
实操教程|yolov5模型部署落地:Nvidia Jetson TX2使用TensorRT部署yolov5s模型

极市导读
本篇教程将主要讨论如何利用TensorRT来在TX2端实际部署模型并在前向推理阶段进行加速,也是系列教程中最为重要、最少资料的模型落地部分。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
一、TensorRT是什么?
TensorRT 是由 Nvidia 推出的 GPU 推理引擎(GIE: GPU Inference Engine)。和通用的深度学习框架不同,TensorRT 只提供前向传播,即推理的功能,而没有训练的功能。实际上,训练的场景下,资源通常不会特别紧张,因为是离线的操作(不要求实时反馈),即使出现了一时的资源不足也可以通过增加计算时长来弥补,所以训练框架的资源消耗一般不会有很强的优化。而网络的部署通常对资源更加敏感,算力与内存都是需要考虑的因素。TensorRT 是一个旨在极致优化 GPU 资源使用的深度学习推理计算框架。其工作主要分为两个阶段:建造阶段(build phase)和执行阶段(compile phase)。
在建造阶段,TensorRT 接收外部提供的网络定义(也可包含权值 weights)和超参数,根据当前编译的设备进行网络运行的优化(optimization), 并生成推理引擎 inference engine(可以以 PLAN 形式存在在硬盘上);
在执行阶段,通过运行推理引擎调用 GPU 计算资源——整个流程如下所示:
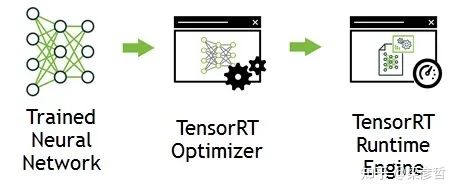
二、为什么要使用TensorRT
1.满足实时性要求
使用TensorRT加速推理是嵌入式AI非常重要的一环。具体来说以我自己1660Ti笔记本跑模型尚且不能达到满足要求的帧率,更别指望TX2有多好的效果。经实际测试,TX2端TensorRT加速后可至40帧左右,满足实时性要求。
2.TX2环境限制(关键!)
以最新的TX2刷机包Jetpack4.5.1为例,其封装好的CUDA版本为10.0,而我使用的yolov5 4.0版本需CUDA11.0,且yolov5所依赖的某些依赖尚无支持arm架构的版本,在TX2上直接跑yolov5是根本不可能的!必须使用TensorRT API对网络进行“复现”。
三、如何使用TensorRT
1.前期准备与说明
使用TensorRT的过程,实际就是在其API下复现yolov5的过程。对于任意一个已训练好的神经网络,我们需要得知其网络结构(backbone, neck等)与训练权重。训练权重已由系列教程的第二篇中得到,网络结构的获取方法主要有以下几种:1.使用TF-TRT,将TensorRT集成在TensorFlow中 2.使用ONNX2TensorRT,即ONNX转换trt的工具 3.手动构造模型结构,然后手动将权重信息挪过去,非常灵活但是时间成本略高,有大佬已经尝试过了:tensorrtx 其中前两种常常会有遇到不支持的结构/层的情况,解决该问题非常费时。而使用TensorRT API手动构造模型结构是最为稳妥、对模型还原度最高、精度损失最少的一种方法。万幸有dalao已将此开源,在此列出项目链接并表示感谢!
wang-xinyu/tensorrtxgithub.com
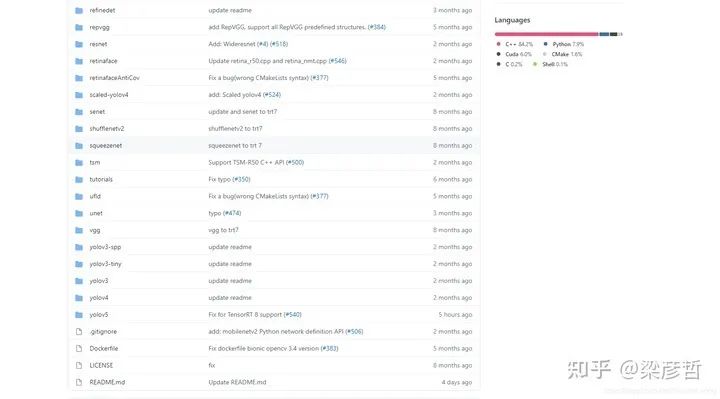
可以看到该项目除支持yolov5外,resnet, yolov3, yolov4等均支持,如果使用其他网络结构的同学也可以加以利用。
2. 使用流程
下载好该项目的项目的源码后,我们仅需要用到其中yolov5的子文件夹,其他为无关项。下载过程中要注意所下载的tensorrtx版本应与所选用的yolov5版本相匹配。
2.1 权重转换
打开gen_wts.py文件,修改对应权重路径
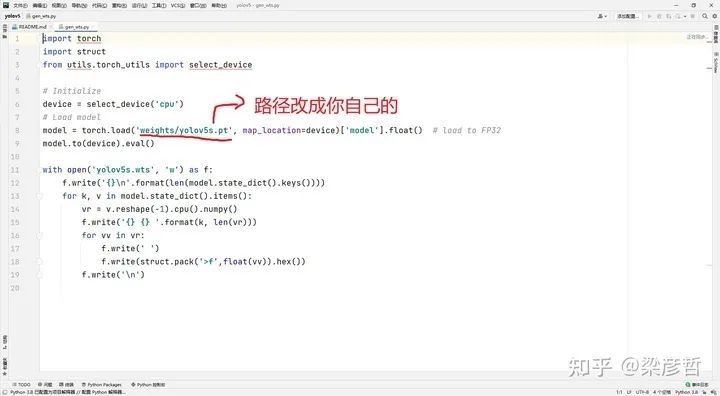
此步将会得到wts格式的yolov5权重,以供下一步生成engine文件
2.2 生成TensorRT Engine
// put yolov5s.wts into tensorrtx/yolov5// go to tensorrtx/yolov5// update CLASS_NUM in yololayer.h if your model is trained on custom dataset//注意在yololayer.h中改类别数!!mkdir buildcd buildcmake ..make //编译完成//由wts生成engine文件sudo ./yolov5 -s [.wts] [.engine] [s/m/l/x or c gd gw] // serialize model to plan file//利用engine文件进行推理,此处输入图片所在文件夹,即可得到预测输出sudo ./yolov5 -d [.engine] [image folder] // deserialize and run inference, the images in [image folder] will be processed.// For example yolov5ssudo ./yolov5 -s yolov5s.wts yolov5s.engine ssudo ./yolov5 -d yolov5s.engine ../samples// For example Custom model with depth_multiple=0.17, width_multiple=0.25 in yolov5.yamlsudo ./yolov5 -s yolov5_custom.wts yolov5.engine c 0.17 0.25sudo ./yolov5 -d yolov5.engine ../samples
四、效果评估 如下是我在TX2端的实测视频
五、后续说明
1.得到engine文件后即可进行推理,但默认输入是图片文件夹,而一般来说实时性项目多用摄像头做输入源,故在yolov5.cpp中魔改一下再重新编译就行。此外IRuntime, ICudaEngine, IExecutionContext等核心类源码中每次有图片输入都会创建一次,严重拖慢速度,改成仅初始化阶段创建,后续再有图片输入时保持可以提高推理速度。
2.以后可能会融合deepsort做一下目标跟踪,敬请期待~
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
