
竟然重新开源了,太强了!!
大家好,我是DASOU。
先说一个小事情,因为球友核心交流群建的比较晚,导致一些加入星球时间比较早的成员没有进核心交流群的,这些朋友记得去置顶帖加我大号微信,我拉大家进群哈。
群内的讨论氛围我认为还是不错的,有球友遇到问题,除了在星球提问,也可以在群内咨询,很多朋友有经验的话都会回复的。
好的,说回正事。
之前7月底的时候在公众号推荐了一个阿里达摩院开源的Chinese-CLIP项目,当时因为某些原因,repo关闭了,还是可惜了一阵~
前段时间,项目的作者同学私信我说repo又重新开源,而且较第一版做了比较大的更新。
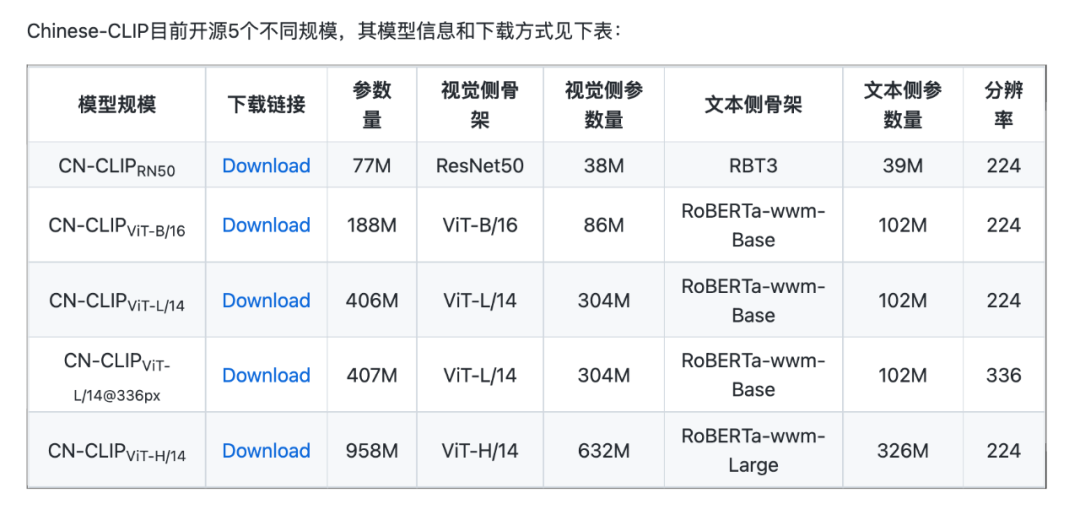
同时一次性开源了5个规模的中文CLIP模型,包括ResNet、ViT-B/16、ViT-L/14、ViT-L/14@336px和ViT-H/14,可以满足不同人和不同业务场景的需求。
代码地址在这里:https://github.com/OFA-Sys/Chinese-CLIP/
关于这个模型的技术报告在11月份的时候就已经在arxiv上放出来了,当时有刷到,不过存起来就忘了看了,囧~~
感兴趣的可以去看下,地址在这里:https://arxiv.org/abs/2211.01335
首先说下我看一些同学评论这个工作开源的意义不大,只是简单的汉化CLIP。
其实不是的,这个工作我觉得还挺有意义的,很多大厂核心组都做自己的多模态预训练模型,但是能开源出来的,少之又少。
有这么一个效果很好的模型放出来对一些小组做业务或者同学打比赛或者某些代码能力不好的朋友验证自己idea等等门槛都降低了不少。
论文的整体思路还是挺简单清晰的。
训练CLIP的时候大部分人第一个想法就是文本侧用BEERT类预训练模型初始化,然后做对比学习就可以了。
不过这个项目在训练的时候用的是两阶段的预训练,大体思路是这样的:
先用在openai clip 图像参数初始化图像侧
再用中文RoBerta初始化文本侧参数
第一阶段,冻结住图像侧参数,进行对比学习
第二阶段,放开图像侧参数冻结,继续进行对比学习。
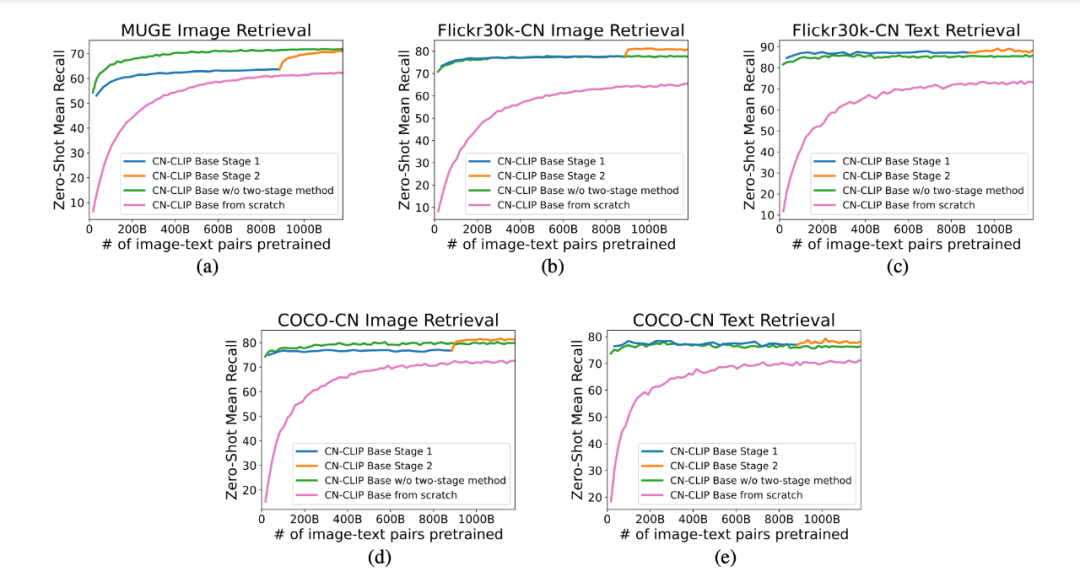
看了下实验结果图,两个阶段效果确实会好一些(MUGE不是,不过差距也不大)。
数据集的话,大量是2亿个量级,主要是LAION-5B和华为的悟空数据集。
悟空数据集之前也介绍过,看这里。
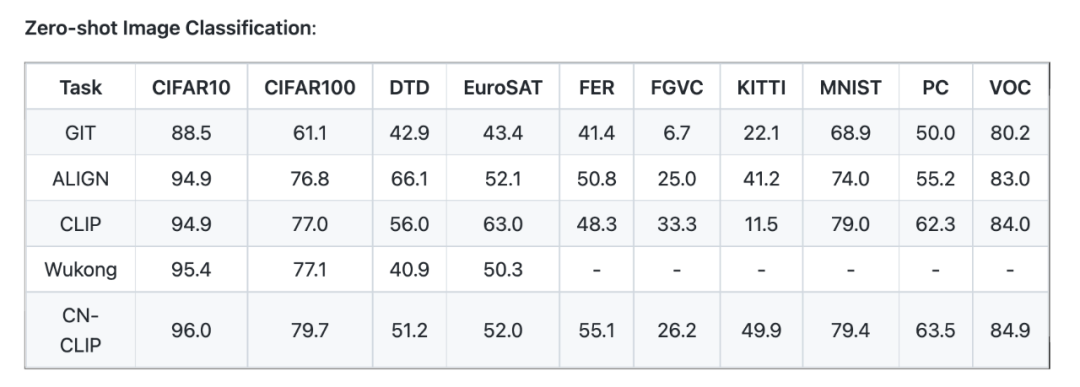
针对图文检索任务,主要是在MUGE Retrieval、Flickr30K-CN和COCO-CN上进行了zero-shot和finetune的实验。针对图像零样本分类,主要是在ELEVATER的10个数据集上进行了实验。
检索任务基本达到SOTA,零样本分类一部分数据集上效果还是不错的。
官方文档给了一个图文特征提取计算相似度的例子,以及跨模态检索以及零样本图像分类教程。
在使用之前,直接安装cn_clip:
# 通过pip安装
pip install cn_clip
# 或者从源代码安装
cd Chinese-CLIP
pip install -e .然后就可以运行官方给出来的快速上手的例子和教程:
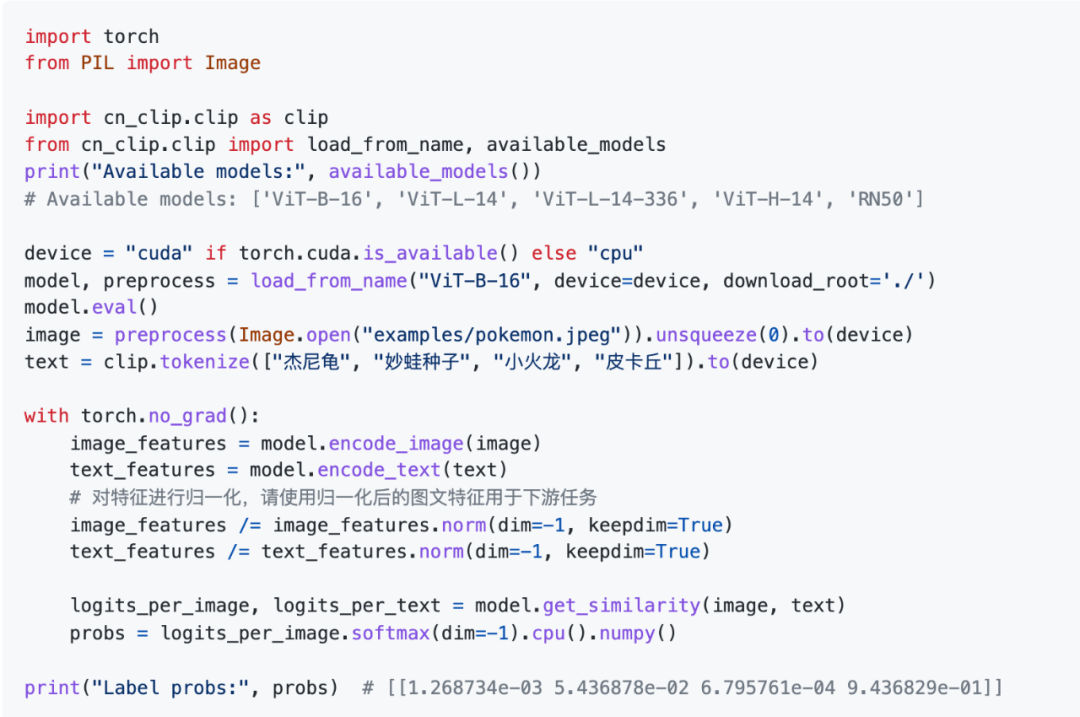
更多更详细的使用教程大家直接去官方的Readme文档去看就好了~~
推荐阅读:
2. 年底跳槽,一定要谨慎!!