
yolov5模型转换NCNN模型部署
写作原因:最近看了下nihui大佬的ncnn,练习着将yolov5训练的模型转换成ncnn模型并部署,同时借鉴了网上优秀的博文,记录一下,如有不对的地方,请多多指教。
说明:pytorch模型转换成onnx模型,及onnx模型简化和转ncnn模型在引用的文章中都有详细的说明,可移步至引用文章中查看。
先来看下ncnn模型,两个,一个是param一个是bin,需要修改的是param。
图1
其实yolov5 v1-v5版本在训练完后,使用onnx2ncnn.exe将简化后的onnx模型转换成ncnn模型时主要出现这个问题。V6版本在输出上和前5个版本有一点不同,这里针对1-5版本。
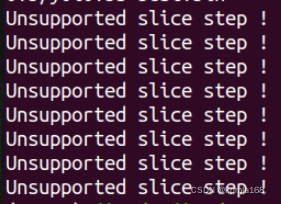
图2
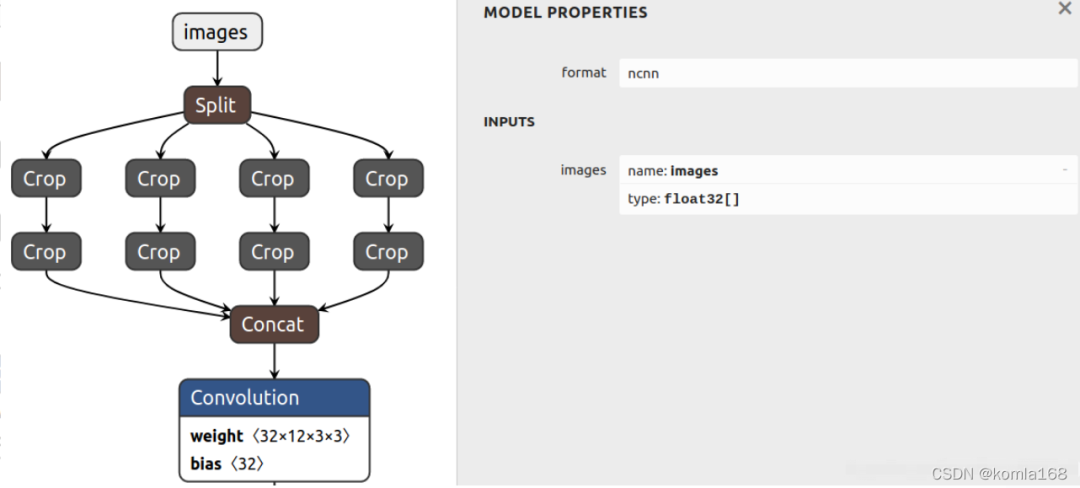
图3
根据nihui大佬的方案看,主要做两步工作,一是删除这里报错的网络层,然后自定义一个新层作为替代,第二步是修改输出参数,做完这两步就可以使用了。
下面说下修改的是什么,这样就可以知道自己的模型应该修改哪里了。
一、param部分参数说明
7767517 # 文件头 魔数
75 83 # 层数量 输入输出blob数量
# 下面有75行
Input data 0 1 data 0=227 1=227 2=3
Convolution conv1 1 1 data conv1 0=64 1=3 2=1 3=2 4=0 5=1 6=1728
ReLU relu_conv1 1 1 conv1 conv1_relu_conv1 0=0.000000
Pooling pool1 1 1 conv1_relu_conv1 pool1 0=0 1=3 2=2 3=0 4=0
Convolution fire2/squeeze1x1 1 1 pool1 fire2/squeeze1x1 0=16 1=1 2=1 3=1 4=0 5=1 6=1024
...
层类型 层名字 输入blob数量 输出blob数量 输入blob名字 输出blob名字 参数字典
参数字典,每一层的意义不一样:
数据输入层 Input data 0 1 data 0=227 1=227 2=3 图像宽度×图像高度×通道数量
卷积层 Convolution ... 0=64 1=3 2=1 3=2 4=0 5=1 6=1728
0输出通道数 num_output() ; 1卷积核尺寸 kernel_size(); 2空洞卷积参数 dilation(); 3卷积步长 stride();
4卷积填充pad_size(); 5卷积偏置有无bias_term(); 6卷积核参数数量 weight_blob.data_size();
C_OUT * C_in * W_h * W_w = 64*3*3*3 = 1728
池化层 Pooling 0=0 1=3 2=2 3=0 4=0
0池化方式:最大值、均值、随机 1池化核大小 kernel_size(); 2池化核步长 stride();
3池化核填充 pad(); 4是否为全局池化 global_pooling();
激活层 ReLU 0=0.000000 下限阈值 negative_slope();
ReLU6 0=0.000000 1=6.000000 上下限
综合示例:
0=1 1=2.5 -23303=2,2.0,3.0
数组关键字 : -23300
-(-23303) - 23300 = 3 表示该参数在参数数组中的index
后面的第一个参数表示数组元素数量,2表示包含两个元素
代码 1
二、对 ncnn.param 进行修正
算子替换 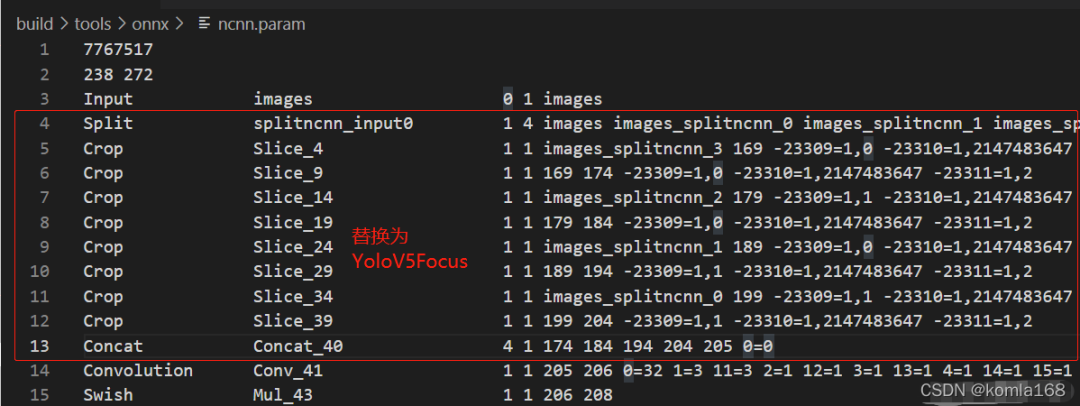
图4 替换前

图5 替换后
说明:为什么要这么做,nihui大佬对此的解释如下:
nihuinihuinihuinihuinihuinihuinihuinihuinihuinihuinihuinihuinihuinihuinihuinihuinihuinihuinihuinihuini
转换为 ncnn 模型,会输出很多 Unsupported slice step,这是focus模块转换的报错。
Unsupported slice step !
Unsupported slice step !
Unsupported slice step !
Unsupported slice step !
Unsupported slice step !
Unsupported slice step !
Unsupported slice step !
Unsupported slice step !
代码 2
好多人遇到这种情况,便不知所措,这些警告表明focus模块这里要手工修复下
打开 yolov5/models/common.py 看看focus在做些什么
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
代码 3
这其实是一次 col-major space2depth 操作,pytorch 似乎并没有对应上层api实现(反向的 depth2space 可以用 nn.PixelShuffle),yolov5 用 stride slice 再 concat 方式实现,实乃不得已而为之的骚操作。
替换后修改的参数含义
由代码1可知,param第二行的第一个数据是层数量,按niuhui大佬的意思需要替换的行数为4-13行,总共10行,因此第二行的第一个参数就是238-10=228,然后,新增加一层替换,因此最后第二行第一个参数就变成了228+1=229。
然后就是就是新增加一行的输入、输出参数修改了,由代码1中参数说明可知,input层的输出是iamges,原来第14层的输入为205,因此增加层的输入输出就确定了,分别为images、205。
动态尺寸推理 
图6
说明:为什么要修改这里,nihui大佬的解释是
u版yolov5 是支持动态尺寸推理,但是ncnn天然支持动态尺寸输入,无需reshape或重新初始化,给多少就算多少。u版yolov5 将最后 Reshape 层把输出grid数写死了,导致检测小图时会出现检测框密密麻麻布满整个画面,或者根本检测不到东西。
解决方案就是将reshape层的输出grid数量改为 -1 便可以自适应。