
一区SCI新目标检测框架 | one-shot的条件目标检测

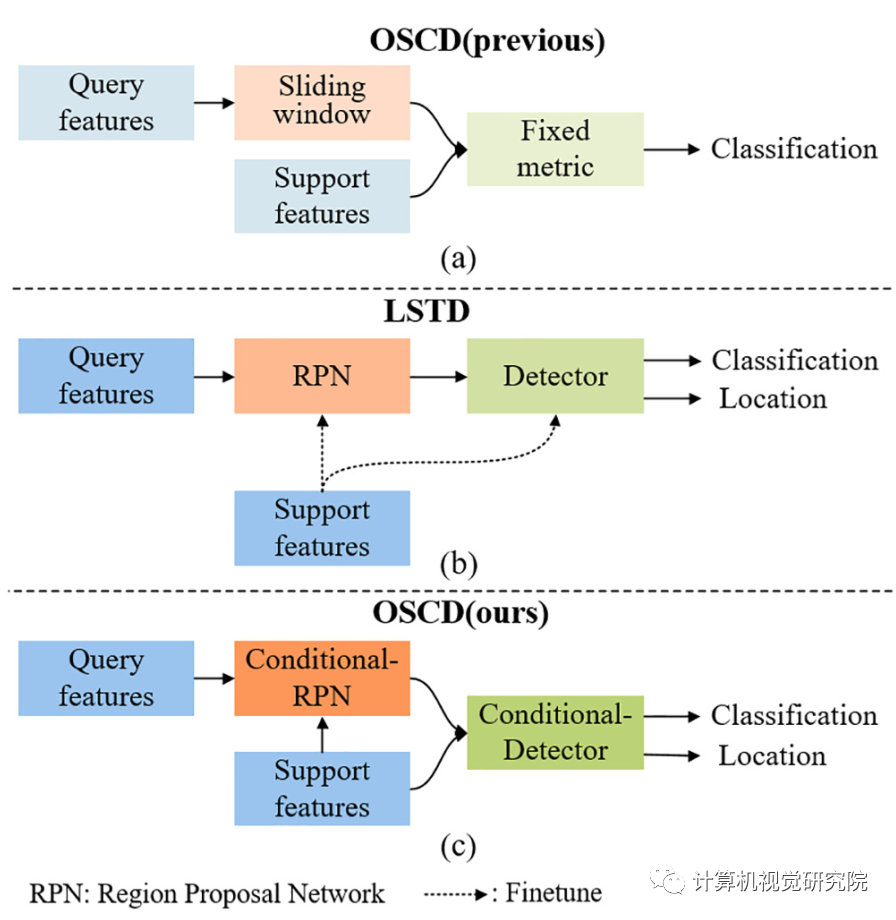
由于这两种方法的基本相似性,结果表明,这两种方法通过将新类的support图像作为条件处理,可以与条件目标检测模型相等。
然后,研究者就提出了将检测问题更好地命名为one-shot条件目标检测。并设计了一个基于可学习度量和two-stages检测模型的通用one-shot条件目标检测框架(OSCD),如上图(c)。
条件目标检测与目标检测之间存在一些区别。
首先,他们有不同的目标。条件目标检测的目的是检测与测试图像中给定的条件图像相似的对象。因此,条件目标检测可以检测到属于不可见类别的对象。而目标检测是检测所有属于训练类别的对象,不能检测看不见类对象;其次,这两种方法有不同的训练方式。条件目标检测的训练是基于support和query图像对。而目标检测是标准的监督学习,并有足够的训练样本;第三,这两种方法有不同的评价标准,在各种support和query图像对上评估了条件目标检测模型,而目标检测模型则在许多检测图像上进行了评估。
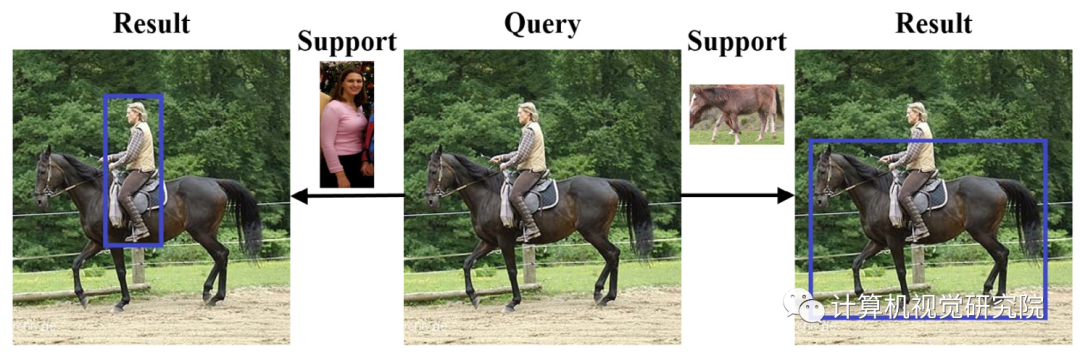
在one-shot条件目标检测的设置中,数据通常成对组织,由support和query图像组成。support图像通常包含一个主导的目标对象(人或马),并且模型应该能够在query图像中检测到属于目标对象类别的对象。
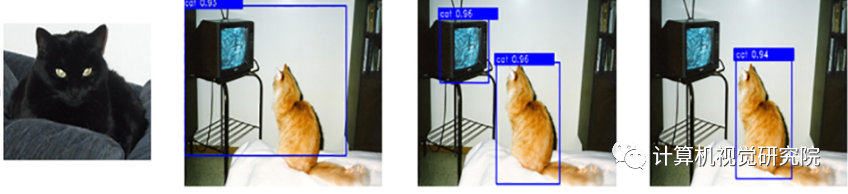
对于目标检测,假设在感兴趣的类中没有足够的样本,从而导致公共监督学习方法的性能较差。此外,我们可能不知道在未来的任务中存在哪些类别。更严重的挑战是,“目标”可以是任何令人感兴趣的模式。所有这些问题都使得目标检测任务对传统方法来说极其困难。因此,提出了one-shot的条件目标检测方法来解决上述问题。
如下图所示。One-shot条件检测的目标是根据查询图像中的给定条件(目标对象的单个支持图像)来检测对象。在one-shot条件检测的情况下,在许多支持查询的可见类图像对上训练一个模型,以获得强先验。一旦训练,模型可以从具有单一支持图像的看不见类中检测属于目标类别的所有对象。
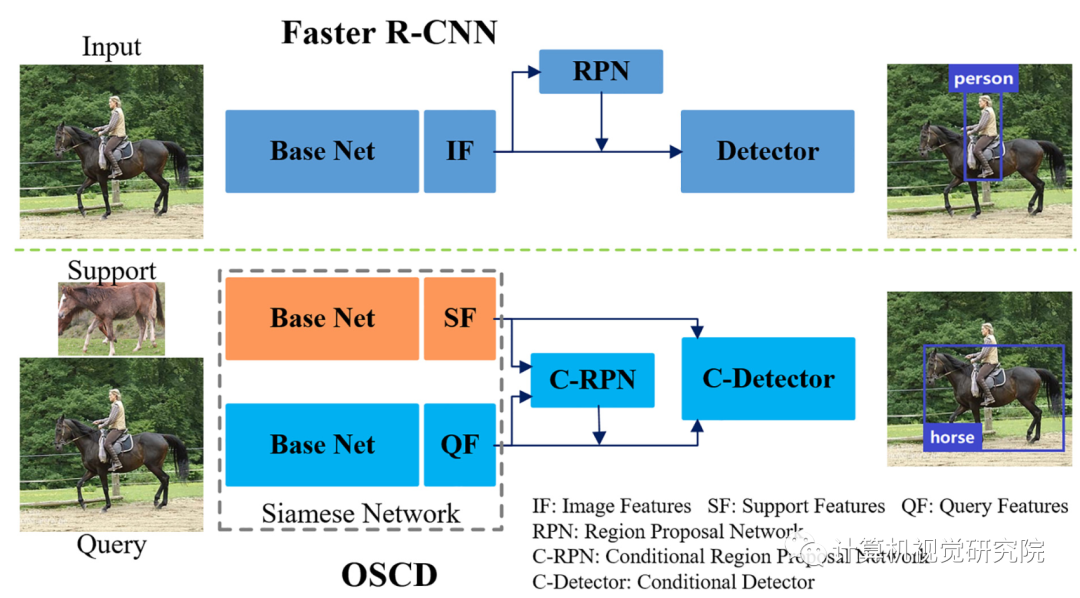
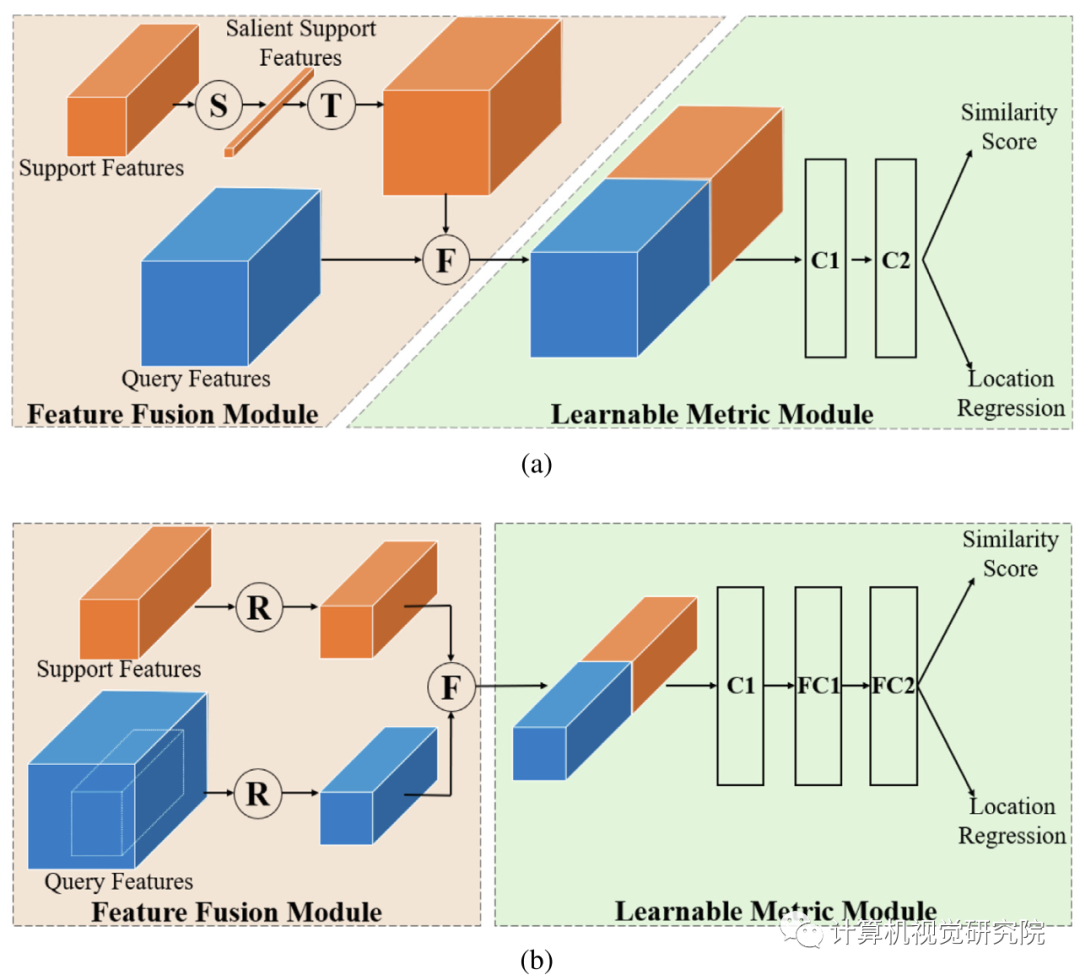
上图,(a)C-RPN:S操作连接全局平均和最大池support features,并通过卷积层生成显著support features,然后T平铺突出support features使平铺support features具有与query features相同的空间大小,因此F可以连接平铺support features来查询特征。C1、C2是两个卷积层。(b)C-Detector:从C-RPN中选择候选区域的query features,然后将它们与support features结合起来。R表示调整大小的操作,F表示深度上的连接。可学习的度量模块由一个用于降维的卷积层和两个用于检测的全连接层组成。
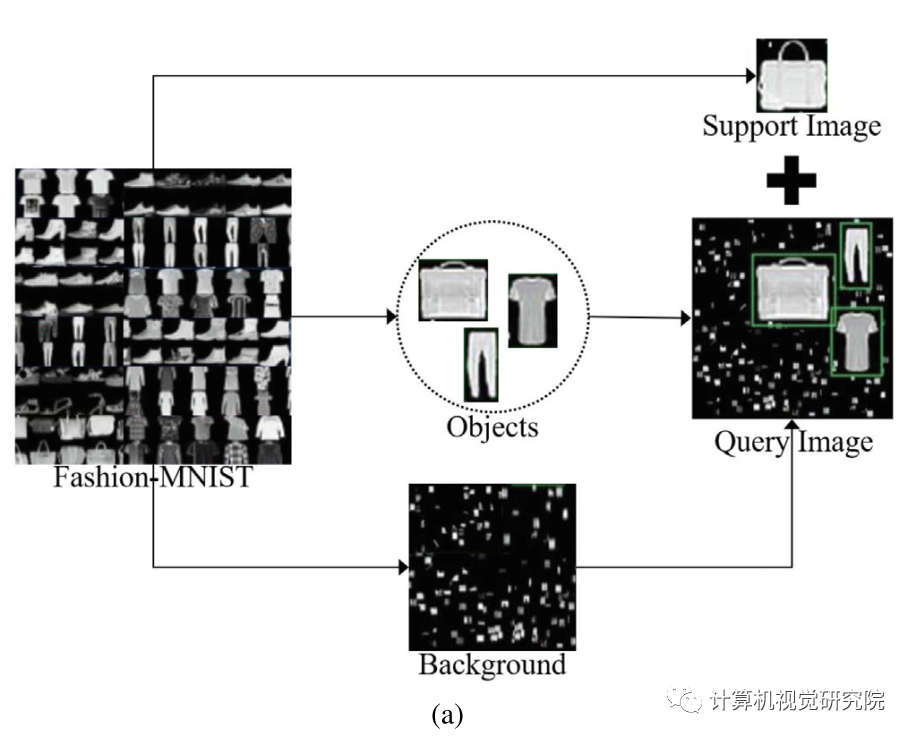

(b) Examples for the Fashion-OSCD dataset. Green boxes denote ground truth bounding boxes. Each image contains as much as 3 objects with multiple scales and aspect ratios.


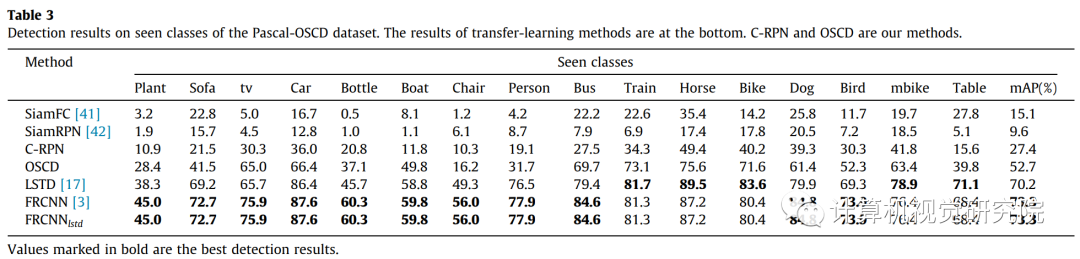


✄------------------------------------------------
双一流高校研究生团队创建,专注于计算机视觉原创并分享相关知识☞
闻道有先后,术业有专攻,如是而已╮(╯_╰)╭