
7大经典回归模型总结
今天给大家介绍机器学习建模中7大经典的回归分析模型。
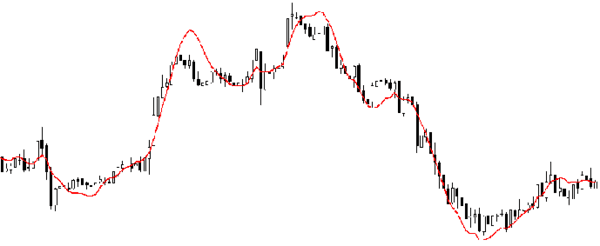
它表明自变量和因变量之间的显著关系; 它表明多个自变量对一个因变量的影响强度。


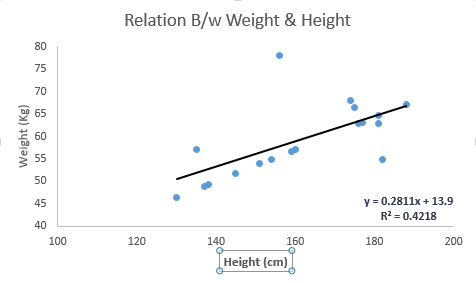
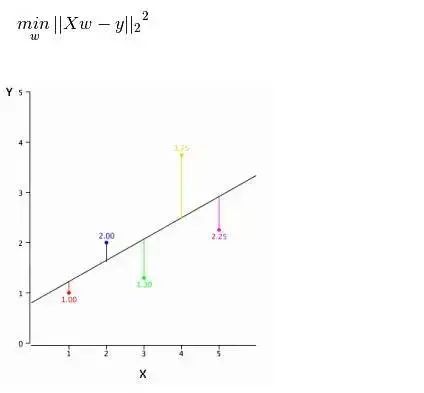
要点: 1.自变量与因变量之间必须有线性关系 2.多元回归存在多重共线性,自相关性和异方差性。 3.线性回归对异常值非常敏感。它会严重影响回归线,最终影响预测值。 4.多重共线性会增加系数估计值的方差,使得在模型轻微变化下,估计非常敏感。结果就是系数估计值不稳定 5.在多个自变量的情况下,我们可以使用向前选择法,向后剔除法和逐步筛选法来选择最重要的自变量。
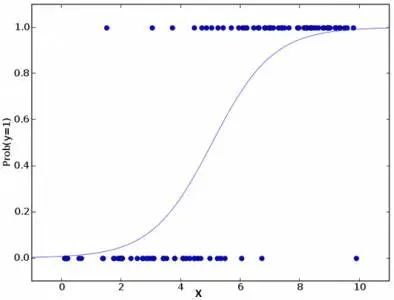
要点: 1.它广泛的用于分类问题。 2.逻辑回归不要求自变量和因变量是线性关系。它可以处理各种类型的关系,因为它对预测的相对风险指数OR使用了一个非线性的log转换。 3.为了避免过拟合和欠拟合,我们应该包括所有重要的变量。有一个很好的方法来确保这种情况,就是使用逐步筛选方法来估计逻辑回归。 4.它需要大的样本量,因为在样本数量较少的情况下,极大似然估计的效果比普通的最小二乘法差。 5.自变量不应该相互关联的,即不具有多重共线性。然而,在分析和建模中,我们可以选择包含分类变量相互作用的影响。 6.如果因变量的值是定序变量,则称它为序逻辑回归。 7.如果因变量是多类的话,则称它为多元逻辑回归。
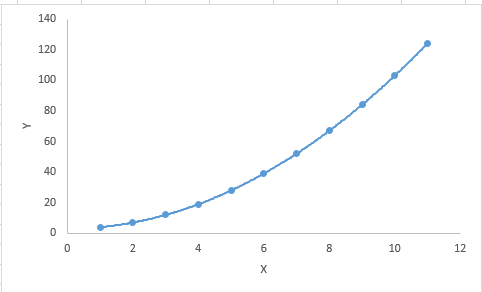
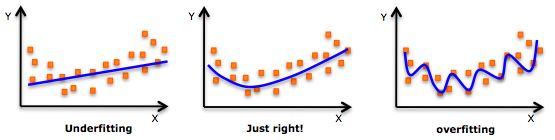
重点: 虽然会有一个诱导可以拟合一个高次多项式并得到较低的错误,但这可能会导致过拟合。你需要经常画出关系图来查看拟合情况,并且专注于保证拟合合理,既没有过拟合又没有欠拟合。
标准逐步回归法做两件事情。即增加和删除每个步骤所需的预测。 向前选择法从模型中最显著的预测开始,然后为每一步添加变量。 向后剔除法与模型的所有预测同时开始,然后在每一步消除最小显着性的变量。
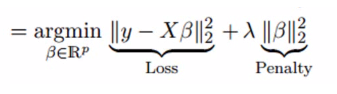
要点: 1.除常数项以外,这种回归的假设与最小二乘回归类似; 2.它收缩了相关系数的值,但没有达到零,这表明它没有特征选择功能 3.这是一个正则化方法,并且使用的是L2正则化。
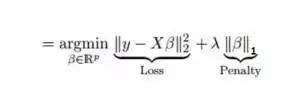
要点: 1.除常数项以外,这种回归的假设与最小二乘回归类似; 2.它收缩系数接近零(等于零),这确实有助于特征选择; 3.这是一个正则化方法,使用的是L1正则化; 如果预测的一组变量是高度相关的,Lasso 会选出其中一个变量并且将其它的收缩为零。
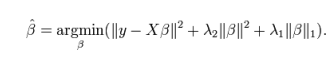
要点: 1.在高度相关变量的情况下,它会产生群体效应; 2.选择变量的数目没有限制; 3.它可以承受双重收缩。
评论