
如何可视化你的CV模型?
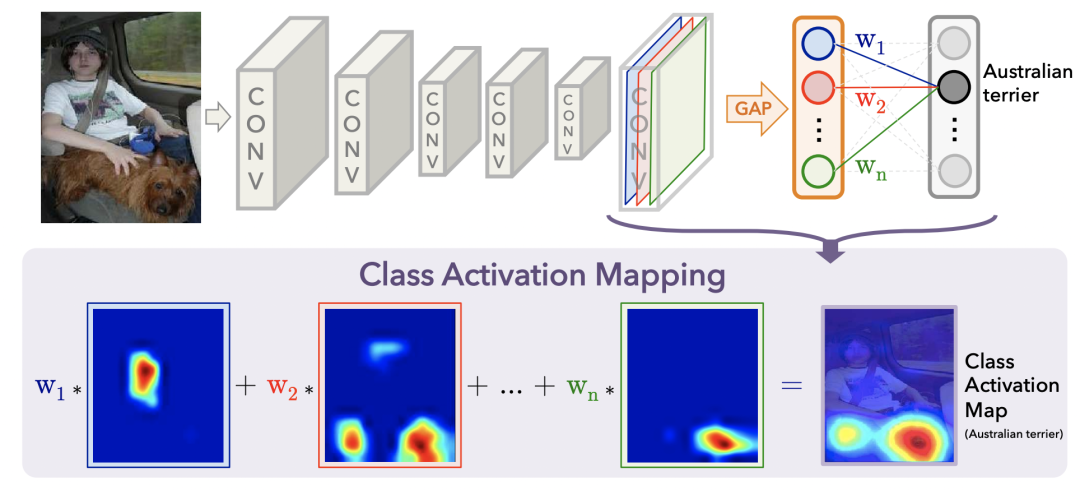
首先,获取模型最后一层卷积输出的特征图[W, H, C],其中C是channel维度,也就是特征图的个数,每个特征图是W*H的矩阵。利用Global Average Pooling(GAP)将每一个channel的特征图融合。
然后,利用全连接+softmax根据各个channel的特征图学习分类任务,这样就能通过softmax得到每个channel的权重。对于一个多分类任务,选择正确类别相对于各个channel的softmax打分,作为每个特征图的权重w。
最后,利用学到的权重w对各个channel的特征图加权平均,得到最终的可视化结果,即图像上每个位置的重要性。整个过程如下图所示。

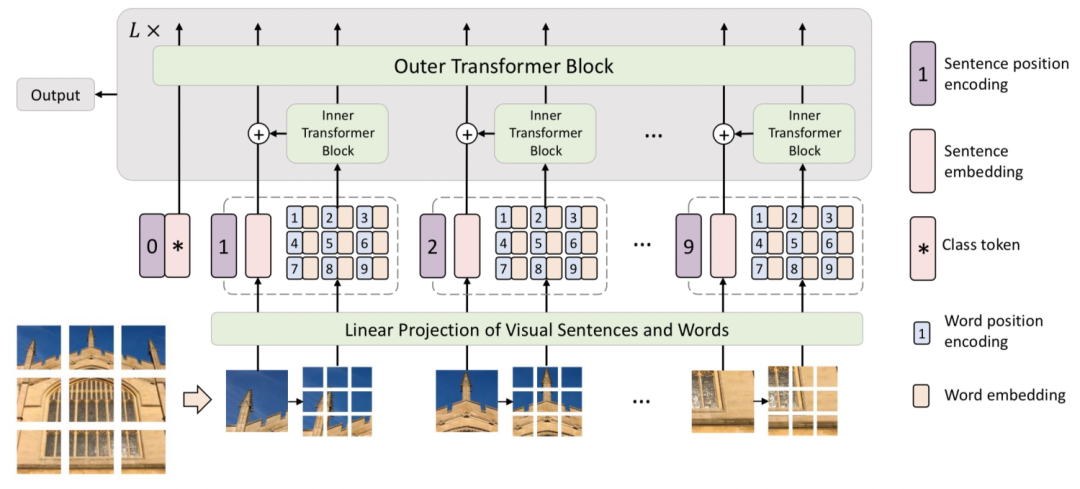

第一步——融合多head结果:需要先获取到ViT每层的[CLS] token对于各个patch的attention打分。一般ViT使用的都是多头注意力机制,这里我们把各个head的attention score求平均作为每层的整体attention。
第二步——考虑残差连接:由于Transformer中,每层之间都有residual connection,直接将上一层的输入和本层的输出加和。这对应于每个位置的token和自己做了一个权重为1的attention。为了把这部分信息体现出来,通过生成一个对角线为1的矩阵,加和到初始的attention score矩阵上,再进行归一化,得到考虑了残差连接的attention打分。
第三步——考虑多层累乘关系,当我们想绘制多层attention矩阵时,各层attention矩阵是有一个传导关系的。第二层Transformer在做attention时,输入是第一层attention加权的结果。为了把这个因素考虑在内,代码中会循环进行attention weight相乘。用上一层累乘的attention矩阵,与当前层直接从模型中获取的attention矩阵相乘,模拟了输入是上一层attention加权融合后的结果。
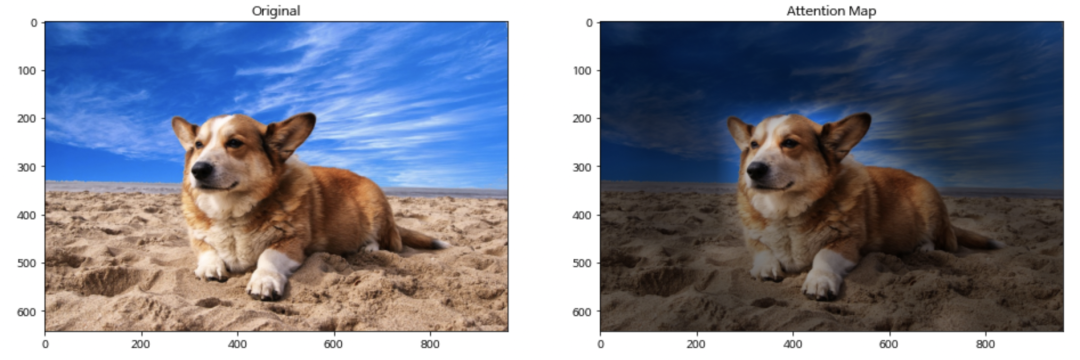
第四步——插值还原:我们得到的attention map是pacth_size * patch_size的,和原来图像的尺寸肯定是不一样的。我们需要把这个attention矩阵通过插值的方法还原成和图像相同的尺寸,再用这个attention score和图像上对应像素点相乘,得到可视化图像。代码中直接使用了cv2的resize函数,这个函数通过双线性插值的方法将输入矩阵扩大成和原图像相同的尺寸。


交流群
欢迎加入公众号读者群一起和同行交流,目前有美颜、三维视觉、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
