
【NLP】bert4vec:一个基于预训练的句向量生成工具
环境
transformers>=4.6.0,<5.0.0 torch>=1.6.0 numpy huggingface-hub faiss (optional)
安装
方式一
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ bert4vec方式二
git clone https://github.com/zejunwang1/bert4vec
cd bert4vec/
python setup.py sdist
pip install dist/bert4vec-1.0.0.tar.gz功能介绍
目前支持加载的句向量预训练模型包括 SimBERT、RoFormer-Sim 和 paraphrase-multilingual-MiniLM-L12-v2,其中 SimBERT 与 RoFormer-Sim 为苏剑林老师开源的中文句向量表示模型,paraphrase-multilingual-MiniLM-L12-v2 为 sentence-transformers 开放的多语言预训练模型,支持中文句向量生成。
句向量生成
from bert4vec import Bert4Vec
# 支持四种模式:simbert-base/roformer-sim-base/roformer-sim-small/paraphrase-multilingual-minilm
model = Bert4Vec(mode='simbert-base')
sentences = ['喜欢打篮球的男生喜欢什么样的女生', '西安下雪了?是不是很冷啊?', '第一次去见女朋友父母该如何表现?', '小蝌蚪找妈妈怎么样',
'给我推荐一款红色的车', '我喜欢北京']
vecs = model.encode(sentences, convert_to_numpy=True, normalize_to_unit=False)
# encode函数支持的默认输入参数有:batch_size=64, convert_to_numpy=False, normalize_to_unit=False
print(vecs.shape)
print(vecs)
结果如下:
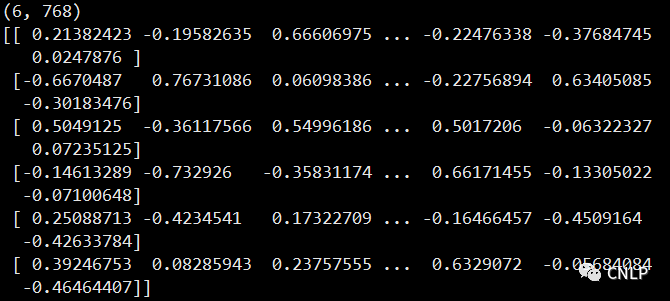
当需要计算英文句子的稠密向量时,需要设置 mode='paraphrase-multilingual-minilm'。
相似度计算
from bert4vec import Bert4Vec
model = Bert4Vec(mode='paraphrase-multilingual-minilm')
sent1 = ['喜欢打篮球的男生喜欢什么样的女生', '西安下雪了?是不是很冷啊?', '第一次去见女朋友父母该如何表现?', '小蝌蚪找妈妈怎么样',
'给我推荐一款红色的车', '我喜欢北京', 'That is a happy person']
sent2 = ['爱打篮球的男生喜欢什么样的女生', '西安的天气怎么样啊?还在下雪吗?', '第一次去见家长该怎么做', '小蝌蚪找妈妈是谁画的',
'给我推荐一款黑色的车', '我不喜欢北京', 'That is a happy dog']
similarity = model.similarity(sent1, sent2, return_matrix=False)
# similarity函数支持的默认输入参数有:batch_size=64, return_matrix=False
print(similarity)
结果如下:
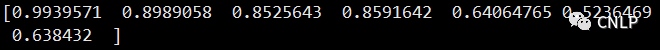
假设 sent1 包含 M 个句子,sent2 包含 N 个句子,当 similarity 函数的 return_matrix 参数设置为 False 时,函数返回 sent1 和 sent2 中同一行两个句子之间的余弦相似度,此时要求 M=N,否则会报错。
当 similarity 函数的 return_matrix 参数设置为 True 时,函数返回一个 M*N 相似度矩阵,矩阵的第 i 行第 j 列元素表示 sent1 的第 i 个句子和 sent2 的第 j 个句子之间的余弦相似度。
similarity = model.similarity(sent1, sent2, return_matrix=True)
print(similarity)
结果如下:
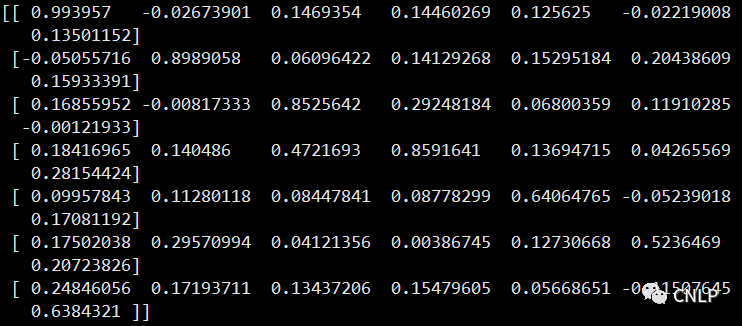
语义检索
bert4vec 支持使用 faiss 构建 cpu/gpu 句向量索引,Bert4Vec 类的 build_index 函数参数列表如下:
def build_index(
self,
sentences_or_file_path: Union[str, List[str]],
ann_search: bool = False,
gpu_index: bool = False,
n_search: int = 64,
batch_size: int = 64
)
sentences_or_file_path:要进行索引构建的句子文件路径或句子列表。 ann_search:是否进行近似最近邻查找。若为 False,则查找时进行暴力搜索计算,返回精确结果。 gpu_index:是否构建 gpu 索引。 n_search:近似最近邻查找时的搜索类别数量,该参数越大,查找结果越准确。 batch_size:句向量计算时的批量大小。
使用 Chinese-STS-B 验证集 (https://github.com/zejunwang1/CSTS) 中去重后的所有句子构建索引,进行近似最近邻查找的示例代码如下:
from bert4vec import Bert4Vec
model = Bert4Vec(mode='roformer-sim-small')
sentences_path = "./sentences.txt" # examples文件夹下
model.build_index(sentences_path, ann_search=True, gpu_index=False, n_search=32)
results = model.search(queries=['一个男人在弹吉他。', '一个女人在做饭'], threshold=0.6, top_k=5)
# threshold为最低相似度阈值,top_k为查找的近邻个数
print(results)
结果如下:

Bert4Vec 类支持使用如下函数保存和加载句向量索引文件:
def write_index(self, index_path: str)
def read_index(self, sentences_path: str, index_path: str, is_faiss_index: bool = True)
sentences_path 为构建句向量索引的句子文件路径,index_path 为句向量索引存储路径。
模型下载
笔者将原始的 SimBERT 和 RoFormer-Sim 模型权重转换为支持使用 Huggingface Transformers 进行加载的模型格式:https://huggingface.co/WangZeJun
from bert4vec import Bert4Vec
model = Bert4Vec(mode='simbert-base', model_name_or_path='WangZeJun/simbert-base-chinese')
model = Bert4Vec(mode='roformer-sim-base', model_name_or_path='WangZeJun/roformer-sim-base-chinese')
model = Bert4Vec(mode='roformer-sim-small', model_name_or_path='WangZeJun/roformer-sim-small-chinese')
model = Bert4Vec(mode='paraphrase-multilingual-minilm', model_name_or_path='sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
mode 与 model_name_or_path 的对应关系如下:
| mode | model_name_or_path |
|---|---|
| simbert-base | WangZeJun/simbert-base-chinese |
| roformer-sim-base | WangZeJun/roformer-sim-base-chinese |
| roformer-sim-small | WangZeJun/roformer-sim-small-chinese |
| paraphrase-multilingual-minilm | sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 |
当 mode 设置完成后,无需设置 model_name_or_path,代码会从 https://huggingface.co/ 上自动下载相应的预训练模型权重并加载。
链接
https://github.com/ZhuiyiTechnology/simbert https://github.com/ZhuiyiTechnology/roformer-sim https://huggingface.co/sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 AI基础下载 机器学习交流qq群955171419,加入微信群请扫码: