
【NLP】四万字全面详解 | 深度学习中的注意力机制(二)
NewBeeNLP原创出品
公众号专栏作者@蘑菇先生
知乎 | 蘑菇先生学习记
 前情提要:四万字全面详解 | 深度学习中的注意力机制(一)
前情提要:四万字全面详解 | 深度学习中的注意力机制(一)
目前深度学习中热点之一就是注意力机制(Attention Mechanisms)。Attention源于人类视觉系统,当人类观察外界事物的时候,一般不会把事物当成一个整体去看,往往倾向于根据需要选择性的去获取被观察事物的某些重要部分,比如我们看到一个人时,往往先Attend到这个人的脸,然后再把不同区域的信息组合起来,形成一个对被观察事物的整体印象。
「同理,Attention Mechanisms可以帮助模型对输入的每个部分赋予不同的权重,抽取出更加关键及重要的信息,使模型做出更加准确的判断,同时不会对模型的计算和存储带来更大的开销,这也是Attention Mechanism应用如此广泛的原因」
在上一篇文章中,我们分享了seq2seq以及普通attention网络,今天来看看Attention机制的各种变体。
本部分介绍Attention机制的各种变体。包括但不限于:
「基于强化学习的注意力机制」:选择性的Attend输入的某个部分 「全局&局部注意力机制」:其中,局部注意力机制可以选择性的Attend输入的某些部分 「多维度注意力机制」:捕获不同特征空间中的Attention特征。 「多源注意力机制」:Attend到多种源语言语句 「层次化注意力机制」:word->sentence->document 「注意力之上嵌一个注意力」:和层次化Attention有点像。 「多跳注意力机制」:和前面两种有点像,但是做法不太一样。且借助残差连接等机制,可以使用更深的网络构造多跳Attention。使得模型在得到下一个注意力时,能够考虑到之前的已经注意过的词。 「使用拷贝机制的注意力机制」:在生成式Attention基础上,添加具备拷贝输入源语句某部分子序列的能力。 「基于记忆的注意力机制」:把Attention抽象成Query,Key,Value三者之间的交互;引入先验构造记忆库。 「自注意力机制」:自己和自己做attention,使得每个位置的词都有全局的语义信息,有利于建立长依赖关系。
Reinforcement-learning based Attention
NIPS2014: Recurrent Models of Visual Attention[1] ICLR2015: Multiple Object Recognition with Visual Attention [2]
NIPS2014论文应该是最早的Attention雏形,虽然和我们通常所说的、广泛应用于Seq2Seq的Attention机制不太一样,但是还是值得提一下。这是Google DeepMind2014年提出的一篇计算机视觉领域的文章,适用于处理图像序列或帧序列来进行场景感知或处理(例如Video Caption)。
其动机在于随着分辨率提高,计算量不断增长,神经网络难以在实时应用场景中,快速处理这么大的计算量。借鉴人类视觉系统的特点,即,为了理解某个场景,并不是一下子处理整个场景,而是Focus到某些关键的位置上,然后联合起来构建出整个场景信息。故本篇论文利用RNN处理图像序列,并使用「强化学习」来训练模型,使得模型能够学习attention决策。即,针对实时的场景,基于过去的信息和任务的需要选择下一个要focus的感知区域。这个和人类的感知方式比较相似,也是我们最早理解的Attention机制。
但是,上文所述的广泛应用于Seq2Seq中的Attention不大一样。人类的注意力机制实际上是可以节省计算资源的,注意只需要集中到某些区域,可以忽略大部分区域。Recurrent Models of Visual Attention中的做法和这个是一样的。
然而,下文即将要介绍的应用于Seq2Seq模型模型的Attention就不是这样的了。实际上,下文所述Attention模型,需要把每一个部分都观察的仔仔细细(每部分权重都要算一下),才能进一步决策到底需要focus到哪些部分,这和人类的视觉系统不相符,更像是memory,而不是attention(实际上attention可以理解为一种「短期记忆」,即根据短期记忆在输入特征上分配attention;memory也是另外一种非常重要的机制),然而,这并不妨碍注意力机制的有效性。
Global & Local Attention
EMNLP2015: Effective Approaches to Attention-based Neural Machine Translation[3]
以往的文章,主要将attention应用于不同场景中,而这篇文章提出了新的attention架构,引入了Global Attention和Local Attention的概念。
Global Attention和上文的Soft Attention几乎一样,即计算上下文向量时,和所有的encoder隐状态向量求alignment;而Local Attention是Soft Attention和Hard Attention的权衡,既拥有Soft Attention可微分,容易使用反向传播来优化的优点,又拥有Hard Attention复杂度低的优点,除此之外,还不需要强化学习方法进行训练。
首先定义,
Encoder得到的源语句单词 的隐状态为:; Decoder中目标语句单词 的隐状态为:; 对每一个目标单词 ,使用Attention机制计算的上下文向量为 ; Attention机制中的对齐模型为 (前面文章中都是使用 , 即「前一个时间步」的Decoder隐状态和Encoder隐状态来计算对齐权重)。
首先是Global Attention,如下图所示: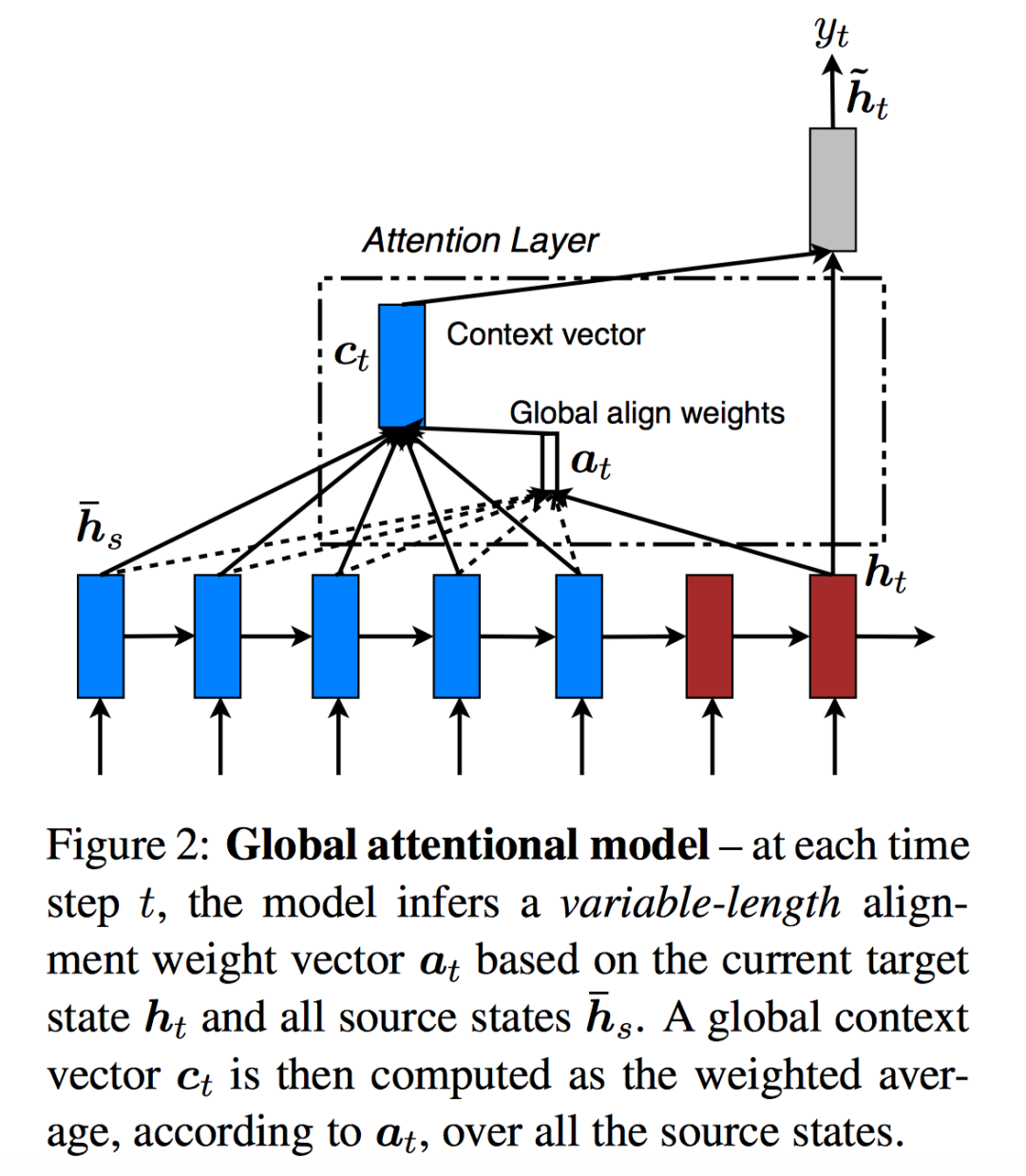
Global Attention中上下文向量 的计算路径为:。
对齐模型计算:
是源语句单词的位置。
具体可以采用:
上下文向量计算:
注意图中,框起来的部分作者称为Attention Layer。
接着是Local Attention,如下图所示: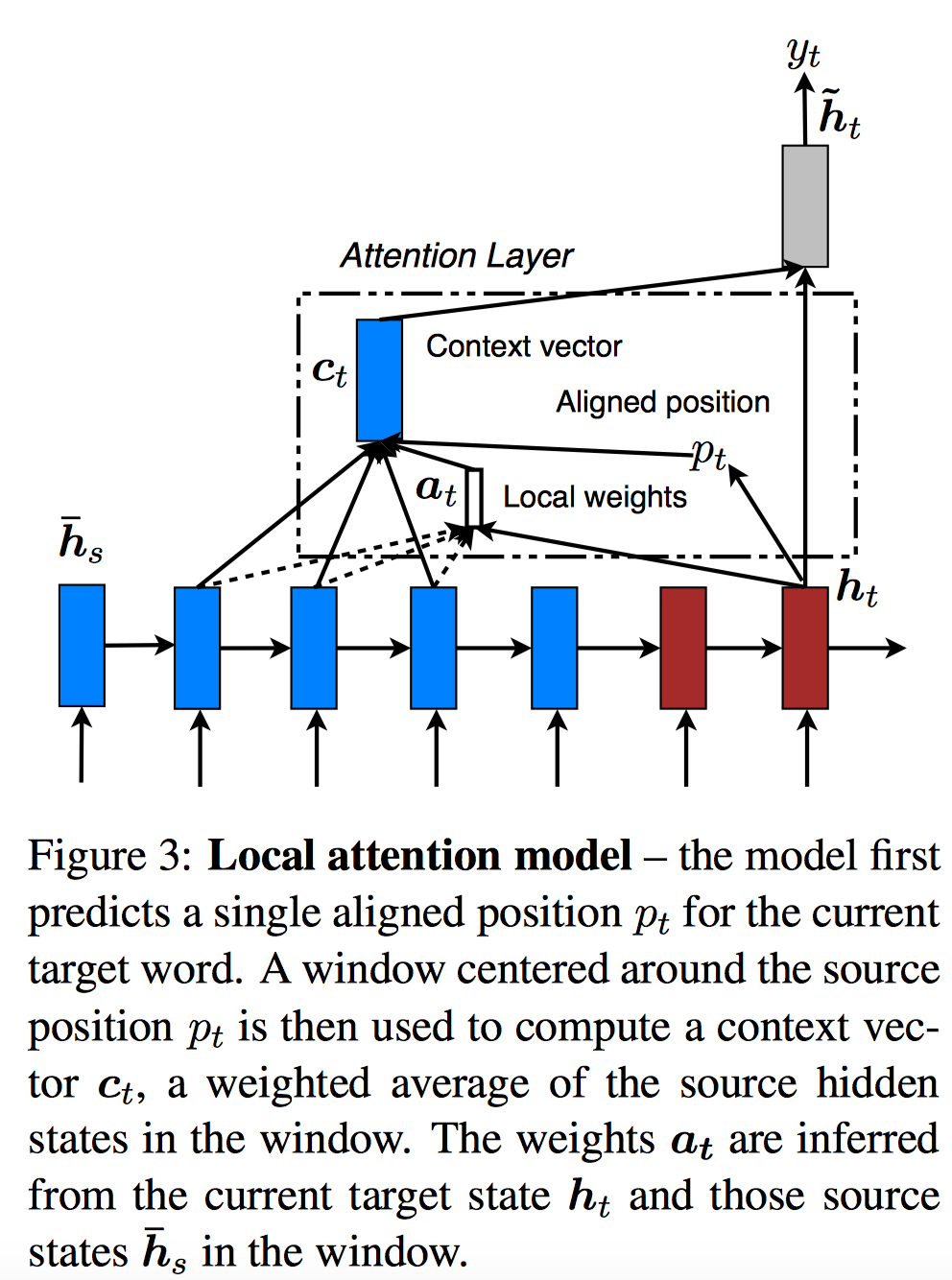
Local Attention的引入是为了解决Global Attention中Attend到源语句中所有的词,一方面复杂度高,另一方面很难翻译长序列语句。Local Attention首先根据目标词的隐状态 计算源语句中的「对齐位置」(中心),然后使用以该位置为中心的窗口 内的源语句单词 ,来计算Attention的权重,计算时使用以 为中心的高斯核函数进行衰减。具体如下:
「对齐位置模型」:, , 是源语句长度。只与t时刻Decoder状态 有关。 对齐权重模型:, 也就是在global Attention对齐模型基础上加了高斯函数指数衰减。。
计算上下文向量时,同上文,即对窗口内的encoder隐向量进行加权,即 。
计算得到上下文向量后,本文直接将 和 concat在一起,并计算经过attention后的隐状态 :
再将上述attention后的隐状态输入到一个softmax全连接层,得到预测目标值:
按照上述方式来看,每个目标输出单词的预测值,没有利用已经预测的输出单词(embedding)作为输入,也没有利用目标词位置前一时刻的decoder隐状态 ;只利用了当前时刻Decoder隐状态 (上下文向量计算中的权重也主要依据这个计算的)。也就是说,每个目标词位置的attention决策是独立的(只和 本身相关)。
然而在机器翻译当中,通常要维护一个覆盖集,即源语句中哪些单词被翻译过了;同理,在神经机器翻译中,我们在翻译一个目标词时,同样需要关注哪些源语句单词已经被翻译了。因此,作者提出了一个Input-feeding approach,把Decoder端前一时刻attention「后」的隐状态和前一时刻预测的输出单词的embedding连接起来,作为下一时刻的输入。(这个和传统Attention的几乎没差别)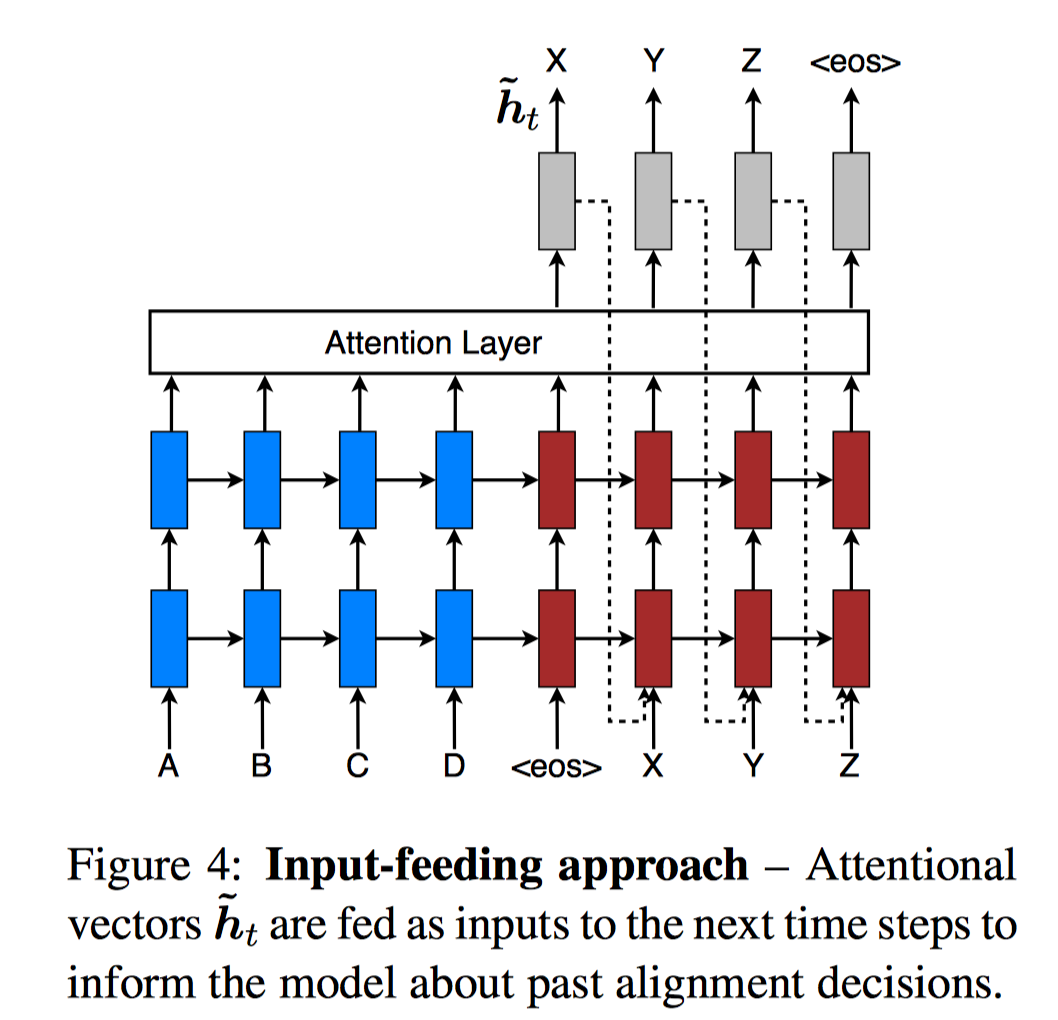
本文的贡献主要是Local Attention以及提出的各种各样的Alignment函数,其余都和前面的工作大同小异。现总结下Alignment函数如下图所示: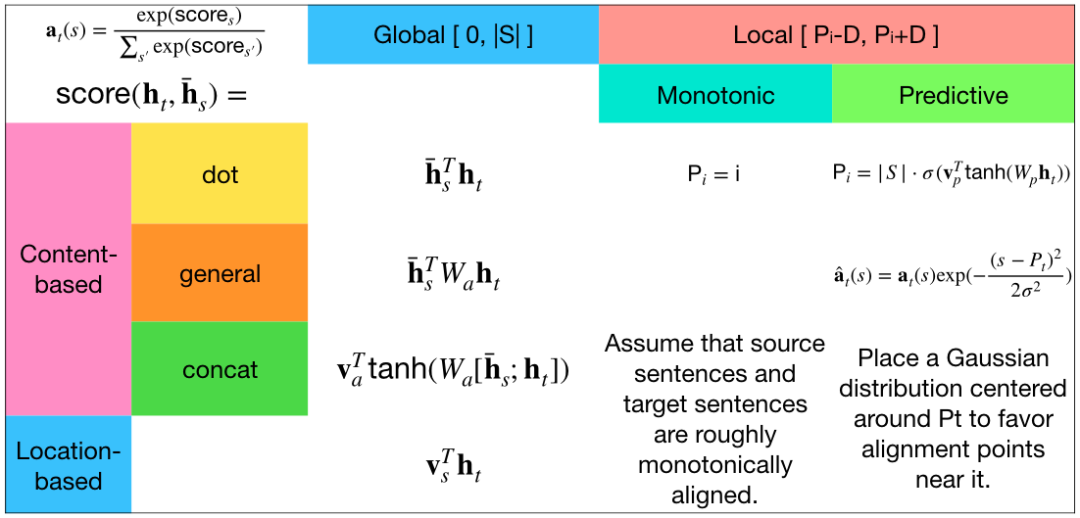
Multi-dimensional Attention
AAAI2018:DiSAN: Directional Self-Attention Network for RNN/CNN-Free Language Understanding[4]
在Baisc Attention中,对于每个查询,每个key对应的value都有一个权重值,即每个查询会对应一个1-D的Attention weight向量。而Multi-dimensional Attention会产生更高维度的Attention矩阵,旨在捕获不同特征空间中的Attention特征。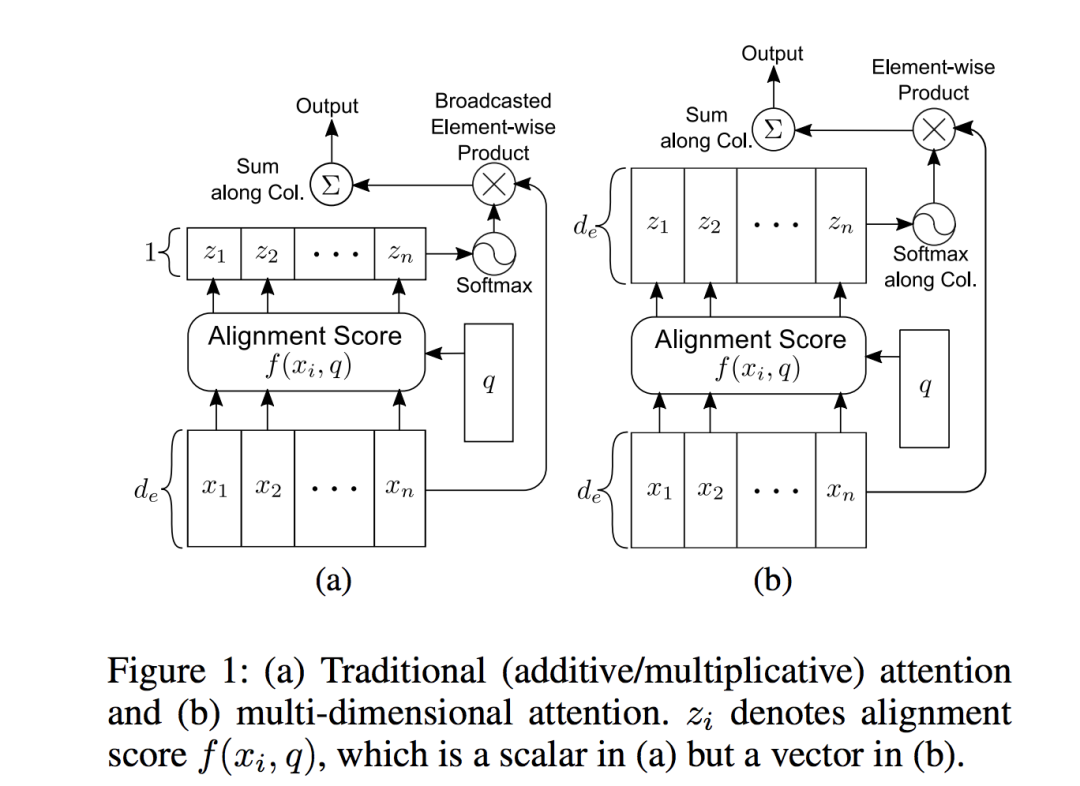
实际上主要区别在于,之前每个value向量对应一个权重Alignment Score,加权的时候实际上是利用了广播机制,value每个元素feature都乘上该权重;现在修改为在feature-level,每个元素特征都乘上不同的权重系数,因此Alignment Score是和Value同维度数的向量,即右图中的 。做法很简单,使用MLP对齐的时候,MLP输出层神经元数量等于Value维度数即可,例如这篇文章中使用
其他方式如下:()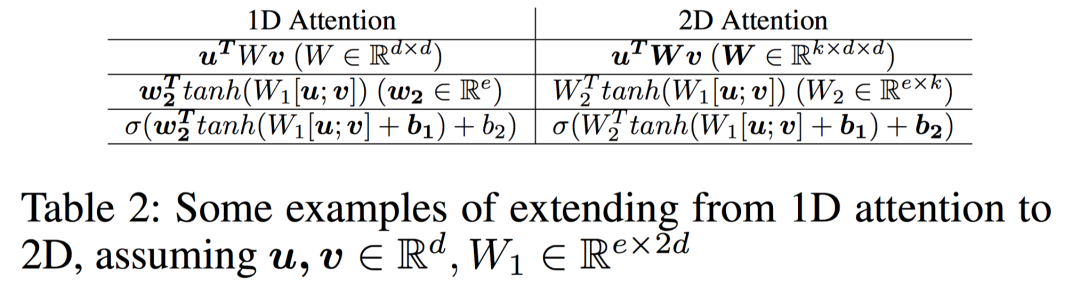
Multi-Source Attention
NAACL-HLT2016:Multi-Source Neural Translation[5]
这是2016发表在NAACL-HLT的一篇文章。文章使用英语,德语,法语三种语言建立了一种多源(三语言)机器翻译模型。Intuition在于,如果一篇文章被翻译成了另一种语言,那么就更加倾向于被翻译成其他语言。这样的观点对机器翻译任务有一定的启发,将原本的单一源语言替换为多种源语言,应该可以取得更好的效果。
如英语中的“bank”一词原本可以翻译为河岸或是银行,如果源语言中有德语词汇“Flussufer”(河岸)作为帮助,则自然可以精确得到法语中“Berge”(河岸)这样的翻译结果。基于这样的思想,作者在原有的seq2seq+attention模型的基础上做了修改,引入更多源语句,建立一种多源的翻译模型。模型结构如下:
左侧是两种不同语言的源语句,每种语言的源语句都有一个自己的encoder,且结构一样。问题的关键在于如何将两种语言encoder的东西combine在一起,并和decoder的表示进行对齐求attention。
由于作者采用了LSTM,因此同时考虑了hidden state和cell state的combination。核心工作就是图中黑色部分的combiners。combiners的输入是两个源语句最后时刻encoder得到的hidden state 和cell state ,输出是单个hidden state 和单个cell state 。(以往的工作似乎没有把encoder的cell state给decoder,从图中还可以看出,两个encoder中,每一层得到的两个源语句的hidden state和cell state都需要经过combiners)
最基本的combiner:对于hideen state,就是把两个encoder的隐状态concat起来,再做一个线性变换+tanh激活:。对于cell state,直接相加: 。
LSTM variant combiner:
唯一要提的就是, 作为输入,每个encoder得到的cell state各自对应一个自己的遗忘门。
到目前为止,都不涉及到attention。上文得到的 和 只是作为decoder的初始输入(前一时刻的输入,以前的Seq2Seq模型,似乎cell state没有传给decoder)。
至于attention,作者做了很小的改动。采用的是EMNLP2015: Effective Approaches to Attention-based Neural Machine Translation[6]中的Local Attention。
在这个基础上,让decoder的隐状态同时和两个encoder得到的隐状态进行对齐,并各自计算得到一个上下文向量,,注意这个c是上下文向量,跟上文所述cell state无关。最后计算Decoder的Attentional Hidden State时,使用 。也就是之前只使用1个上下文向量,这里面使用两个上下文向量。
下面是实验的一个case: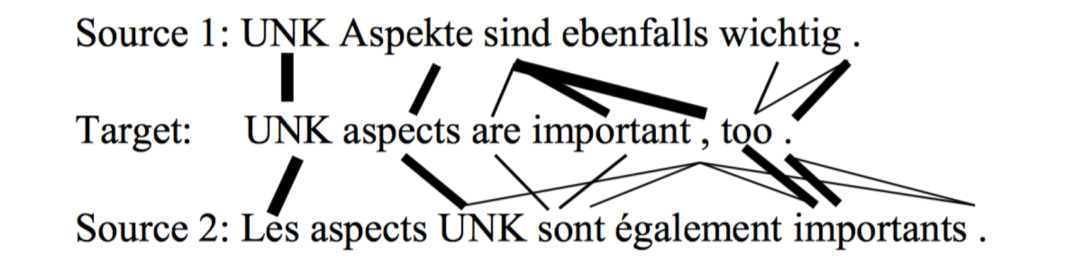
Hierarchical Attention
NAACL-HLT2016:Hierarchical Attention Networks for Document Classification[7]
文本分类是一项基础的NLP任务,在主题分类,情感分析,垃圾邮件检测等应用上有广泛地应用。其目标是给「每篇」文本分配一个类别标签。本文中模型的直觉是,不同的词和句子对文本信息的表达有不同的影响,词和句子的重要性是严重依赖于上下文的,即使是相同的词和句子,在不同的上下文中重要性也不一样。就像人在阅读一篇文本时,对文本不同的内容是有着不同的注意度的。而本文在attention机制的基础上,联想到文本是一个层次化的结构,提出用词向量来表示句子向量,再由句子向量表示文档向量,并且在词层次和句子层次分别引入attention操作的模型。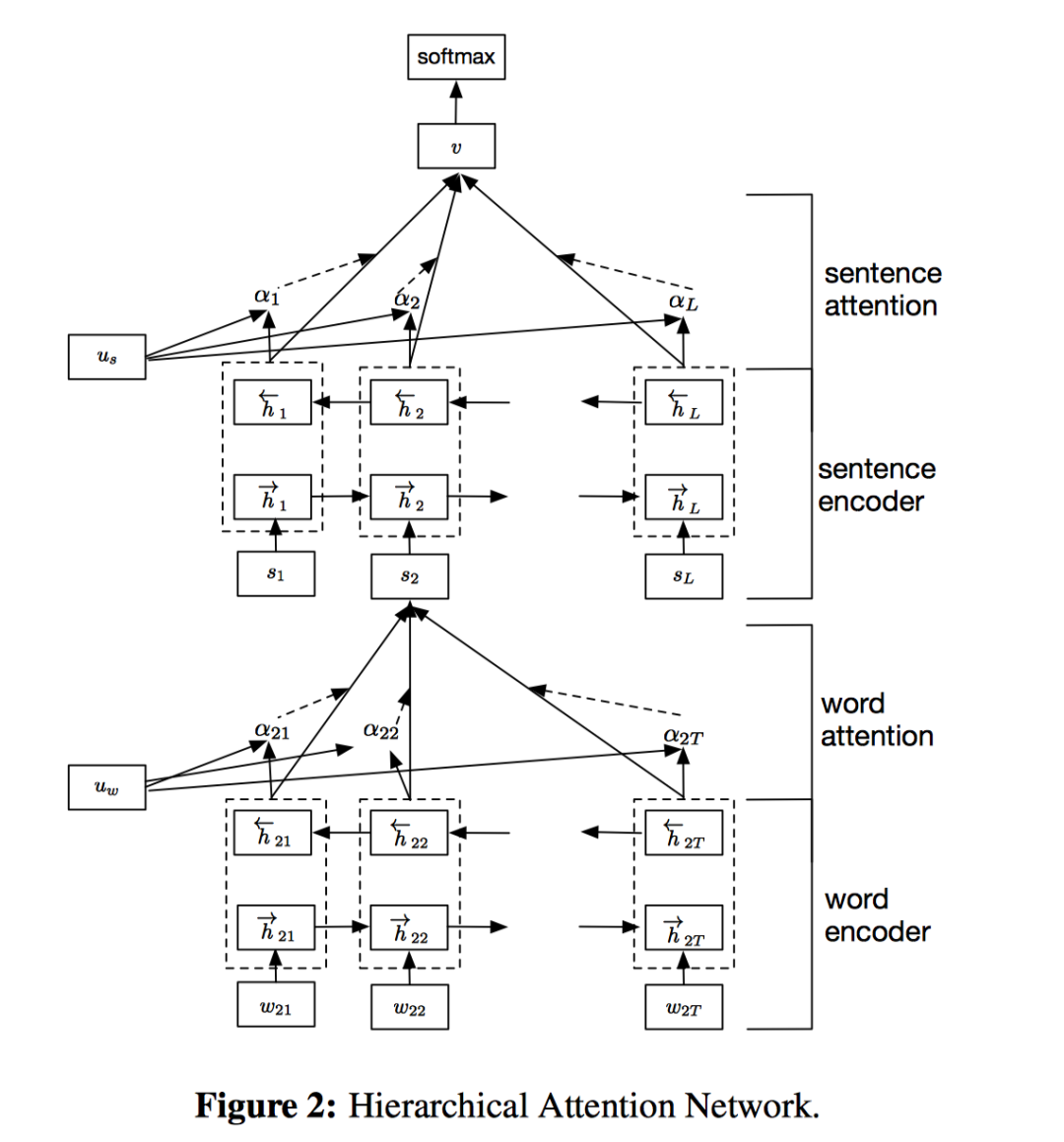
模型结构如上图所示,
词先经过Bidirectional RNN(GRU)提取到word annotation,然后经过1个MLP得到word annotation对应的隐表示(这一步在Basic Attention中没有), 然后使用该隐表示和全局的「word-level上下文隐向量」 进行对齐,计算相似性,得到softmax后的attention权重, 最后对句子内的词的word annotation根据attention权重加权,得到每个句子的向量表示。 接着,将得到的句子表示同样经过Bidirectional RNN(GRU)提取sentence annotation,再经过MLP得到对应的隐表示,接着将其和全局的「sentence-level上下文隐向量」 进行对齐计算,得到句子的attention权重,最后加权sentence annotation得到文档级别的向量表示。得到文档表示后再接一个softmax全连接层用于分类。
这里最有趣的一点是,全局的「word-level上下文隐向量」 和全局的的「sentence-level上下文隐向量」,是随机初始化的,且也是通过模型进行学习的。这二者就像专家一样,是高级咨询顾问。为了得到句子的向量表示,我们询问 哪些词含有比较重要的信息?为了得到文档的向量表示,我们询问 哪些句子含有比较重要的信息?
Attention over Attention
ACL2017:Attention-over-Attention Neural Networks for Reading Comprehension[8]
比较巧妙,但很容易理解,直接上图: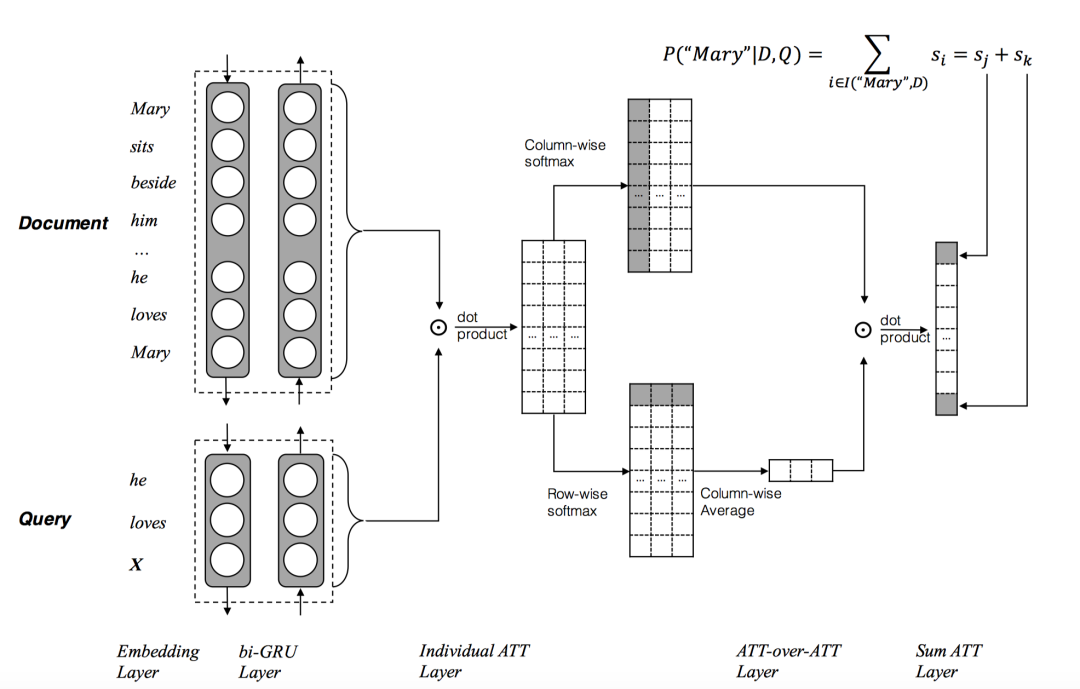
两个输入,一个Document和一个Query,分别用一个双向的RNN进行特征抽取,得到各自的隐状态 和 。(Embedding Layer+Bi-GRU Layer)。接着要计算document和query之间「每个词」的相似性得分,
然后基于query和doc的隐状态进行dot product,得到doc和query的attention关联矩阵 (Document所有词和Query所有词和之间的关联矩阵,行是Document,列是Query)。然后按列(column)方向进行softmax操作,得到query-to-document的attention值 ,表示t时刻的query 「word」的document-level attention。按照行(row)方向进行softmax操作,得到document-to-query的attention值 ,表示t时刻的document 「word」的query-level attention,再对 按照列方向进行累加求平均得到averaged query-level attention值 ,(可以证明,按列对 平均后仍然是概率分布),这个求平均的操作可以理解为求query-level每个词和document所有词的平均关联性。
最后再基于上一步attention操作得到 和 ,再进行attention操作,即attention over attention得到最终的attended attention ,即Document每个词都有一个attended attention score。
预测的时候,预测词典中每个词的概率,将词w在document中出现的位置上对应的attention值进行求和。例如图中Mary出现在Document首尾,故把这两个attention score相加,作为预测的概率。
文章的亮点在于,引入document和query所有词pair-wise的关联矩阵,分别计算query每个词document-level attention(传统的方法都只利用了这个attention),和document每个词的query-level attention,对后者按列取平均得到的averaged query-level attention。进一步,二者点乘得到attended document-level attention,也即attention-over-attention。
这个和上文层次化Attention有点像。
ok,今天就到这儿啦,敬请期待下一篇~我是蘑菇先生,欢迎大家到我的公众号『蘑菇先生学习记』一起交流!
一个小通知
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的文章,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
1. 点击页面最上方"NewBeeNLP",进入公众号主页。
2. 点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢每一份支持,比心

本文参考资料
NIPS2014: Recurrent Models of Visual Attention: https://papers.nips.cc/paper/5542-recurrent-models-of-visual-attention.pdf
[2]ICLR2015: Multiple Object Recognition with Visual Attention : https://arxiv.org/abs/1412.7755
[3]EMNLP2015: Effective Approaches to Attention-based Neural Machine Translation: http://aclweb.org/anthology/D15-1166
[4]AAAI2018:DiSAN: Directional Self-Attention Network for RNN/CNN-Free Language Understanding: https://arxiv.org/pdf/1709.04696.pdf
[5]NAACL-HLT2016:Multi-Source Neural Translation: http://www.aclweb.org/anthology/N16-1004
[6]EMNLP2015: Effective Approaches to Attention-based Neural Machine Translation: http://aclweb.org/anthology/D15-1166
[7]NAACL-HLT2016:Hierarchical Attention Networks for Document Classification: http://www.aclweb.org/anthology/N16-1174
[8]ACL2017:Attention-over-Attention Neural Networks for Reading Comprehension: https://arxiv.org/pdf/1607.04423.pdf
- END -

往期精彩回顾
获取本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/qFiUFMV
本站qq群704220115。
加入微信群请扫码: