
Tansformer | 详细解读:如何在CNN模型中插入Transformer后速度不变精度剧增?


1简介
本文工作解决了Multi-Head Self-Attention(MHSA)中由于计算/空间复杂度高而导致的vision transformer效率低的缺陷。为此,作者提出了分层的MHSA(H-MHSA),其表示以分层的方式计算。
具体来说,H-MHSA首先通过把图像patch作为tokens来学习小网格内的特征关系。然后将小网格合并到大网格中,通过将上一步中的每个小网格作为token来学习大网格中的特征关系。这个过程多次迭代以逐渐减少token的数量。
H-MHSA模块很容易插入到任何CNN架构中,并且可以通过反向传播进行训练。作者称这种新的Backbone为TransCNN,它本质上继承了transformer和CNN的优点。实验证明,TransCNN在图像识别中具有最先进的准确性。
2Vision Transformer回顾
大家应该都很清楚Transformer严重依赖MHSA来建模长时间依赖关系。假设为输入,其中N和C分别为Token的数量和每个Token的特征维数。这里定义了Query 、key 和 value ,其中, , 为线性变换的权重矩阵。在假设输入和输出具有相同维度的情况下,传统的MHSA可以表示为:
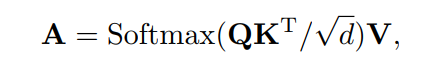
其中表示近似归一化,对矩阵行应用Softmax函数。注意,为了简单起见在这里省略了多个Head的概念。在上式中的矩阵乘积首先计算每对Token之间的相似度。然后,在所有Token的组合之上派生出每个新Token。MHSA计算后,进一步添加残差连接以方便优化,如:
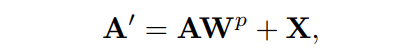
其中,为特征映射的权重矩阵。最后,采用MLP层增强表示,表示形式为:
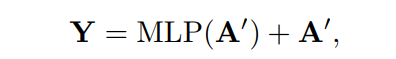
其中Y表示transformer block的输出。
有前面的等式可以得到MHSA的计算复杂度:

很容易推断出空间复杂度(内存消耗)。对于高分辨率的输入,可能变得非常大,这限制了Transformer在视觉任务中的适用性。基于此,本文的目标是在不降低性能的情况下降低这种复杂性,并保持全局关系建模的能力。
Transformer Block Pytorch实现如下:
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Attention(nn.Module):
# Muliti-Head Self-Attention Block
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
# 输出 Q K V
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
# q matmul k.T
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
# attn' matmul v ==> output
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Block(nn.Module):
# Transformer Encoder Block
# Embedded Patches ==> Layer Norm ==> Muliti-Head Attention + ==> Layer Norm ==> MLP + ==>
# |_________________________________________| |__________________|
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0., drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
# 进行稀疏化操作,可以得到更好的结果
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
3Hierarchical Multi-Head Self-Attention
在这里,作者介绍了如何使用H-MHSA降低MHSA的计算/空间复杂度。这里不是在整个输入中计算注意力,而是以分层的方式计算,这样每个步骤只处理有限数量的Token。

图b为H-MHSA的范式。假设输入特征映射的高度为,宽度为,有。然后将特征图划分为大小为的小网格,并将特征图Reshape为:
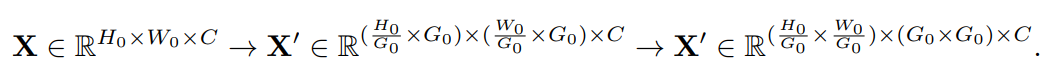
当, 和时,式(1)生成局部注意。为了简化网络优化,这里将 Reshape为X的shape:

并添加一个残差连接:

由于是在每个小网格内计算的,因此计算/空间复杂度显著降低。
对于第i步(i>0),将第(i-1)步处的每个更小的网格视为一个Token,这可以简单地通过对注意力特征进行降采样来实现:
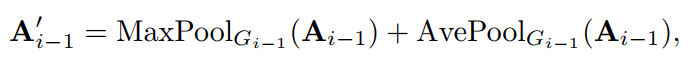
其中和分别表示使用最大池化和平均池化(内核大小和步长为)将样本降为次。因此,有, 其中,。然后,将划分为网格,并将其Reshape为:
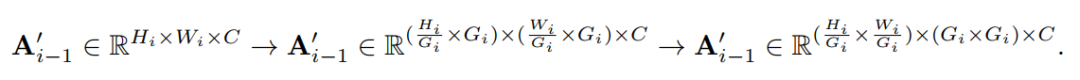
当, , 时,方程(1)获取注意特征。最终被Reshape为为输入的shape,比如:
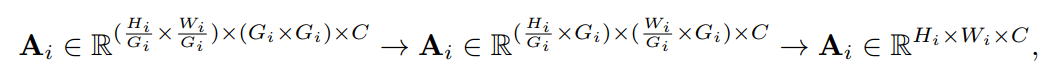
并添加一个残差连接:
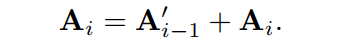
这个过程不断迭代,直到足够小而不能在进行split。H-MHSA的最终输出为:
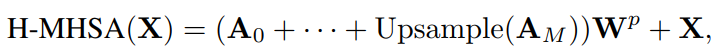
如果Upsample(·)表示将注意力特征上采样到原始大小,则与Equ(2)含义相同, M为最大步数。通过这种方式,H-MHSA可以等价于传统的MHSA来模拟全局关系。
很容易证明,在所有都相同的假设下,H-MHSA的计算复杂度近似:

与MHSA的计算复杂度相比较,本文所提方法显著降低了计算复杂度。
4将Transformer插入到CNN中
本文和之前将CNN与Transformer的方法一样遵循普遍做法,在网络Backbone中保留3D特征图,并使用全局平均池化层和全连接层来预测图像类别。这与现有的依赖另一个1D类标记进行预测的Transformer不同。
作者还观察到以往的Transformer网络通常采用GELU函数进行非线性激活。然而,在网络训练中,GELU函数非常耗费内存。作者通过经验发现,SiLU的功能与GELUs不相上下,而且更节省内存。因此,TransCNN选择使用SiLU函数进行非线性激活。
作者做了一组实验。在ImageNet验证集上,当训练为100个epoch时,提出的具有SiLU的跨网络网络(TransCNN)在ImageNet验证集上获得80.1%的top-1精度。GELU的TransCNN得到79.7%的top-1精度,略低于SiLU。当每个GPU的batchsize=128时,SiLU在训练阶段占用20.2GB的GPU内存,而GELU占用23.8GB的GPU内存。

TransCNN的总体架构如图所示。
在TransCNN的开始阶段使用了2个连续的个卷积,每个卷积的步长为2,将输入图像降采样到1/4的尺度。

然后,将H-MHSA和卷积块交替叠加,将其分为4个阶段,分别以1/4,1/8,1/16,1/32的金字塔特征尺度进行划分。这里采用的卷积模块是广泛使用的Inverted Residual Bottleneck(IRB,图c),卷积是深度可分离卷积。

在每个阶段的末尾,作者设计了一个简单的二分支降采样块(TDB,图d)。它由2个分支组成:一个分支是一个典型的卷积,步长为2;另一个分支是池化层和卷积。在特征降采样中,这2个分支通过元素求和的方式融合,以保留更多的上下文信息。实验表明,TDB的性能优于直接降采样。
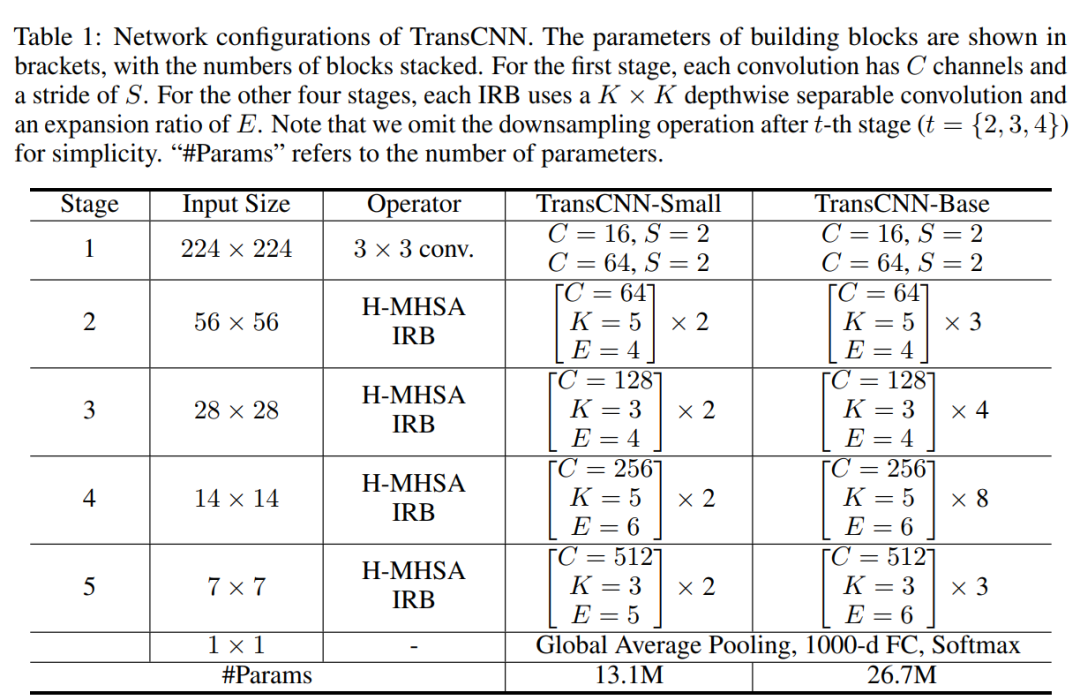
TransCNN的详细配置如表所示。提供了2个版本的TransCNN: TransCNN-Small和TransCNN-Base。TransCNN-Base的参数个数与ResNet50相似。需要注意的是,这里只采用了最简单的参数设置,没有进行仔细的调优,以证明所提概念H-MHSA和trannn的有效性和通用性。例如,作者使用典型的通道数,即64、128、256和512。MHSA中每个Head的尺寸被设置为64。作者提到对这些参数设置进行细致的工程调整可以进一步提高性能。
5实验
5.1 ImageNet图像分类
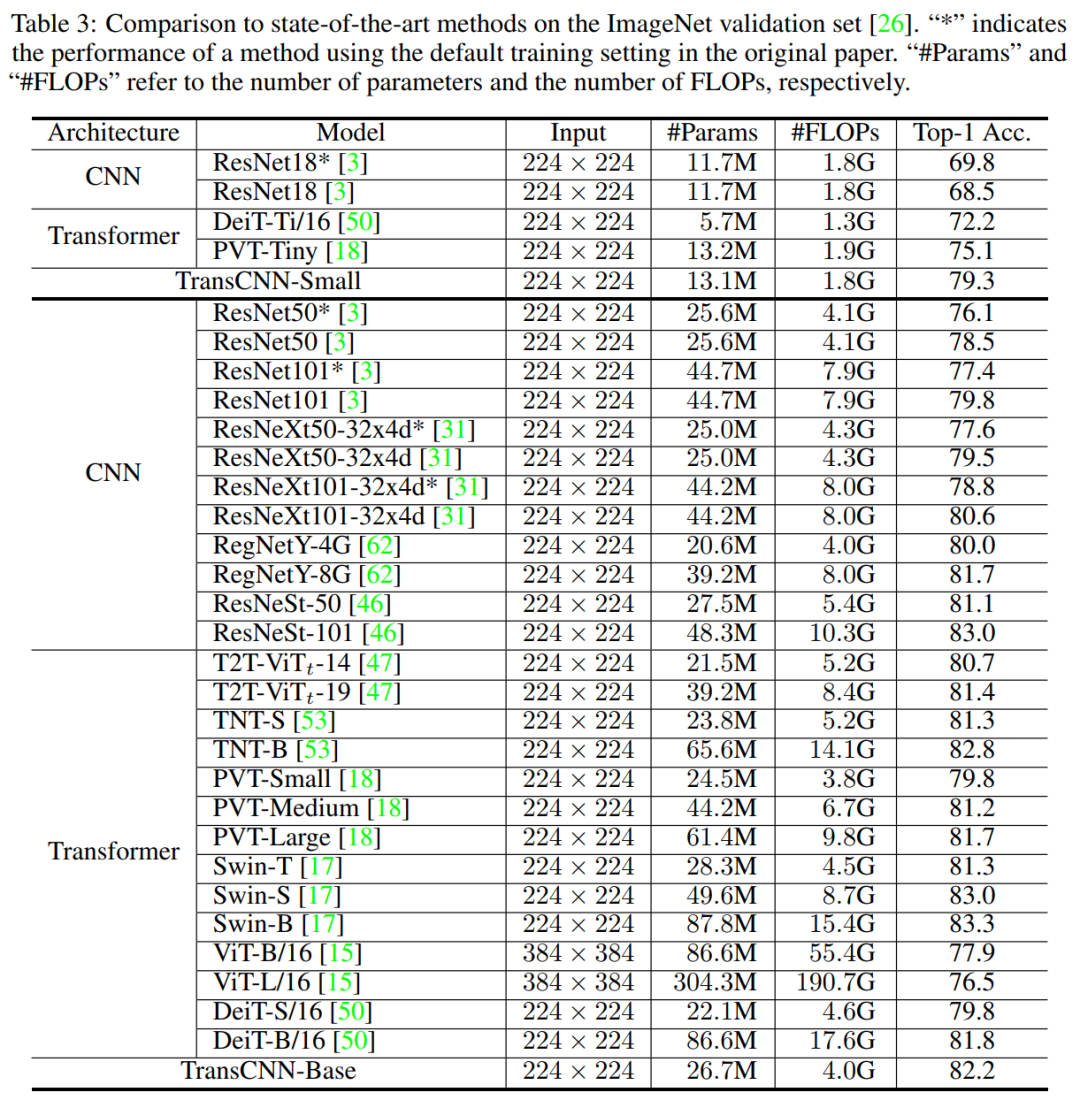
通过上表可以看出,将H-MHSA插入到相应的卷积模型中,可以以很少的参数量和FLOPs换取很大的精度提升。
5.2 MS-COCO 2017目标检测
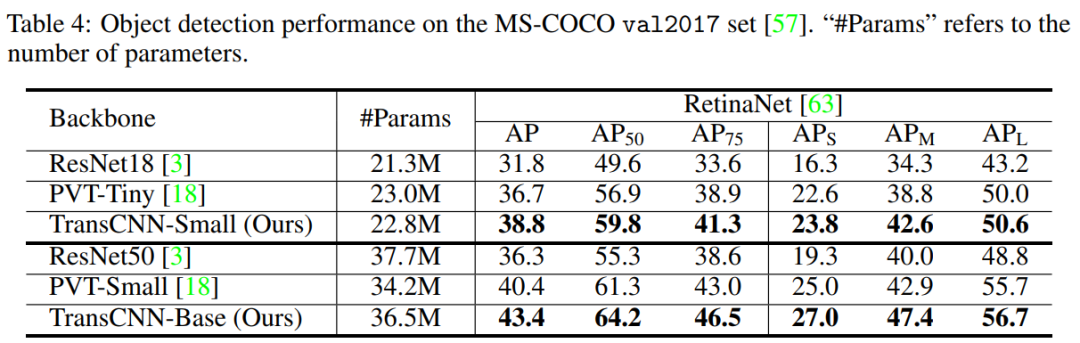
通过上表可以看出,在比ResNet50更少的参数量的同时,RetinaNet的AP得到了很大的提升。
5.3 MS-COCO 2017语义分割
通过上表可以看出,在比ResNet50更少的参数量的同时,Mask R-CNN的AP得到了很大的提升。可见本文所提方法的实用性还是很强的。
6参考
[1].Transformer in Convolutional Neural Networks
7推荐阅读

最强Transformer | 太顶流!Scaling ViT将ImageNet Top-1 Acc刷到90.45%啦!!!

Transformer | 没有Attention的Transformer依然是顶流!!!

YOLO |多域自适应MSDA-YOLO解读,恶劣天气也看得见(附论文)
本文论文原文获取方式,扫描下方二维码
回复【ViT-in-CNN】即可获取论文
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
