
最新综述:基于深度学习方式的单目物体姿态估计与跟踪
↑ 点击蓝字 关注极市平台

作者丨Tom Hardy
来源丨3D视觉工坊
编辑丨极市平台
极市导读
本文对深度学习技术路线中目标姿态检测与跟踪的最新进展进行了综述,包括实例级单目目标姿态检测、类别级单目目标姿态检测和单目目标姿态跟踪三类主要任务。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
原文:Deep Learning on Monocular Object Pose Detection and Tracking: A Comprehensive Overview
作者:中国人民大学、清华大学、北京交通大学
摘要
目标姿态检测与跟踪在自动驾驶、机器人技术、增强现实等领域有着广泛的应用,近年来受到越来越多的关注。在目标姿态检测和跟踪的方法中,深度学习是最有前途的一种,其性能优于其他方法。然而,对于基于深度学习方法的最新发展却缺乏调查研究。因此,本文对深度学习技术路线中目标姿态检测与跟踪的最新进展进行了综述。为了更深入的介绍,本文的研究范围仅限于以单目RGB/RGBD数据为输入的方法,包括实例级单目目标姿态检测、类别级单目目标姿态检测和单目目标姿态跟踪三类主要任务。论文详细介绍了检测和跟踪的度量、数据集和方法。文中还介绍了几种公开数据集上的最新方法的比较结果,以及有见地的观察结果和启发性的未来研究方向。
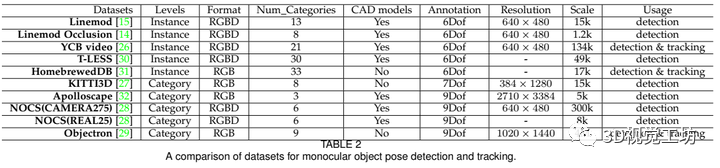
数据集介绍
实例级单目目标姿态估计与跟踪数据集:主要包括经典的Linemod、YCB等数据集~
类别级单目目标姿态估计与跟踪数据集:主要包括KITTI3D、Apolloscape等开源数据集~
实例级单目目标姿态检测
实例级单目目标姿态检测的目的是检测目标并估计其相对于标准帧的6自由度姿态(旋转和平移),又可分为基于RGB数据和RGBD数据。
基于RGB数据的方法
对于六自由度姿态的估计,最直接的方法是让深度学习模型直接预测姿态相关参数。然而,从单个RGB图像直接估计6自由度姿态是一个不适定的问题,并面临挑战。由于CAD模型的存在,在输入图像和对象模型之间建立2D-3D的对应关系有助于简化任务。根据以上观察,我们提供了一个基于RGB的实例级单目物体姿态检测的整体示意图,如图4所示。

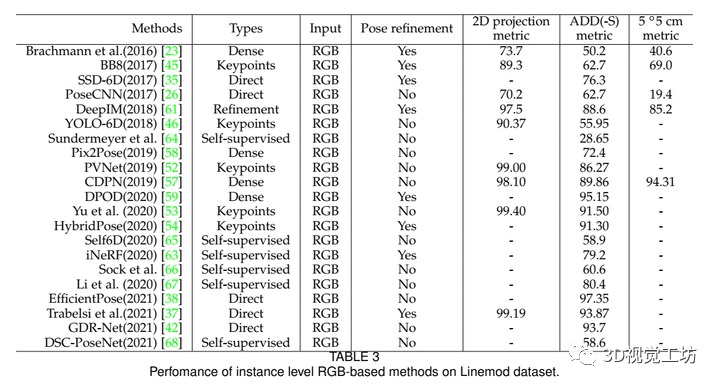
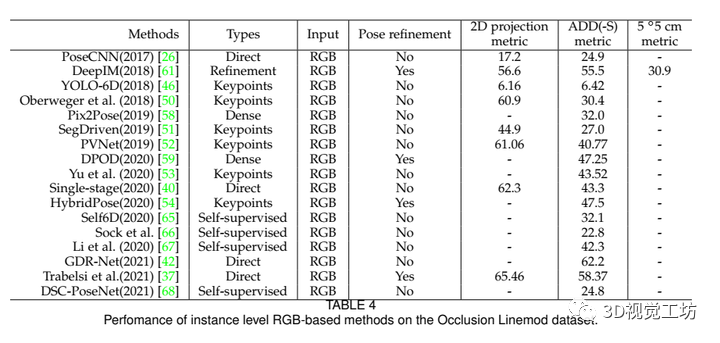
一般来说,我们将基于深度学习的方法分为五大类:直接方法、基于关键点的方法、基于密集坐标的方法、基于细化的方法和自监督方法,五类方法对应的最新算法以及对应性能如表3和表4所示:
基于RGBD数据方法
RGB图像缺乏深度信息,使得6自由度物体姿态检测任务成为一个病态问题。幸运的是,单目RGBD相机的发展推动了基于(RGB)D的6自由度姿态估计方法的发展(基于RGB的方法以RGBD图像或深度掩模为输入,充分利用点云表示的能力预测物体的姿态。一般来说,基于(RGB)D的方法可以分为基于检索的方法、基于关键点的方法和其他基于深度学习的方法。
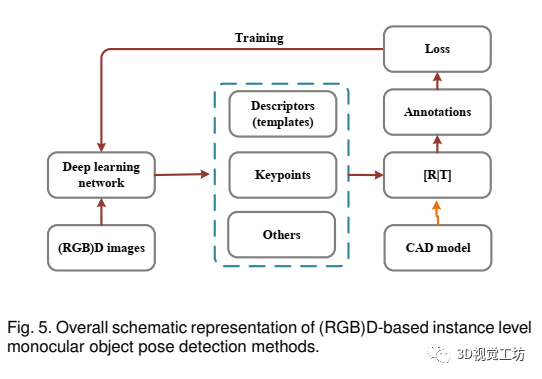
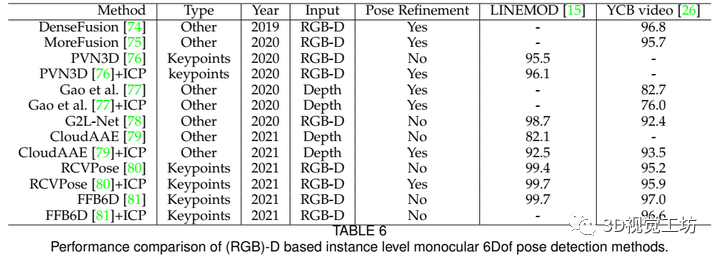
基于(RGB)D的实例级单目物体姿态检测方法的总体示意图如图5所示,算法分类如表6所示。
类别级单目目标姿态检测
根据预测的重点是1Dof旋转还是3Dof旋转,将相关方法分为类别级单目3D目标检测和类别级单目6D姿态检测。
1、Category Level Monocular 3D Object Detection
类别级单目三维目标检测需要预测7个自由度(7Dof)的姿态配置,包括旋转(1)(即只需要预测偏航)、平移(3)和目标尺寸(3),训练和测试期间没有可用的CAD模型。类别级单目三维目标检测对于自主驾驶场景具有重要意义。它更关注平移预测的精度,而旋转预测的精度可以相应放宽。激光雷达采集的点云和单目RGB图像是最常用的数据格式。
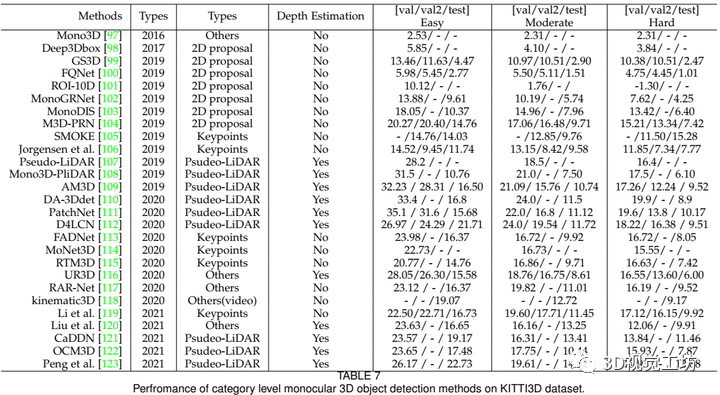
常用的方法包括2D proposal方式、Psudeo-LIDAR方式、Keypoints方式以及其它方式,如表7所示。
2、Category Level Monocular 6D Pose Detection
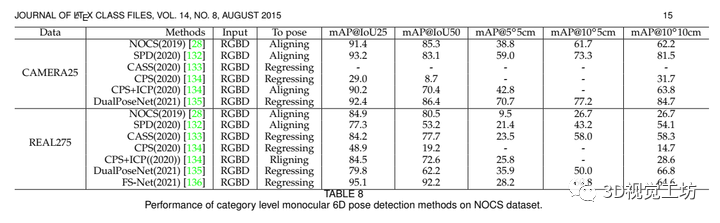
类别级6D姿态估计,9个维度,三个旋转,三个平移,三个尺寸。主要分为基于Aligning、Regressing、Rligning方式,如表8所示。
单目目标姿态跟踪
在本节中,我们将介绍单目物体姿态跟踪方法。根据CAD模型是否可用,将相关方法分为实例级单目目标姿态跟踪和类别级单目目标姿态跟踪。整体示意图如图8所示:
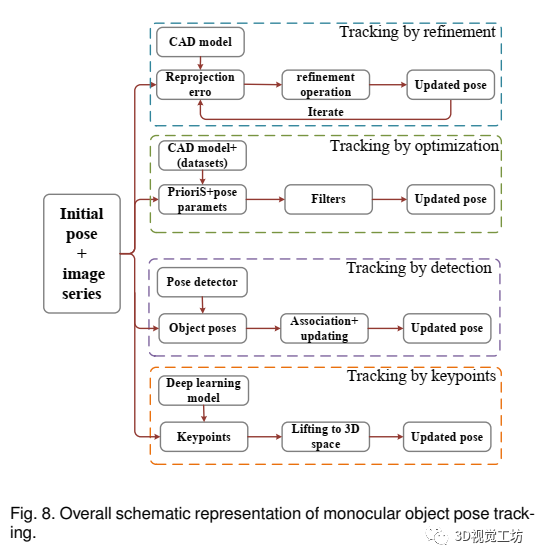
1、实例级单目目标姿态跟踪
主要包括Tracking by refinement.、Tracking by optimization方式,思路如图8所示。
2、类别级单目目标姿态跟踪
主要包括Tracking by detection、Tracking by keypoints,思路如图8所示。
聊一下单目姿态检测与跟踪方式的优缺点以及未来发展方向
1、实例级基于RGB方式的姿态检测
第一,虽然现有的算法在简单的室内场景中表现得足够好,但是它们仍然很难处理遮挡情况还有杂乱的背景。然而,在实际应用中,像遮挡这样的干扰是不可避免的。因此,研究如何处理遮挡等复杂干扰是一个很好的研究方向。
第二,现有的仅限RBG的方法非常容易受到光线变化和拍摄角度等因素的影响。这些因素会导致图像的模糊、反射、盲点、截止等,使得从图像中提取的特征变得模糊,特别是当这些特征用于检测关键点时。对于环境控制的室内场景(例如室内工厂),这可能不是什么大问题。然而,对于户外应用,如手机增强现实,由于光照条件的不可控性和不可预测性,这将成为其广泛应用的最大障碍。因此,设计对上述因素具有鲁棒性的算法也是今后的一个重要研究课题。
第三,已有研究表明,建立二维-三维物体姿态估计对应比直接预测姿态参数效果更好,主流工作长期致力于研究如何更好地建立对应。然而,这种方法不能以端到端的方式进行训练。此外,建立和求解对应关系非常耗时,因此,未来需要考虑设计可微的2D-3D对应关系求解算法,用神经网络代替,或者探索提高无对应方法性能的可能性。
2、实例级基于RGBD方式的姿态检测
尽管现有的方法总是比仅使用RGB的方法表现得更好,但是由于需要学习额外的深度信息,它们通常会消耗更多的计算资源。有些方法需要额外的细化步骤,比如ICP,以提高性能,这进一步增加了运行时间。因此,设计一个更轻量级的网络结构来降低时间复杂度和空间复杂度可能是一个有价值的未来研究课题。
大多数现有的低功耗硬件(如移动电话)只能捕获使用中的稀疏点云。虽然现有的(RGB)基于D的方法都是在深度图生成的密集点云数据集上进行评估的,但它们在稀疏点云上的性能尚不清楚。这造成了评估性能和实际使用之间的偏差。因此,有必要研究现有算法是否适合以稀疏点云作为输入。如果没有,就应该提出新的算法。
众所周知,标记物体的6自由度姿势非常困难。因此,我们面临的另一个重要挑战是如何获得精确的地面真相。由于现有先进的计算机图形学技术,具有地面真实感的合成数据非常容易获得,可以用来训练目标姿态检测模型。然而,在合成数据集上训练的模型在真实世界的图像上通常表现不佳。因此,这就提出了一个新的可能的未来研究问题:如何提高在综合数据集上训练的模型的泛化能力。现有的自监督学习方法已经提供了一些有前途的前期研究,但还需要付出更多的努力。值得注意的是,该研究方向同样适用于基于RGB的实例级方法和类别级方法。
3、类别级别3D目标检测
由于其主要应用是为自动驾驶提供环境信息,定位物体比预测物体的大小和方向更重要。
然而,利用单个RGB图像在三维空间中定位目标是不适定的,因此,如何使模型具有深度预测能力是至关重要的。由于该任务所使用的图像通常包含多个对象,并且包含广泛的特征丰富的背景,因此使用它们来推断深度信息可能是一种可行的解决方案。也就是说,如何利用instance aware关系来提高模型的深度感知能力,尤其是如何利用隐藏在图像中的非局部特征。将视觉transformer纳入网络架构可能是一个好主意。
利用伪激光雷达是一个可行的研究方向。然而,目前基于伪激光雷达的解决方案通常使用现成的深度预测模型预先预测深度。它造成了三维探测和深度预测之间的差距。也就是说,现有的深度估计模型存在次优问题,利用其生成的伪LiDAR点云进行三维探测将进一步加剧这一问题。因此,在未来的伪激光雷达研究中,在同一网络或同一训练过程中,将深度估计与三维探测相结合,以获得互为性能增益,避免不同次优问题积累的探测误差,具有重要的应用价值。
KITTI3D等现有数据集始终包含激光雷达捕获的点云和单目相机捕获的图像。尽管这一点在单目检测任务中,云数据在推理时是不允许使用的,研究如何更好地利用云数据进行训练具有重要意义单目三维物体探测器。例如,我们可以利用点云在训练时学习卷积权重,而在推理时丢弃它们。或者我们可以使用现成的点云三维探测器作为教师网络来训练单目三维探测器,就像在知识蒸馏中的那样。
4、类别级6D姿态估计
大多数方法都需要使用现成的二维目标检测模型来提前定位目标。然后在进行姿态预测之前,对目标图像进行裁剪和调整大小。这样的两阶段方案可能会导致定位误差的累积。因此,一个问题是,是否有可能在一个统一的网络中或通过完全无建议的方式生成对象建议和完成姿态估计。答案显然是肯定的,参考了无锚2D目标检测模型的成功经验。然而,到目前为止,还没有研究人员朝着这个方向努力。
尽管现有方法通常使用大型主干(如ResNet-101)来学习特性,以确保高精度和有效性,但它们同时降低了效率。再加上二维目标检测过程耗时,6D姿态检测体系结构很难保证其实时性。因此,轻量级实时执行模型是一个值得研究的课题。
大多数现有算法高度依赖于深度信息的利用。然而,众所周知,仅以RGB图像作为输入对于手机上的增强现实(augmentedreality)等应用非常重要。虽然已经提出了几种仅适用于RGB的方法,但是它们的性能都很差。因此,在仅RGB类别级单目6D位姿检测方面可以做更多的工作。
5、单目物体姿态跟踪
如果CAD模型可用,则在受控场景中解决此问题并不困难。在不可控场景(如自动驾驶场景、室外照明场景等)中,我们将面临实例级目标姿态检测任务所面临的所有问题。
我们发现,现有的目标姿态跟踪算法通常只以两帧图像(当前帧和前一帧)作为输入来预测当前帧的目标姿态。这可能导致三个主要问题:第一,顺序信息没有得到充分利用。其次,跟踪错误会随着时间的推移而累积,无法消除。第三,可能出现盒子漂移问题。为了解决这些问题,单目目标姿态跟踪引入了一个可行的研究方向,即利用LSTM等递归神经网络来关联多帧信息。它不仅可以提高特征的利用率,而且可以保证跟踪结果的稳定性。
许多现有的方法需要渲染CAD模型,这非常耗时,因为大多数现有的渲染器要么是不可微分的,要么是经济高效的。因此,设计高效的、可微的绘制算法是今后工作的重点。
此外,当CAD模型不可用时,大多数现有工程仅跟踪7自由度3D边界框。据我们所知,只有一项工作可以实现全9自由度类别级的姿态跟踪。如前所述,7自由度姿态足以满足位置感知场景(如自动驾驶)的要求,而对于旋转和尺寸软件场景(如增强现实)则不够。因此,跟踪全9自由度边界盒将是一个有意义的研究课题,应该引起更多的关注。
如果觉得有用,就请分享到朋友圈吧!
△点击卡片关注极市平台,获取最新CV干货
公众号后台回复“79”获取CVPR 2021:TransT 直播链接~
极市干货
YOLO教程:一文读懂YOLO V5 与 YOLO V4|大盘点|YOLO 系目标检测算法总览|全面解析YOLO V4网络结构
实操教程:PyTorch vs LibTorch:网络推理速度谁更快?|只用两行代码,我让Transformer推理加速了50倍|PyTorch AutoGrad C++层实现
算法技巧(trick):深度学习训练tricks总结(有实验支撑)|深度强化学习调参Tricks合集|长尾识别中的Tricks汇总(AAAI2021)
最新CV竞赛:2021 高通人工智能应用创新大赛|CVPR 2021 | Short-video Face Parsing Challenge|3D人体目标检测与行为分析竞赛开赛,奖池7万+,数据集达16671张!

# CV技术社群邀请函 #
△长按添加极市小助手
添加极市小助手微信(ID : cvmart2)
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
觉得有用麻烦给个在看啦~
