模式,会有 O(n 2 ) ExecutionEdges,这将占用大量内存用于大规模作业。对于两个连接一个 all-to-all 边缘和 10K 并行度的JobVertices,存储 100M ExecutionEdges 将需要超过 4 GiB 的内存。由于生产作业中的顶点之间可能存在多个全对全连接,因此所需的内存量将迅速增加。
如图 1 所示,对于以 all-to-all 分布模式连接的两个 JobVertices ,上游ExecutionVertices产生的所有IntermediateResultPartitions都是同构的,这意味着它们所连接的下游 ExecutionVertices 完全相同。属于同一个 JobVertex 的下游 ExecutionVertices 也是同构的,因为它们连接的上游 IntermediateResultPartitions 也是相同的。由于每个JobEdge都只有一种分布类型,我们可以根据 JobEdge 的分布类型将顶点和结果分区分组。
对于 all-to-all 分布模式,由于属于同一个 JobVertex 的所有下游 ExecutionVertices 都是同构的并且属于单个组,因此它们消耗的所有结果分区都连接到该组。该组称为ConsumerVertexGroup。反之,所有上游结果分区被分组到一个组中,所有的消费者顶点都连接到这个组。该组称为ConsumedPartitionGroup。
我们优化的基本思路是将所有消费相同结果分区的顶点放入一个ConsumedPartitionGroup,将所有具有相同消费者顶点的结果分区放入一个ConsumedPartitionGroup。
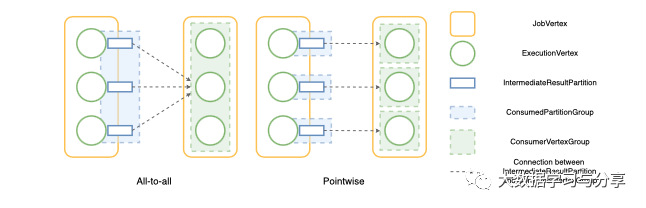
图 2 - 分区和顶点如何按分布模式分组
在调度任务时,Flink 需要遍历结果分区和消费者顶点之间的所有连接。过去,由于总共有 O(n 2 ) 条边,因此迭代的整体复杂度为 O(n 2 )。现在 ExecutionEdge 被替换为 ConsumerVertexGroup 和 ConsumedPartitionGroup。由于所有同构结果分区都连接到同一个下游 ConsumerVertexGroup,当调度器遍历所有连接时,它只需要遍历组一次。计算复杂度从 O(n 2 )降低到 O(n)。
对于逐点分布模式,一个 ConsumedPartitionGroup 点对点连接到一个 ConsumerVertexGroup。组的数量与 ExecutionEdge 的数量相同。因此,迭代组的计算复杂度仍然是 O(n)。
对于示例工作,我们上面提到的,与所述基团取代ExecutionEdges可有效降低存储器使用ExecutionGraph从4个以上的吉布至约12 MIB。基于组的概念,我们进一步优化了作业初始化、调度任务、故障转移、分区释放等几个流程。这些过程都涉及遍历所有分区的所有消费者顶点。优化后,它们的整体计算复杂度从 O(n 2 )降低到 O(n)。
问题
在 Flink 1.12 中,如果大规模作业包含 all-to-all 边,部署任务需要很长时间。此外,在任务部署期间或之后可能会发生心跳超时,从而使集群不稳定。
目前,任务部署包括以下步骤:
JobManager为每个任务创建TaskDeploymentDescriptors,这发生在 JobManager 的主线程中;
JobManager 异步序列化 TaskDeploymentDescriptors;
JobManager 通过 RPC 消息将序列化的 TaskDeploymentDescriptor 发送到 TaskManager;
TaskManagers 基于 TaskDeploymentDescriptors 创建新任务并执行它们。
TaskDeploymentDescriptor (TDD) 包含 TaskManager 创建任务所需的所有信息。在任务部署开始时,JobManager 会为所有任务创建 TDD。由于这发生在主线程中,JobManager 无法响应任何其他请求。对于大型作业,主线程可能会长时间阻塞,可能会发生心跳超时,并会触发故障转移。
JobManager 在任务部署期间可能成为瓶颈,因为所有描述符都从它传输到所有 TaskManager。对于大规模作业,这些临时描述符将需要大量堆内存并导致频繁的长期垃圾收集暂停。
因此,我们需要加快 TDD 的创建速度。此外,如果描述符的大小可以减小,那么它们将被更快地传输,从而导致更快的任务部署。
解决方案
缓存 ShuffleDescriptors
ShuffleDescriptor用于描述任务消耗的结果分区信息,可以是 TaskDeploymentDescriptor 的最大部分。对于一条all-to-all边,当上游和下游顶点的并行度均为n时,每个下游顶点的ShuffleDescriptor数为n,因为它们连接到n个上游顶点。因此,顶点的 ShuffleDescriptor 总数为 n2。
但是,下游顶点的 ShuffleDescriptor 都是相同的,因为它们都使用相同的上游结果分区。因此,Flink 不需要为每个下游顶点单独创建 ShuffleDescriptor。相反,它可以创建一次并缓存它们以供重用。这将降低为从 O(n 2 ) 到 O(n) 的任务创建 TaskDeploymentDescriptor 的整体复杂性。
为了减小 RPC 消息的大小并减少复制数据在网络上的传输,可以压缩缓存的 ShuffleDescriptor。对于我们上面提到的示例作业,如果顶点的并行度都是 10k,那么每个下游顶点都有 10k 个 ShuffleDescriptor。压缩后,序列化值的大小将减少 72%。
通过 blob 服务器分发 ShuffleDescriptors
甲BLOB(二进制大对象)是用于存储大文件的二进制数据的集合。Flink 托管了一个 blob 服务器来在 JobManager 和 TaskManager 之间传输大型数据。当 JobManager 决定将一个大文件传输到 TaskManagers 时,它会首先将文件存储在 blob 服务器中(还将文件上传到分布式文件系统)并获取一个表示 blob 的令牌,称为 blob 密钥。然后它将 blob 密钥而不是 blob 文件传输到 TaskManagers。当 TaskManager 获得 blob 键时,它们将从分布式文件系统 (DFS) 中检索文件。Blob 存储在 TaskManager 上的 Blob 缓存中,因此它们只需要检索一次文件。
在任务部署期间,JobManager 负责通过 RPC 消息将 ShuffleDescriptor 分发给 TaskManager。消息发送后将被垃圾收集。但是,如果 JobManager 不能像创建消息一样快地发送消息,这些消息将占用大量堆内存空间,成为垃圾收集器处理的沉重负担。将会有更多的长期垃圾收集停止世界并减慢任务部署。
为了解决这个问题,可以使用blob服务器分发大的ShuffleDescriptor。JobManager 首先将 ShuffleDescriptors 发送到 blob 服务器,后者将 ShuffleDescriptors 存储在 DFS 中。TaskManager 在开始处理 TaskDeploymentDescriptor 后会从 DFS 请求 ShuffleDescriptor。通过此更改,JobManager 无需将 ShuffleDescriptor 的所有副本保留在堆内存中,直到它们被发送。此外,大规模作业的垃圾收集频率显着降低。此外,由于 DFS 提供了多个分布式节点供 TaskManager 下载 ShuffleDescriptor ,因此任务部署将更快,因为在任务部署过程中不再存在瓶颈。
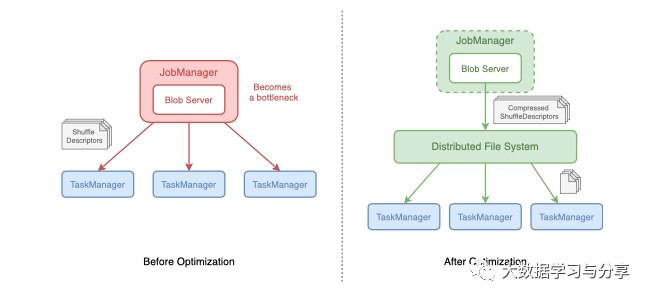
图 3 - ShuffleDescriptors 是如何分布的
为避免本地磁盘空间不足,当相关分区不再有效时,缓存将被清除,并为 TaskManagers 上的 blob 缓存中的 ShuffleDescriptors 添加了大小限制。如果整体大小超过限制,则最近最少使用的缓存值将被删除。这确保了 JobManager 和 TaskManagers 上的本地磁盘不会被 ShuffleDescriptor 填满,尤其是在会话模式下。
在 Flink 中,有两种类型的数据交换:流水线式和阻塞式。使用阻塞数据交换时,结果分区首先完全生成,然后由下游顶点使用。产生的结果被持久化并且可以被多次使用。当使用流水线数据交换时,结果分区是同时产生和消费的。生成的结果不会持久化,只能使用一次。
由于流水线数据流是同时生产和消费的,Flink 需要确保通过流水线数据交换连接的顶点同时执行。这些顶点形成了一个流水线区域。流水线区域默认是调度和故障转移的基本单位。在调度时,一个流水线区域中的所有顶点会被一起调度,图中所有的流水线区域都会按照拓扑的方式一个一个地调度。
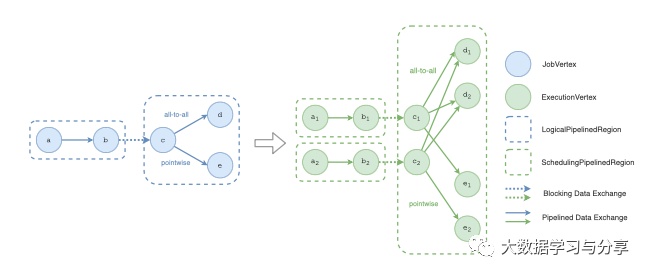
图 4 - LogicalPipelinedRegion 和 SchedulingPipelinedRegion
目前,调度器中有两种流水线区域:LogicalPipelinedRegion和SchedulingPipelinedRegion。LogicalPipelinedRegion 表示逻辑级别的流水线区域。它由 JobVertices 组成并形成JobGraph。SchedulingPipelinedRegion 表示执行级别的流水线区域。它由 ExecutionVertices 组成并形成 ExecutionGraph。就像 ExecutionVertices 派生自 JobVertex 一样,SchedulingPipelinedRegions 派生自 LogicalPipelinedRegion,如图 4 所示。
在构建流水线区域的过程中,会出现一个问题:流水线区域之间可能存在循环依赖。当且仅当其所有依赖项都已完成时,才能调度流水线区域。但是,如果有两个相互之间存在循环依赖的流水线区域,就会出现调度死锁。他们都在等待对方先被调度,而且都无法调度。因此,采用Tarjan 的强连通分量算法来发现区域之间的循环依赖关系,并将它们合并为一个流水线区域。它将遍历拓扑中的所有边。对于 all-to-all 分布模式,边数为 O(n 2)。因此,该算法的计算复杂度为 O(n 2 ),并且显着减慢了调度器的初始化。
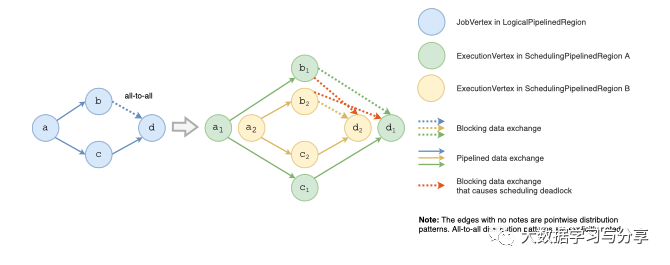
图 5 - 具有调度死锁的拓扑
为了加快流水线区域的构建,可以利用逻辑拓扑和调度拓扑之间的相关性。由于一个 SchedulingPipelinedRegion 只派生自一个 LogicalPipelinedRegion,因此 Flink 会遍历所有 LogicalPipelinedRegions 并将它们一一转换为 SchedulingPipelinedRegions。转换根据连接 LogicalPipelinedRegion 中的顶点的边的分布模式而有所不同。
如果 region 内部有 all-to-all 的分布模式,则可以直接将整个 region 转换为一个 SchedulingPipelinedRegion。这是因为对于具有流水线数据交换的 all-to-all 边缘,连接到该边缘的所有区域必须同时执行,这意味着它们被合并到一个区域中。对于具有阻塞数据交换的 all-to-all 边缘,它将引入循环依赖关系,如图 5 所示。它连接的所有区域都必须合并到一个区域中,以避免调度死锁,如图 6 所示。由于不需要使用 Tarjan 算法,因此这种情况下的计算复杂度为 O(n)。
如果一个区域内只有逐点分布模式,仍然使用 Tarjan 的强连通分量算法来确保没有循环依赖。由于只有逐点分布模式,因此拓扑中的边数为 O(n),算法的计算复杂度为 O(n)。
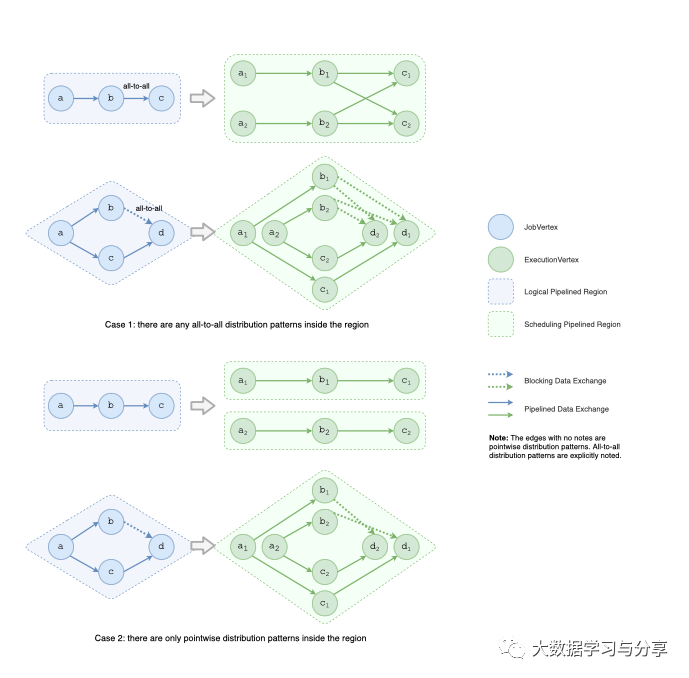
优化后,构建流水线区域的整体计算复杂度从 O(n 2 )降低到 O(n)。在我们的实验中,对于包含两个与阻塞的 all-to-all 边相连的顶点的作业,当它们的并行度均为 10K 时,构建流水线区域的时间减少了 99%,从 8,257 ms 减少到 120 ms。
总而言之,我们在 Flink 1.13 和 1.14 中做了一些优化来提高调度器在大规模作业中的性能。优化涉及的过程包括作业初始化、调度、任务部署和故障转移。如果您对它们有任何疑问,请随时在开发邮件列表中开始讨论。