
21个深度学习开源数据集汇总!
↓↓↓点击关注,回复资料,10个G的惊喜
转自丨极市平台
导读
本文收集整理了21个国内外经典的开源数据,包含了目标检测、图像分割、图像分类、人脸、自动驾驶、姿态估计、目标跟踪等方向。
深度学习的三大要素:数据、算法、算力。
数据在深度学习中占据着非常重要的地位,一个高质量的数据集往往能够提高模型训练的质量和预测的准确率。极市平台收集整理了21个国内外经典的开源数据,包含了目标检测、图像分割、图像分类、人脸、自动驾驶、姿态估计、目标跟踪等方向。
数据集下载汇总链接:https://www.cvmart.net/dataSets
数据集将会不断更新,欢迎大家持续关注!
一、目标检测
1.COCO2017数据集
COCO2017是2017年发布的COCO数据集的一个版本,主要用于COCO在2017年后持有的物体检测任务、关键点检测任务和全景分割任务。
二、图像分割
1.LVIS数据集
LVIS是一个大规模细粒度词汇集标记数据集,该数据集针对超过 1000 类物体进行了约 200 万个高质量的实例分割标注,包含 164k 张图像。
2.高密度人群及移动物体视频数据集
Crowd Segmentation Dataset 是一个高密度人群和移动物体视频数据,视频来自BBC Motion Gallery 和 Getty Images 网站。
3.DAVIS 视频分割数据集
Densely Annotated Video Segmentation 是一个高清视频中的物体分割数据集,包括 50个 视频序列,3455个 帧标注,视频采集自高清 1080p 格式。
三、图像分类
1.MNIST 手写数字图像数据集
MNIST数据集是一个手写阿拉伯数字图像识别数据集,图片分辨率为 20x20 灰度图图片,包含‘0 - 9’ 十组手写手写阿拉伯数字的图片。其中,训练样本 60000 ,测试样本 10000,数据为图片的像素点值,作者已经对数据集进行了压缩。
2.Kaggle 垃圾分类图片数据集
该数据集是图片数据,分为训练集85%(Train)和测试集15%(Test)。其中O代表Organic(有机垃圾),R代表Recycle(可回收)
四、人脸
1.IMDB-WIKI人脸数据集
IMDB-WIKI 500k+ 是一个包含名人人脸图像、年龄、性别的数据集,图像和年龄、性别信息从 IMDB 和 WiKi 网站抓取,总计 524230 张名人人脸图像及对应的年龄和性别。其中,获取自 IMDB 的 460723 张,获取自 WiKi 的 62328 张。
2.WiderFace人脸检测数据集
WIDER FACE数据集是人脸检测的一个benchmark数据集,包含32203图像,以及393,703个标注人脸,其中,158,989个标注人脸位于训练集,39,,496个位于验证集。每一个子集都包含3个级别的检测难度:Easy,Medium,Hard。这些人脸在尺度,姿态,光照、表情、遮挡方面都有很大的变化范围。WIDER FACE选择的图像主要来源于公开数据集WIDER。制作者来自于香港中文大学,他们选择了WIDER的61个事件类别,对于每个类别,随机选择40%10%50%作为训练、验证、测试集。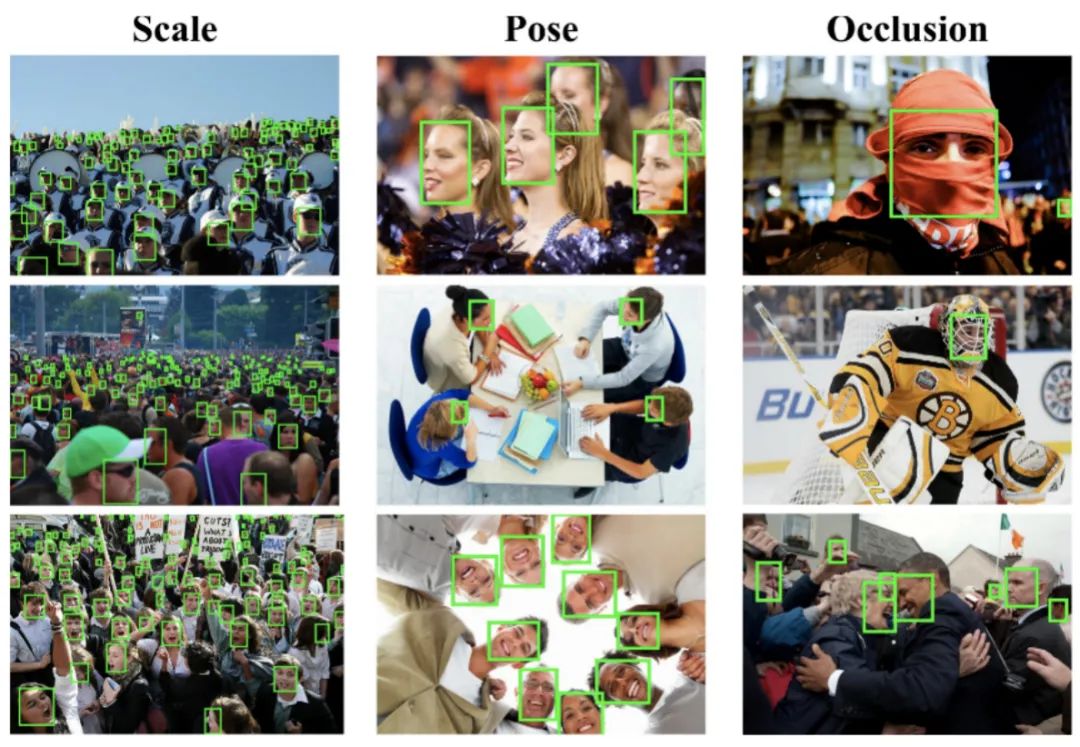
3.LFW 人像图像数据集
该数据集是用于研究无约束面部识别问题的面部照片数据库。数据集包含从网络收集的13000多张图像。每张脸都贴上了所画的人的名字,图片中的1680人在数据集中有两个或更多不同的照片。
GENKI数据集是由加利福尼亚大学的机器概念实验室收集。该数据集包含GENKI-R2009a,GENKI-4K,GENKI-SZSL三个部分。GENKI-R2009a包含11159个图像,GENKI-4K包含4000个图像,分为“笑”和“不笑”两种,每个图片的人脸的尺度大小,姿势,光照变化,头的转动等都不一样,专门用于做笑脸识别。GENKI-SZSL包含3500个图像,这些图像包括广泛的背景,光照条件,地理位置,个人身份和种族等。
五、姿态估计
1.MPII人体模型数据集
MPII Human Shape 人体模型数据是一系列人体轮廓和形状的3D模型及工具。模型是从平面扫描数据库 CAESAR 学习得到。
2.MPII人类姿态数据集
MPII 人体姿态数据集是用于评估人体关节姿势估计的最先进基准。该数据集包括大约 25,000 张图像,其中包含超过 40,000 个带有注释身体关节的人。这些图像是使用已建立的人类日常活动分类法系统收集的。总的来说,数据集涵盖了 410 项人类活动,每个图像都提供了一个活动标签。每张图像都是从 YouTube 视频中提取的,并提供前后未注释的帧。此外,测试集有更丰富的注释,包括身体部位遮挡和 3D 躯干和头部方向。
六、自动驾驶
1.KITTI 道路数据集
道路和车道估计基准包括289次培训和290幅测试图像。我们在鸟瞰空间中评估道路和车道的估计性能。它包含不同类别的道路场景:城市无标记、城市标记、 城市多条标记车道以及以上三者的结合。
2.CrackForest数据集
CrackForest数据集是一个带注释的道路裂缝图像数据库,可以大致反映城市路面状况。
3.KITTI-2015立体声数据集
stero 2015 基准测试包含 200 个训练场景和 200 个测试场景(每个场景 4 幅彩色图像,以无损 png 格式保存)。与stereo 2012 和flow 2012 基准测试相比,它包含动态场景,在半自动过程中为其建立了真值。该数据集是通过在卡尔斯鲁厄中等规模城市、农村地区和高速公路上行驶而捕获的。每张图像最多可以看到 15 辆汽车和 30 名行人。
4.KITTI-2015光流数据集
Flow 2015 基准测试包含 200 个训练场景和 200 个测试场景(每个场景 4 幅彩色图像,以无损 png 格式保存)。与stereo 2012 和flow 2012 基准测试相比,它包含动态场景,在半自动过程中为其建立了真值。该数据集是通过在卡尔斯鲁厄中等规模城市、农村地区和高速公路上行驶而捕获的。每张图像最多可以看到 15 辆汽车和 30 名行人。
5.KITTI-2015场景流数据集
Sceneflow 2015 基准测试包含 200 个训练场景和 200 个测试场景(每个场景 4 幅彩色图像,以无损 png 格式保存)。与stereo 2012 和flow 2012 基准测试相比,它包含动态场景,在半自动过程中为其建立了真值。该数据集是通过在卡尔斯鲁厄中等规模城市、农村地区和高速公路上行驶而捕获的。每张图像最多可以看到 15 辆汽车和 30 名行人。
6.KITTI深度数据集
KITTI-depth 包含超过 93,000 个深度图以及相应的原始 LiDaR 扫描和 RGB 图像。鉴于大量的训练数据,该数据集应允许训练复杂的深度学习模型,以完成深度补全和单幅图像深度预测的任务。此外,该数据集提供了带有未发布深度图的手动选择图像,作为这两个具有挑战性的任务的基准。
七、目标跟踪
1.ALOV300++跟踪数据集
ALOV++,Amsterdam Library of Ordinary Videos for tracking 是一个物体追踪视频数据,旨在对不同的光线、通透度、泛着条件、背景杂乱程度、焦距下的相似物体的追踪。
八、动作识别
1.HMDB人类动作视频数据集
由布朗大学发布的人类动作视频数据集,该数据集视频多数来源于电影,还有一部分来自公共数据库以及YouTube等网络视频库。数据库包含有6849段样本,分为51类,每类至少包含有101段样本。
2.UCF50动作识别数据集
UCF50 是一个由中佛罗里达大学发布的动作识别数据集,由来自 youtube 的真实视频组成,包含 50 个动作类别,如棒球投球、篮球投篮、卧推、骑自行车、骑自行车、台球、蛙泳、挺举、跳水、击鼓等。对于所有 50 个类别,视频分为 25 组,其中每组由超过 4 个动作剪辑。同一组中的视频片段可能具有一些共同的特征,例如同一个人、相似背景、相似视点等。
3.SBU Kinect 交互数据集
SBU Kinect Interaction是一个复杂的人类活动数据集,描述了两个人的交互,包括同步视频、深度和运动捕捉数据。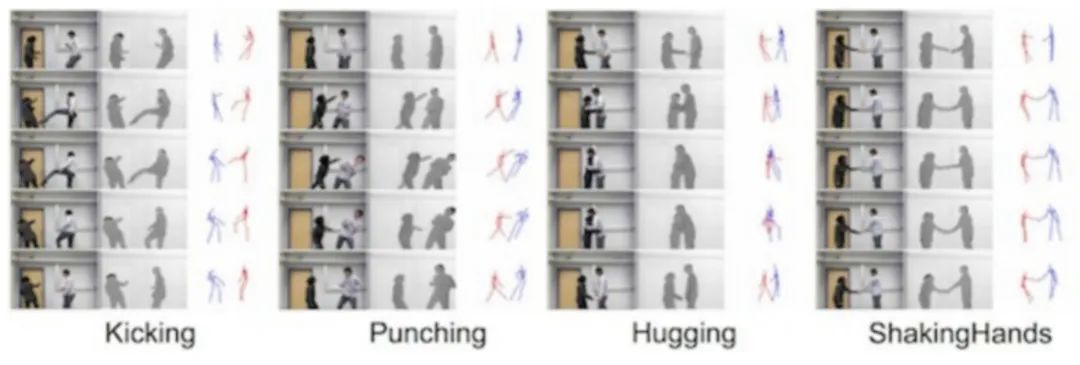
推荐阅读
决策树可视化,被惊艳到了! 开发机器学习APP,太简单了 200 道经典机器学习面试题总结 卷积神经网络(CNN)数学原理解析 收手吧,华强!我用机器学习帮你挑西瓜 为了这个GIF,我专门建了一个网站 【保姆级教程】白嫖老外的云服务器
三连在看,月入百万👇