
凭什么相信你,我的CNN模型?关于CNN模型可解释性的思考
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


作者:bindog 文仅交流,侵删
01
00 背景
01 反卷积和导向反向传播
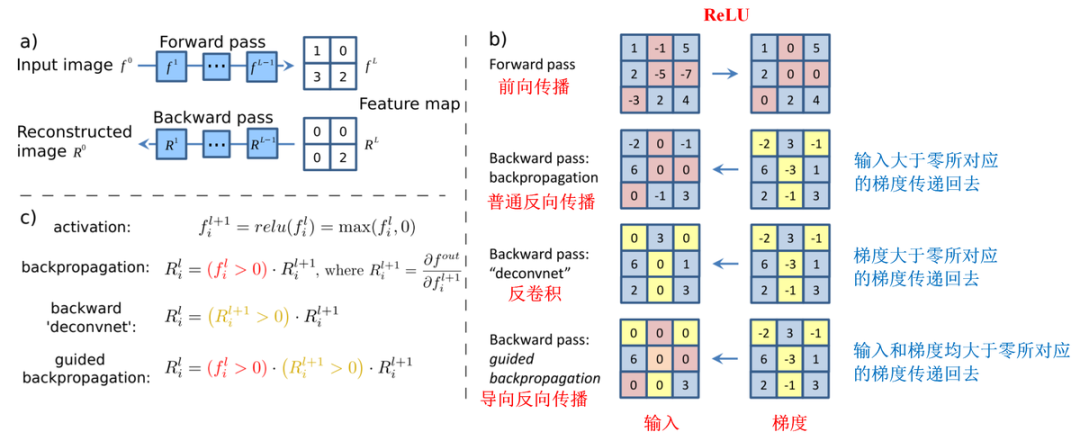
02 CAM

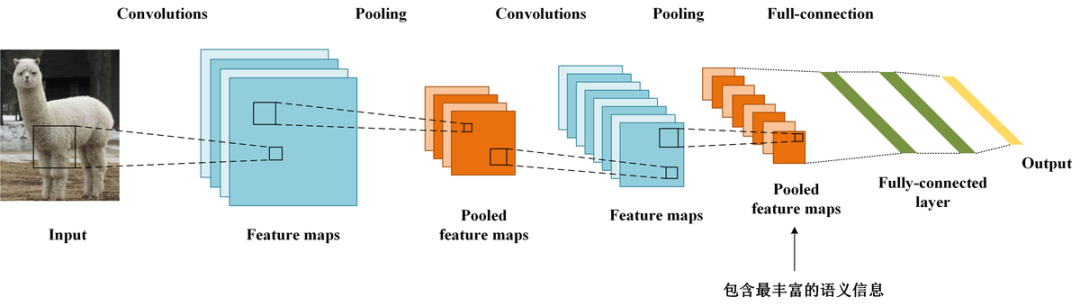
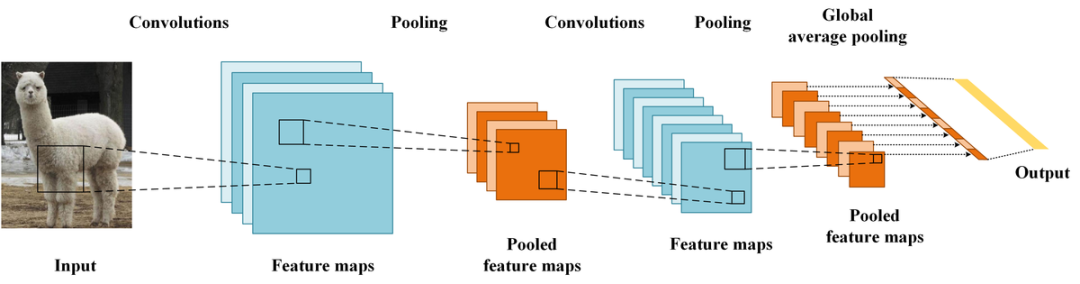
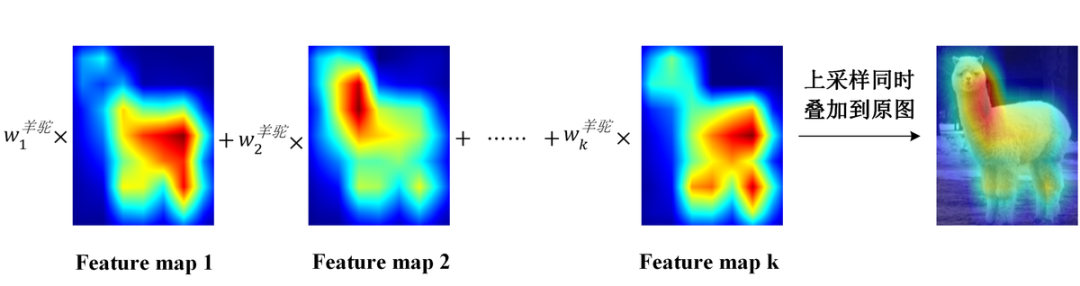
03 Grad-CAM方法
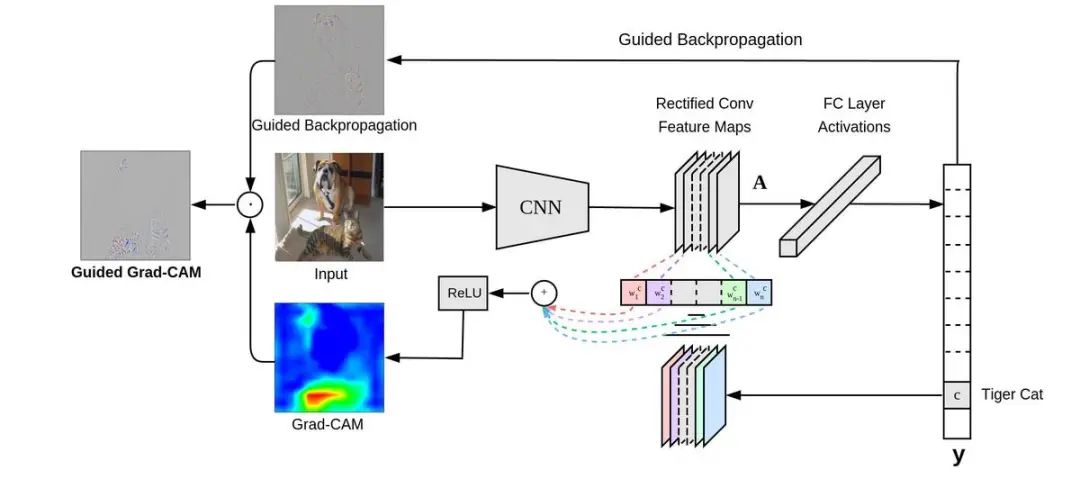

04 扩展
05 小结
02
00 背景
01 LIME
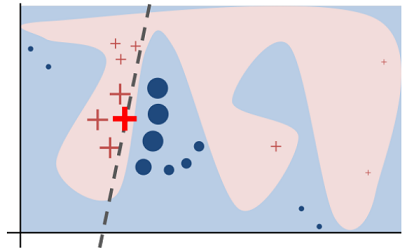

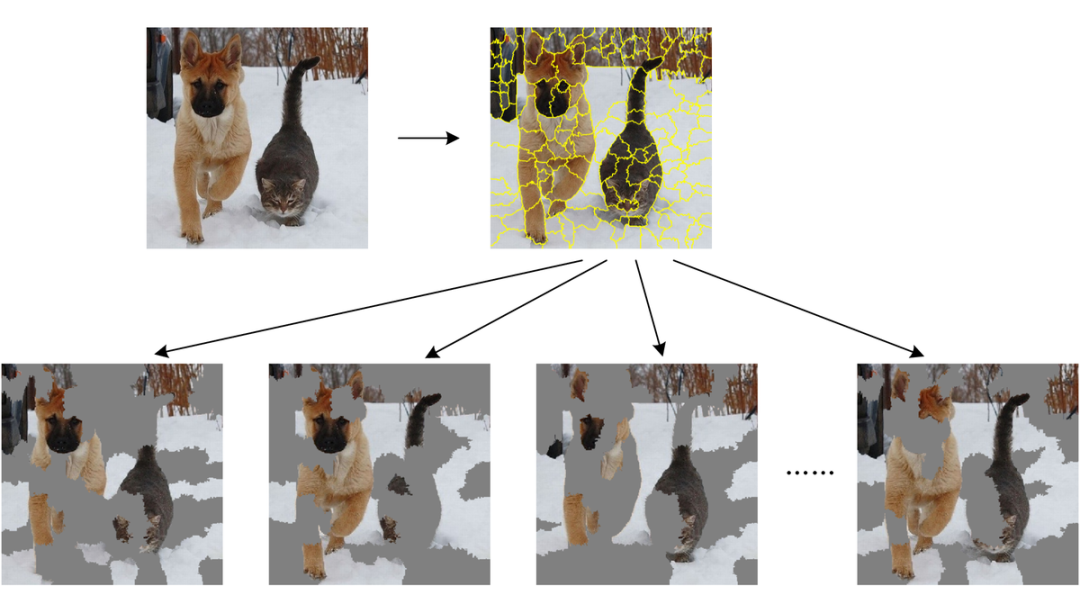
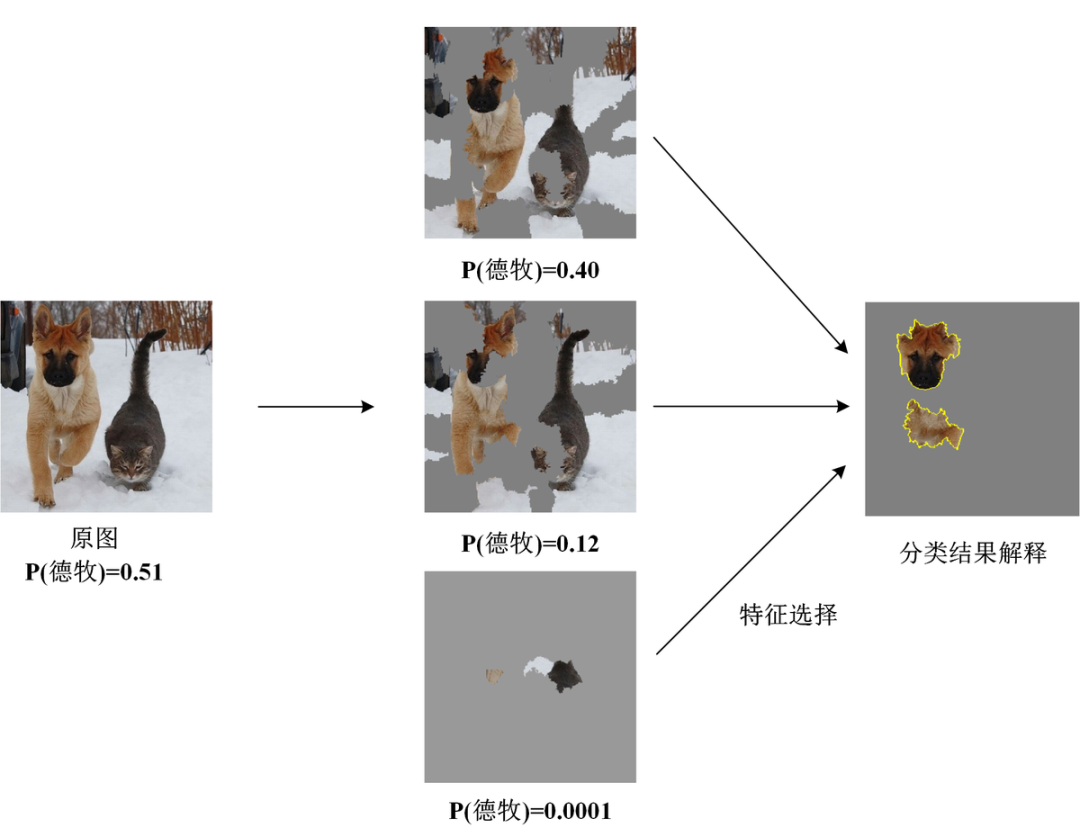

02 小结
[1] “Why Should I Trust You?”: Explaining the Predictions of Any Classifier
https://arxiv.org/abs/1602.04938
[2] Introduction to Local Interpretable Model-Agnostic Explanations (LIME)
本文目的在于学术交流,并不代表本公众号赞同其观点或对其内容真实性负责,版权归原作者所有,如有侵权请告知删除。
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!
评论