
太强了,竟然可以根据指纹图像预测性别!
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

在进入神经网络世界之前,让我们先谈一谈指纹?众所周知,没有两个人具有相同的指纹,但是我们可以建立一个CNN模型来从指纹图像中预测性别吗?让我们看看……

在本文中,我们将创建一个可以根据指纹预测性别的卷积神经网络(CNN)模型。
实现步骤
• 了解数据集
• 重新构造数据集(以便使用keras 的Flow_from_directory函数)
• 定义一个简单的函数提取所需的特定标签
• 定义一个简单的函数读取图像、调整图像大小。
• 预处理训练和测试数据
• 从头开始构建简单的CNN模型
• 训练和测试模型
注:
如果你是CNN的新手?查看这篇文章以对它有一个很好的理解:
https://www.freecodecamp.org/news/an-intuitive-guide-to-convolutional-neural-networks-260c2de0a050/
•这篇文章假定您具有卷积神经网络(CNN)的知识。
•该代码是在kaggle内核中执行的。它提供免费的GPU和RAM,不足之处是空间有限,但您可以轻松删除不需要的变量。
数据集描述
来自Kaggle的数据集,包含约55,000张人类指纹图像:
https://www.kaggle.com/ruizgara/socofing
关于数据集的介绍:
• 它有两个主目录-Real目录和Altered目录
• Real目录包含真实人类指纹(无任何变化)
• Altered目录包含经过综合更改的指纹图像,包括用于遮盖、中央旋转和Z形切割的三种不同级别的更改。
• Altered目录进一步分为:Altered_Easy、Altered_hard和Altered_Medium目录
• Real图像的标签如下所示:“ 100__M_Left_thumb_finger.BMP”
• Altered图像的标签遵循以下格式:“ 100__M_Left_thumb_finger_CR.BMP”
格式化数据集

如果我们的数据集如上图所示那样构造,我们可以使用keras中的flow_from_directory()函数来加载数据集,这是从目录加载数据的一种非常简单的方法,它以目录名称作为类别。
话虽如此,数据中目录的名称并不是我们想要的类,因此我们将无法使用flow_from_directory函数。

另外,我们将不得不走更长的路来加载我们的数据——将图像转换为像素值,同时仅提取我们需要的标签“ F”和“ M”。然后我们才能使用数据进行训练、验证和测试。

请记住,Altered图像的格式应类似于:
“ 100__M_Left_thumb_finger_CR.BMP”
而Real图像的格式应类似于:
“ 100__M_Left_thumb_finger.BMP”
我们将基于“ M”和“ F”的性别进行分类。
第一步:从图像标签中提取性别。定义一个简单的函数来完成此任务:
#import necessary librariesimport numpy as npimport pandas as pdimport seaborn as snsimport tensorflow as tfimport osimport cv2import matplotlib.pyplot as plt#Function to extract labels for both real and altered imagesdef extract_label(img_path,train = True):filename, _ = os.path.splitext(os.path.basename(img_path))subject_id, etc = filename.split('__')#For Altered folderif train:gender, lr, finger, _, _ = etc.split('_')#For Real folderelse:gender, lr, finger, _ = etc.split('_')gender = 0 if gender == 'M' else 1lr = 0 if lr == 'Left' else 1if finger == 'thumb':finger = 0elif finger == 'index':finger = 1elif finger == 'middle':finger = 2elif finger == 'ring':finger = 3elif finger == 'little':finger = 4return np.array([gender], dtype=np.uint16)
有了上面函数就可以帮助我们提取标签。此函数遍历分配给它的图像路径(img_path)内的图像标签,拆分图像标签以获得F和M,然后将0分配给M,将1分配给F,返回一个0和1的数组(0代表M,1代表F)。将上述函数应用到Real目录中的图像,设置train = False,同时对于Altered目录中的图像设置train= True。
第二步:加载数据。创建另一个简单的函数来帮助您:
img_size = 96#Function to iterate through all the imagesdef loading_data(path,train):print("loading data from: ",path)data = []for img in os.listdir(path):try:img_array = cv2.imread(os.path.join(path, img), cv2.IMREAD_GRAYSCALE)img_resize = cv2.resize(img_array, (img_size, img_size))label = extract_label(os.path.join(path, img),train)data.append([label[0], img_resize ])except Exception as e:passdatareturn data
• 首先设定预期的图像尺寸 img_size = 96。
• 迭代:对路径(path)中的所有图像进行操作——读取图像并将它们转换为灰度图像(即黑白),然后将这些图像的像素值数组返回到img_array。
• img_resize包含已基于img_size调整大小的数组值。因此所有图像将具有相同的大小(96x96)。
• 调用extract_labels函数来获取标签,label中包含标签值。
• 所有标签和调整大小的图像数组添加到data列表 。
• 使用try, except块,传递异常
最后一步:分配各种目录,并在每个目录上使用loading_data 函数
Real_path = "../input/socofing/SOCOFing/Real"Easy_path = "../input/socofing/SOCOFing/Altered/Altered-Easy"Medium_path = "../input/socofing/SOCOFing/Altered/Altered-Medium"Hard_path = "../input/socofing/SOCOFing/Altered/Altered-Hard"Easy_data = loading_data(Easy_path, train = True)Medium_data = loading_data(Medium_path, train = True)Hard_data = loading_data(Hard_path, train = True)test = loading_data(Real_path, train = False)data = np.concatenate([Easy_data, Medium_data, Hard_data], axis=0)del Easy_data, Medium_data, Hard_data
训练集data: Easy_data包含了loading_data函数作用在Altered_Easy文件夹的结果,Medium_data、Hard_data分别对应了loading_data函数作用于Altered_Medium和Altered_hard文件夹的结果,注意函数设置设置train = True,将这些结果连接(串联)在一起,以便所有Altered图像都在单个变量data中。
测试集test:test包含loading_data函数作用于Real文件夹的结果,需要设定train = False。
注意:由于kaggle内核上的内存有限,不需要的变量将不断被删除。Easy_data,Medium_data和Hard_data被删除以创建空间。
数据预处理


必须先打乱我们的数据,然后再继续,这是为什么呢?因为在训练我们的模型时,如果神经网络不断看到1类型,它将很快假设所有数据是1类型。当它看到0时将很难学习,并且使用测试数据进行测试时会表现糟糕。因此需要将数据随机化(打乱)。
(1)随机化训练数据data和测试数据test数组。并查看data的格式
import randomrandom.shuffle(data)random.shuffle(test)

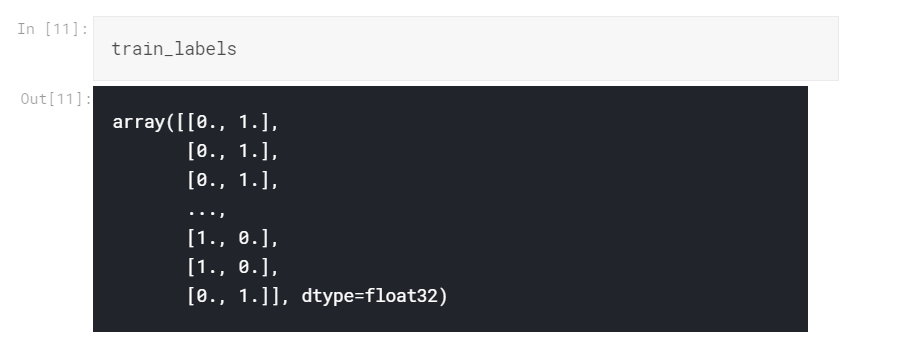
上图显示了data 包含的内容。对于第一个数组,标签值为0,然后是图像的像素值数组(像素值的范围是0到255)。
(2)分离图像数组和标签
img, labels = [], []for label, feature in data:labels.append(label)img.append(feature)train_data = np.array(img).reshape(-1, img_size, img_size, 1)train_data = train_data / 255.0from keras.utils.np_utils import to_categoricaltrain_labels = to_categorical(labels, num_classes = 2)del data
• 使用for循环,将图像数组和标签分成单独的列表
• img包含图像数组,labels包含标签值
• img和 labels是列表
• img中的值在重新调整之前再次转换为数组
• 图像的像素值的范围是0到255,通过除以255.0,像素值将按比例缩小到0到1,变为train_data。
• 标签也从列表转换为分类值,我们有两个类F和M类,分配给train_labels
让我们看看处理后的训练图像train_data和训练图像标签train_labels最后的样子

(3)最后一步,使用训练、验证和测试数据集来训练模型。已经有了训练和测试数据,我们仍然需要验证数据(test),因此我们可以使用来自sklearn库的train_test_splitfrom或使用keras的validation_split设置验证数据。
总而言之,我们将在Altered指纹图像(train_data,train_labels)上训练和验证模型然后在Real指纹图像(test)上测试模型。
建立CNN模型

(1)构建模型网络结构
• 使用tensorflow来构建我们的模型
• 从头开始构建一个简单的CNN模型,在每层都有两个卷积层之后将通过relu激活函数添加一个max pooling层
• 之后添加一个flatten层、一个隐藏密集层,然后是一个输出层。
• input_shape = [96,96,1](1是我们的灰度图像的结果)
• 类别数量是2
#Import necessary librariesfrom tensorflow.keras import Sequentialfrom tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flattenfrom tensorflow.keras import layersfrom tensorflow.keras import optimizersmodel = Sequential([Conv2D(32, 3, padding='same', activation='relu',kernel_initializer='he_uniform', input_shape = [96, 96, 1]),MaxPooling2D(2),Conv2D(32, 3, padding='same', kernel_initializer='he_uniform', activation='relu'),MaxPooling2D(2),Flatten(),Dense(128, kernel_initializer='he_uniform',activation = 'relu'),Dense(2, activation = 'softmax'),])
• 每个卷积层(Conv2D)包含32个大小为3(即3 x 3)的过滤器,仅在第一层中设置输入形状
• Max pooling(MaxPooling2D)的池化大小为2
• 只有一个具有128个神经单元的隐藏层(Dense),激活函数是relu
• 分类:将使用Dense大小为2(类编号)的输出层和softmax激活来结束网络。
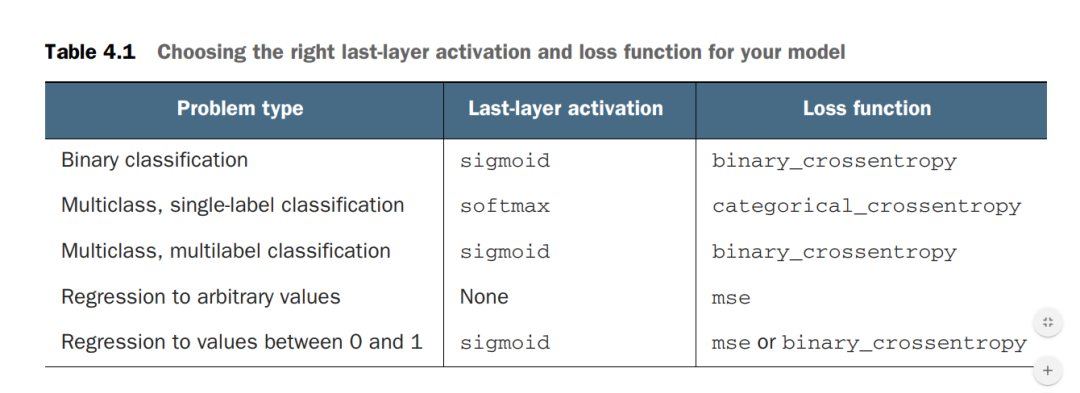
下图是“FrançoisChollet(keras的作者)的python深度学习”一书中的图片,详细说明了如何选择正确的最后一层激活和损失函数。
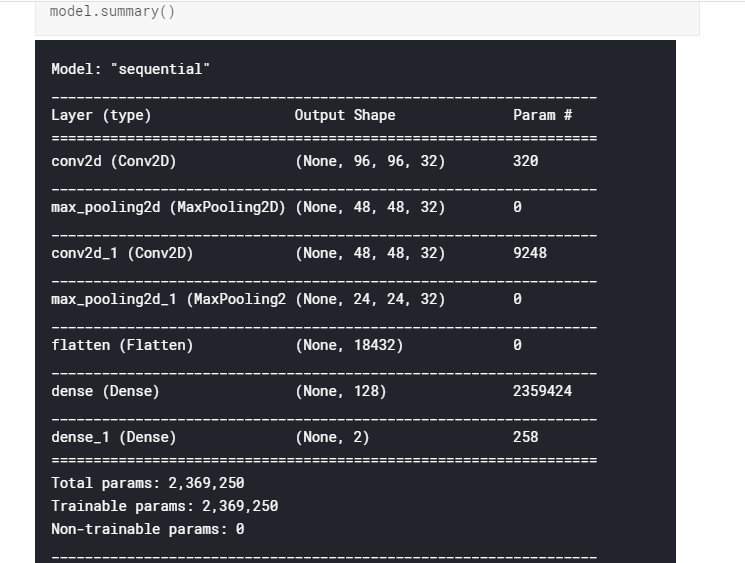
模型结构总结如下:
model.compile(optimizer = optimizers.Adam(1e-3), loss = 'categorical_crossentropy', metrics = ['accuracy'])early_stopping_cb = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
(2)编译模型:
使用Adam、学习率为0.001的优化器,categorical_crossentropy作为损失函数,准确性为metrics。使用early_stopping_call回调以防止过拟合。它会监视“val_loss”,如果10个epoch内“val_loss”没有增加,停止训练模型。
(3)拟合模型:
history = model.fit(train_data, train_labels, batch_size = 128, epochs = 30,validation_split = 0.2, callbacks = [early_stopping_cb], verbose = 1)
训练模型30个epoch(如果愿意,您可以训练更长的时间),我们设定validation_split = 0.2告诉模型将训练数据的20%用于验证。
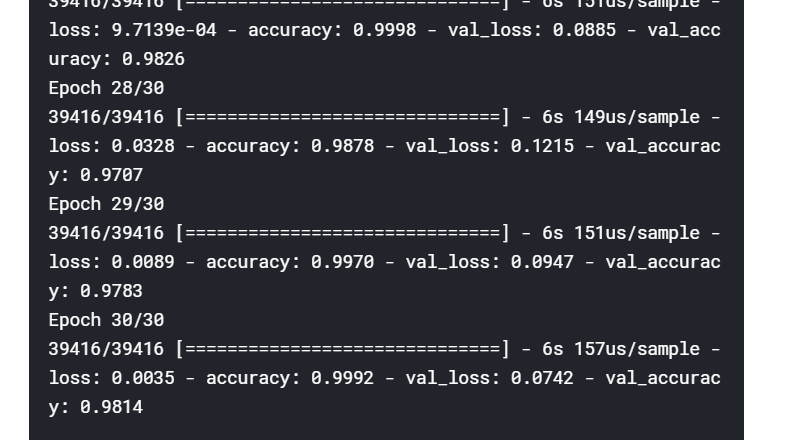
如上图所示的图像表明我们的模型正在训练中,它给出了训练损失和准确度的值,以及每个时期的验证损失和准确度的值。我们成功地训练了模型,训练准确度为99%,val准确度为98 %。还不错!
(4)绘制训练和验证数据的准确性和损失曲线:
import pandas as pdimport matplotlib.pyplot as pltpd.DataFrame(history.history).plot(figsize = (8,5))plt.grid(True)plt.gca().set_ylim(0,1)
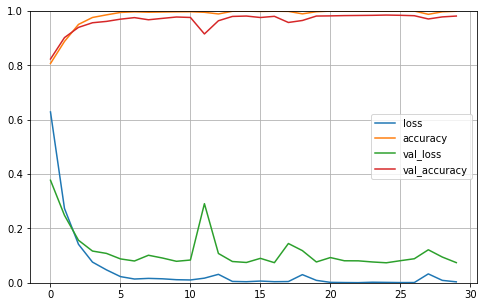
从上图可以看出,一切进展顺利。在我们的模型训练过程中没有重大的过拟合,两条损失曲线都随着精度的提高而逐渐减小。
测试模型
训练完模型后,想在以前未见过的数据上对其进行测试,以查看其性能如何。如前所述,在Real指纹图像上测试模型,我们已经有了 test数据。

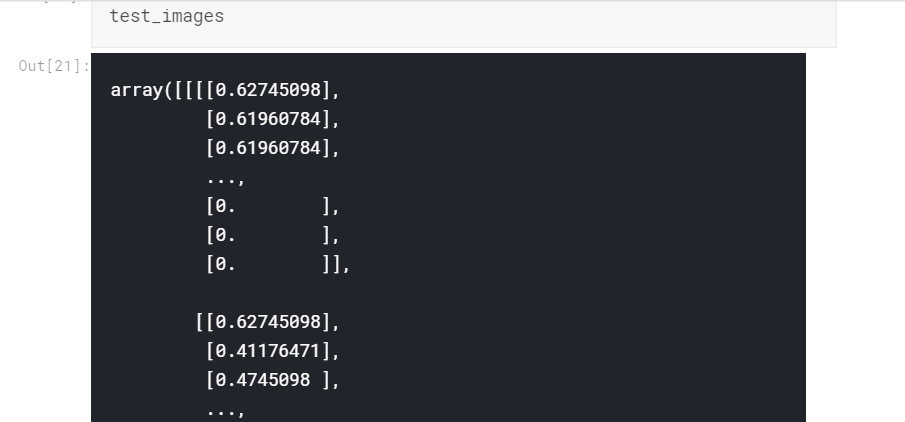
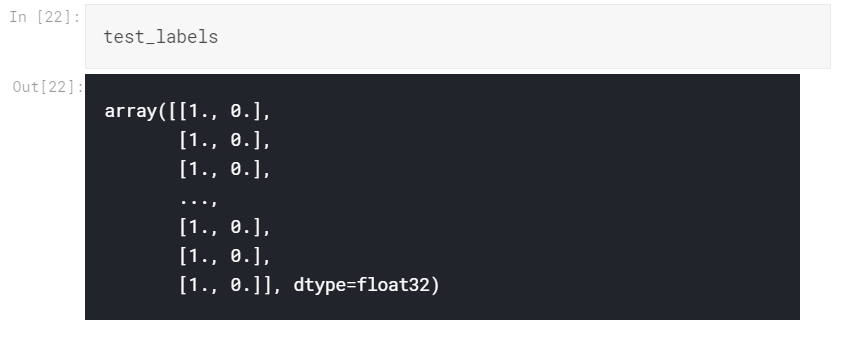
就像我们对训练数据所做的一样,我们将标签和图像阵列分开,整形并除以255.0
test_images, test_labels = [], []for label, feature in test:test_images.append(feature)test_labels.append(label)test_images = np.array(test_images).reshape(-1, img_size, img_size, 1)test_images = test_images / 255.0del testtest_labels = to_categorical(test_labels, num_classes = 2)
我们得到了与训练数据(train_data,train_labels)类似的结果
最后,我们通过对模型进行测试来评估测试数据,并给出准确性和损失值:
model.evaluate(test_images, test_labels)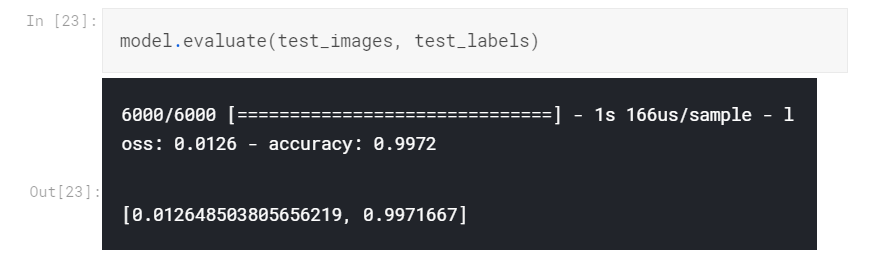
验证集的准确度为99.72%,损失值为0.0126。太好了,您刚刚成功建立了指纹性别分类模型!

结论
总而言之,我们从头开始构建一个简单的CNN,基于指纹图像来预测性别。我们提取了特定标签,将图像转换为数组,预处理了我们的数据集,还预留了训练数据供我们的模型进行训练。在测试数据上测试了我们的模型,并达到了99%的准确性。
最后说明
只要您有足够的图像来训练,使用CNN就能对几乎所有图像进行分类只是神经网络的众多奇迹之一。有很多东西需要学习和探索,我们只是不准备好迎接令人惊奇的事情。

参考
https://www.kaggle.com/abolarinbukola/fingerprint-gender-classification-cnn
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~