
7大特征交互模型,最好的深度学习推荐算法总结
👆点击“博文视点Broadview”,获取更多书讯

深度学习自出现以来,不断改变着人工智能领域的技术发展,推荐系统领域的研究同样也受到了深远的影响。
一方面,研究人员利用深度学习技术提升传统推荐算法的能力;另一方面,研究人员尝试用深度学习的思想来设计新的推荐算法。
基于深度学习的推荐算法研究不仅在学术界百花齐放,目前也受到了工业界的重视和广泛采用。深度学习具有强大的表征学习和函数拟合能力,它能在众多方面改革传统的推荐算法,如协同过滤、特征交互、图表示学习、序列推荐、知识融合及深度强化学习。下面将介绍推荐系统中较为重要的方向——特征交互。
基于隐向量的协同过滤的方法将用户和物品独立地映射到低维空间,计算简单,很适合作为召回模型或者粗排模型。
而推荐系统在精排阶段为了能够更准确地刻画用户对物品的兴趣,往往会考虑更丰富的情景特征,例如时间、地点等上下文信息,以及捕捉更细粒度的特征交互,例如用户画像和物品属性之间的交互作用。
在过去,人们通过手动设计交互特征,或者利用梯度提升树自动提取和选择一些有用的交互特征,但这样终究只能覆盖到训练集里面出现过的特征模式,不能泛化到未在训练集中出现过的特征组合。随着深度学习技术的快速发展,自动特征交互方式也迎来了新的思路。

AFM 模型
因子分解机(Factorization Machine,FM)模型的特点是考虑了所有可能的二阶特征组合。
当数据集中存在大量不必要做特征交互的组合时,这些特征的交互产生的噪声可能会影响模型的性能。
因此,Jun Xiao 等人提出了基于注意力网络调整的因子分解机(Attentional Factorization Machines,AFM)。AFM 模型的整体结构如下图所示。
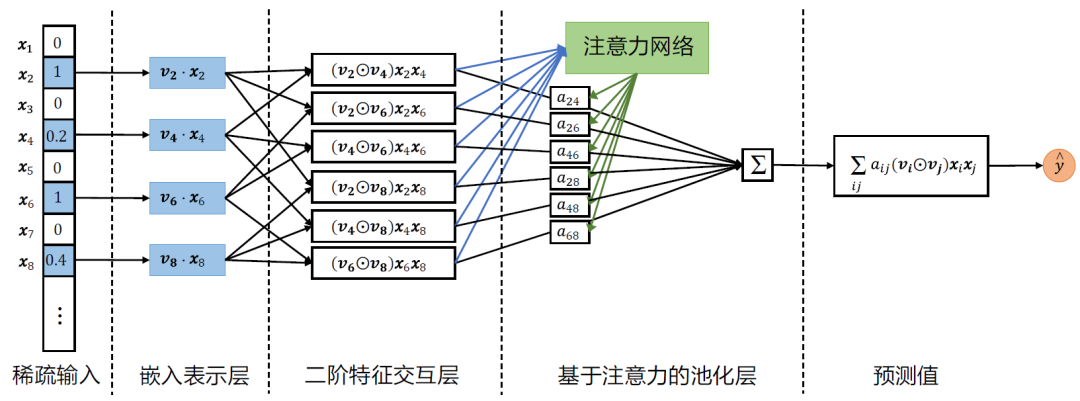
AFM 模型的整体结构
PNN 模型
在推荐系统的精排模型或者广告点击率预估模型中,输入的样本往往有一个特点:特征是高维稀疏的。
例如,用户和物品的ID、离散化的时间、类别类型的属性,都可以作为有用的特征出现在样本数据中。
这种高维稀疏的特征可以归到不同的特征域(field),每个特征域用独热编码或者多热编码表示。
这样做的好处是,虽然每个样本的特征数量是可变的,所有样本的特征域的数量却是固定的,因此,可以很方便地把所有特征域对应的隐向量拼接起来,输入到MLP 进行下一步的操作。一个简单的样本示例如下:
这个样本有三个特征域:日期、性别和地点。每个特征域内用一个独热编码表示。
一种简单的做法是,通过特征嵌入查找(Embedding Lookup)得到每个特征域的低维表示向量,然后将所有特征域的表示向量拼接起来,输入MLP 计算高阶特征交互。
这样的做法本质上是通过求和的形式把各个特征域的表示向量组合到MLP 中。
为了引入更有效的特征交互,Yanru Qu 等人提出PNN(Product-based Neural Networks)模型,创新性地引入了一个特征域之间的显式二阶交互层,作用在特征嵌入层和MLP 层之间,具体模型框架如下图所示。

PNN 模型结构图
Wide & Deep 模型
Wide & Deep 模型是谷歌公司于2016 年推出的结合深度学习的推荐模型,一经问世便广受好评,目前也成了工业界主流的推荐模型之一。
Wide &Deep 模型强调一个好的推荐系统应该兼顾记忆性(memorization)和泛化性(generalization)。
记忆性是指模型能够捕捉数据集中频繁共现的特征规律,并建立它们和标签直接的关系。这一能力可以通过枚举交叉特征(cross-productfeature),并用一个逻辑回归模型去学习这些交叉特征的关联系数来实现。
例如,如果在训练数据集中,用户经常点击某个主题、名人相关的新闻,那么<用户ID,主题ID,如下图所示。
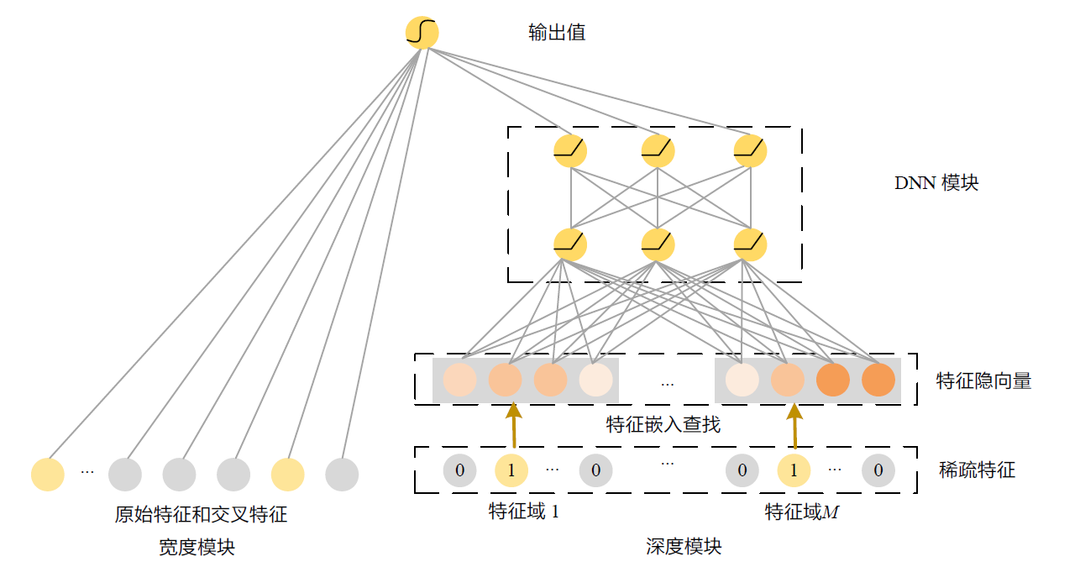
 Wide & Deep 模型结构
Wide & Deep 模型结构
模型分为左右两个部分,左边是宽度模块,负责记忆性。右边是深度模块,负责泛化性,输入内容是稀疏特征,经过特征隐向量嵌入查找得到低维的稠密向量表示。
DeepFM 模型
在Wide & Deep 模型的深度模块中,DNN 模块可以自动学习特征之间的高阶交互关系。然而,它并不能保证学习到良好的低阶特征交互。
同时,宽度模块可以通过人工提取交叉特征的方式引入部分的低阶特征交互关系,但是人们依旧不能期望能通过手工枚举的形式罗列所有有效的特征组合。
而经典的因子分解机模型,旨在显式地建模特征之间的二阶交互关系,能自动捕捉所有的二阶特征交互关系。
为了弥补现有的模型要么太偏向于学习高阶特征交互,要么太偏向于学习线性特征,或者依赖于人工经验来提取低阶特征交互的缺点。
Huifeng Guo 等人提出了DeepFM 模型,将因子分解机和多层感知机融合到一个模型中,使得新的模型能同时拥有良好的建模低阶特征交互(来自FM 模块)和高阶特征交互(来自DNN 模块)的能力,如下图所示。
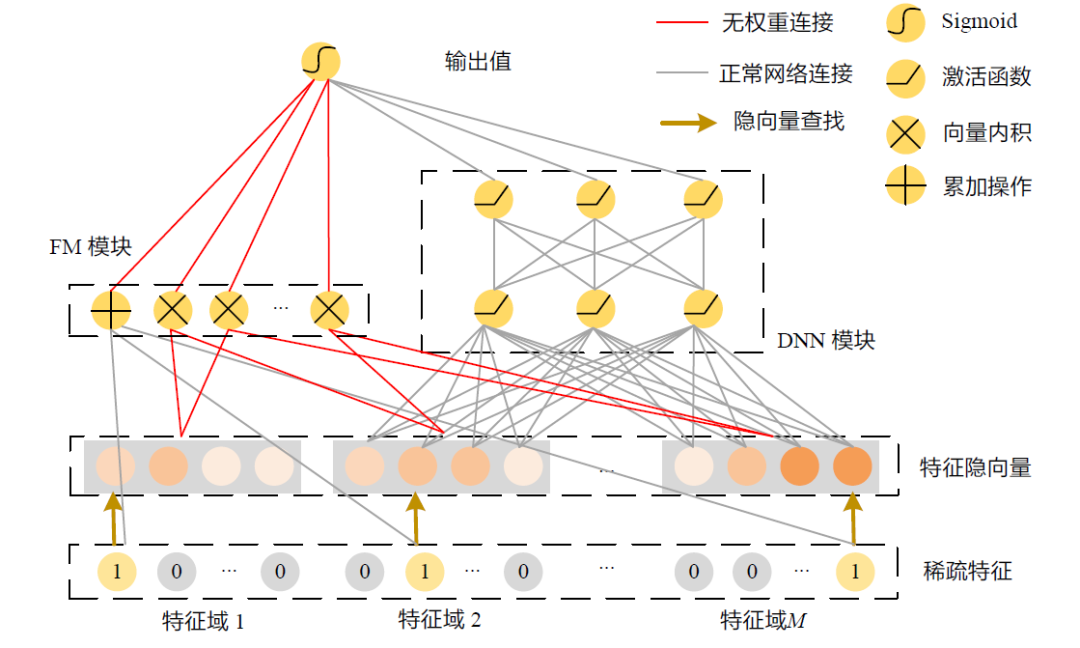
DeepFM 模型结构
DCN 模型
人们普遍认识到,线性模型虽然简单方便,有高扩展性且易于解释,但是它的表达能力有限,依赖于工程师手工设计交叉特征,并且不能泛化到训练数据中未曾出现过的特征组合。
到目前为止,自动学习高阶特征交互的能力还是依赖于DNN。因此,学者们对DNN 在特征交互上的进一步改进颇为感兴趣。
考虑到DNN 的特点是只能隐式地对潜在的高阶特征交互进行建模,而其建模过程和结果都是一个黑盒,并不能保证能够学习到全面的高阶特征交互。
是否能够通过设计一种新的深度神经网络,使得它在高阶特征交互的学习上有某种良好的特性呢?
带着这种问题,Ruoxi Wang 等人提出了DCN模型,它具有非常优异的特点:能够显式地捕捉高阶特征交互,并且阶数可控。
整个模型的框架和Wide&Deep、DeepFM 类似,也是分成左右两个部分,本节只讨论DCN 的特殊部分——交叉网络(Cross Network),结构如下图所示。
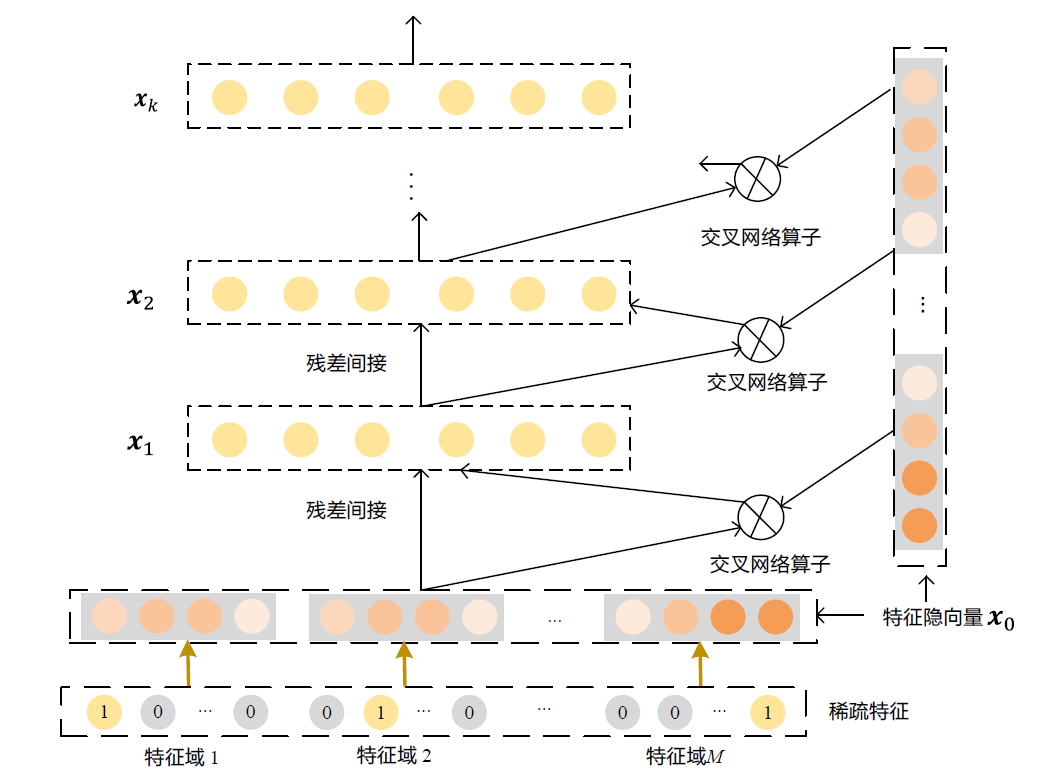
DCN 中的交叉网络模块
xDeepFM 模型
DCN 的发表很快吸引了许多业内学者的浓厚兴趣。其中,Jianxun Lian 等人发现,虽然DCN 中的交叉网络具有简洁、计算高效的优点,但同时也有一个明显的缺点,即交叉网络最终的隐状态的形式有很大的局限性,它只能是原始特征隐向量
为了探索更自由的显式高阶特征交互,Jianxun Lian 等人提出了一种新的网络结构——压缩交互网络(Compressed Interaction Network,CIN)。
压缩交互网络的灵感来自两个方面。第一,用了向量级别(vector-wise)的交互取代原素级别(bit-wise)的交互。
既然用隐向量来表示一个特征域,那么不同的特征域之间的交互是有意义的,而同一个特征内的元素之间的交互是无意义的。
同时,DNN 采用的是元素级别的全连接操作,它虽然在理论上能建模任意复杂的函数,但是要学好它并不容易。
尤其是在推荐场景中特征交互明显的数据集上,DNN 是否真的能高效地刻画高阶特征交互仍然是一个未知数。
无独有偶,Alex Beutel 等人在Latent Cross 一文中也提倡向量级别的交互,并且通过一个模拟数据经验性地证明了,要训练好一个DNN 去捕捉特征交互并不容易。
第二,既然深度神经网络的优势在于自动抽取复杂的特征,例如从图像、文本和语音等复杂的原始数据中自动提取抽象的特征,那么是否可以把所有的特征组合看成散乱无章的原始数据,期望利用神经网络去从中自动提取到有用的特征交互呢?
答案是可能的,这便是压缩交互网络中“压缩”一词的由来。
下图展示了压缩交互网络的整体结构。
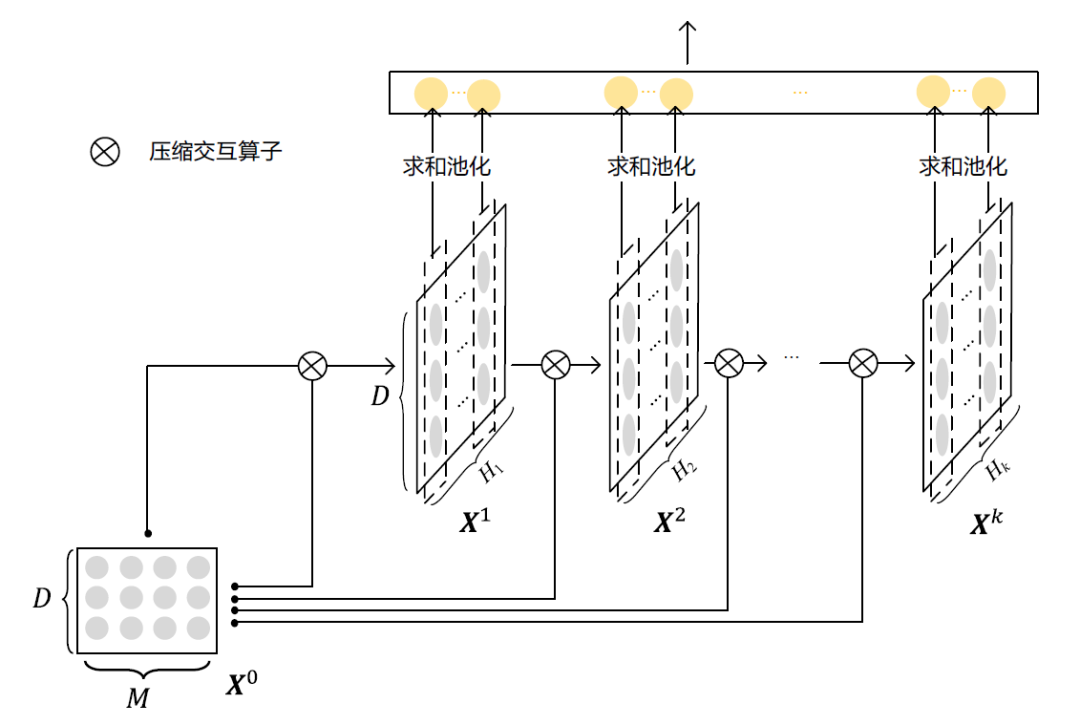
压缩交互网络的整体结构
因为每层都是前一层和输入特征嵌入矩阵的交互操作,因此网络每增加一层,能够达到的特征交互阶数就增加了一层。
为了让模型从低阶到高阶的特征交互都能充分地捕捉到,每层的特征图都会历经一个求和池化操作并输送给最终的预测单元。
值得一提的是,压缩交互网络的结构与循环神经网络(RNN)和卷积神经网络(CNN)都颇有渊源。
与循环神经网络相同的是,压缩交互网络的每次计算都取决于前一层网络的激活值和一个输入值;不同的是,循环神经网络每次输入的内容是新的(例如,一个句子里面的不同单词),每层神经元的参数是共享的;而压缩交互网络的每次输入的内容是固定的(总是原始的特征嵌入矩阵),而每层神经元的参数是新的。
与卷积神经网络异曲同工之处是,压缩交互网络的中间计算结果
AutoInt 模型
随着Transformer 模型在自然语言处理任务上的成功应用,学者们也逐渐探索Transformer 的结构如何应用在学习特征交互上。
Weiping Song 等人将Transformer 中的核心模块Multi-head Self-Attention(MSA)——作用在推荐任务的特征嵌入表示层,用来自动学习高阶的特征交互。
MSA 中有两个重要单元——自注意力机制(self-attention)和多头映射(multi-head)。
自注意力机制旨在改善特征的隐向量表示,使得新的向量可以适量包含其他特征的信息(称为上下文感知的向量表示),而不再是独自的ID 表示。
它本质上是一种以< 查询词,索引键,内容值> 为形式的特征交互过程。
每个特征以自己的向量表示作为查询词(Query),和其他特征的向量为索引键(Key)计算相似度,再以相似度为权重,把其他特征的向量(作为内容值Value)作用在自身向量上。
特征交互的其他思路
如何有效地学习特征交互是推荐系统精排、广告点击率等阶段中十分重要的一个难点。这方面的研究工作还有很多,受篇幅所限,本文不能一一列举。感兴趣的读者可以参考相关文章继续阅读。
例如,新浪微博AI Lab 团队提出的FiBiNet模型,从两个方面改进了现有特征交互方法:将传统的两个向量点积或者哈达玛积操作替换成双线性乘法操作,用来捕捉更细粒度的特征交互关系;引入了SENET 模块,动态地调整特征向量的重要程度。
华为诺亚方舟实验室提出的两阶段训练模型AutoFIS,能够自动捕捉到有意义的特征交互,摒弃无意义的甚至会带来噪声的特征交互,最终能同时在效果和效率上改进已有模型。
阿里妈妈团队基于DIN 模型的框架,提出CAN 模型,把特征交互形式化成一种基于DNN 的特征变换。例如,要得到特征A 相对于目标特征B 的隐向量表示,只需要为特征B 专门引入一组DNN 的参数,当把特征A的原始隐向量输入给这个DNN 时,这个DNN 的输出向量就是特征A 和特征B 交互过后的隐向量。
本文节选自《推荐系统:前沿与实践》(李东胜 练建勋 张乐 任侃 卢暾 邬涛 谢幸 著)。
本文节选自《推荐系统:前沿与实践》(李东胜 练建勋 张乐 任侃 卢暾 邬涛 谢幸 著)。
专享六折优惠,扫描下方二维码抢购!
发布:刘恩惠 审核:陈歆懿

如果喜欢本文 欢迎 在看丨留言丨分享至朋友圈 三连 热文推荐
▼点击阅读原文,了解本书详情~