
基于深度学习的自然图像和医学图像分割:网络结构设计

极市导读
在利用CNNs进行图像语义分割时,有一些针对网络结构的创新点,主要包括了新神经架构和新组件或层的设计。文章的后半部分则对医学图像分割领域中网络结构设计的应用进行了梳理。>>>极市七夕粉丝福利活动:炼丹师们,七夕这道算法题,你会解吗?
1. 图像语义分割网络结构创新
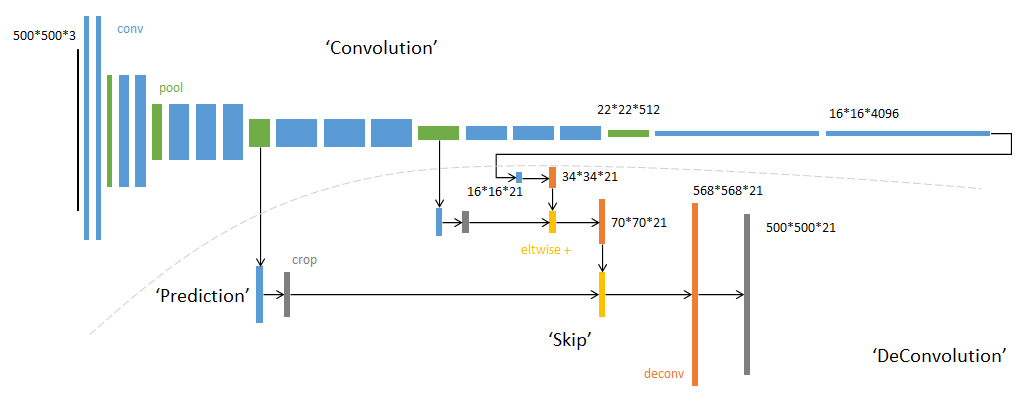
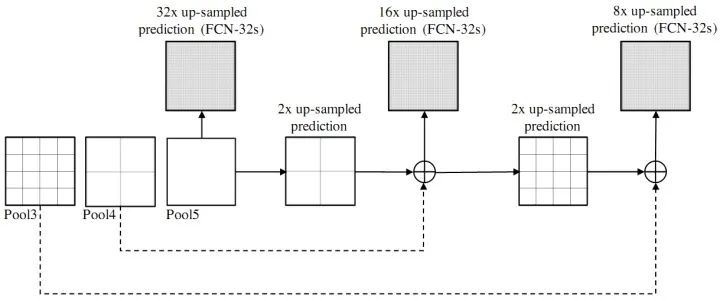
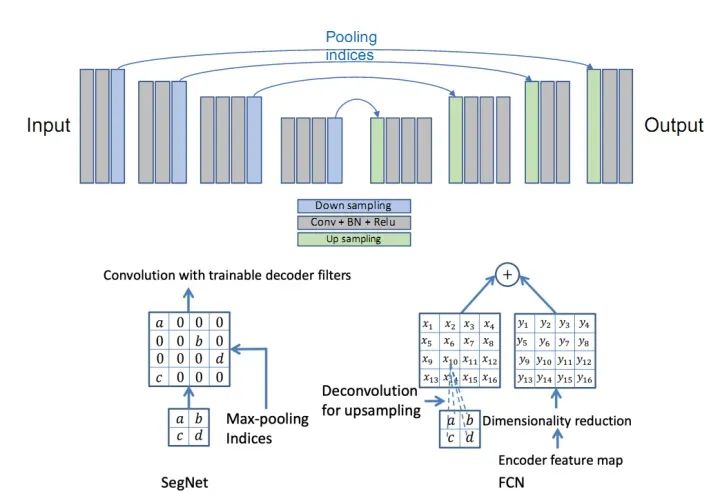
SegNet和FCN网络的思路基本一致。编码器部分使用VGG16的前13层卷积,不同点在于Decoder部分Upsampling的方式。FCN通过将特征图deconv得到的结果与编码器对应大小的特征图相加得到上采样结果;而SegNet用Encoder部分maxpool的索引进行Decoder部分的上采样(原文描述:the decoder upsamples the lower resolution input feature maps. Specifically, the decoder uses pooling indices computed in the max-pooling step of the corresponding encoder to perform non-linear upsampling.)。

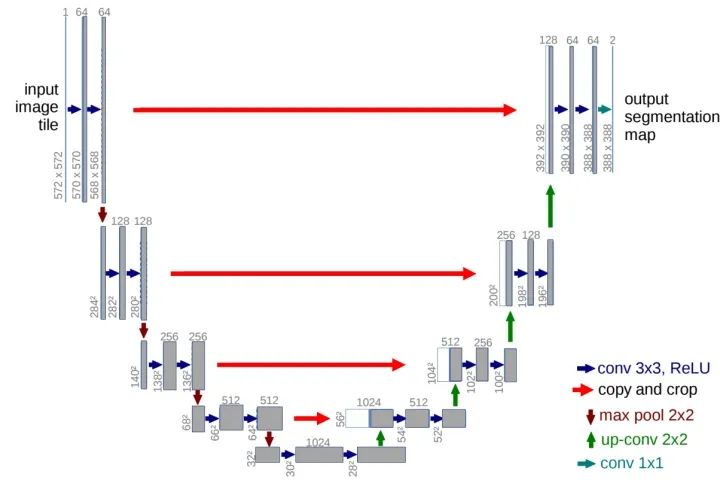
U-Net网络最初是针对生物医学图像设计的,但由于其初四的性能,现如今UNet及其变体已经广泛应用到CV各个子领域。UNet网络由U通道和短接通道(skip-connection)组成,U通道类似于SegNet的编解码结构,其中编码部分(contracting path)进行特征提取和捕获上下文信息,解码部分(expanding path)用解码特征图来预测像素标签。短接通道提高了模型精度并解决了梯度消失问题,特别要注意的是短接通道特征图与上采用特征图是拼接而不是相加(不同于FCN)。
V-Net网络结构与U-Net类似,不同在于该架构增加了跳跃连接,并用3D操作物替换了2D操作以处理3D图像(volumetric image)。并且针对广泛使用的细分指标(如Dice)进行优化。

FC-DenseNet (百层提拉米苏网络)(paper title: The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation)该网络结构是由用密集连接块(Dense Block)和UNet架构组建的。该网络最简单的版本是由向下过渡的两个下采样路径和向上过渡的两个上采样路径组成。且同样包含两个水平跳跃连接,将来自下采样路径的特征图与上采样路径中的相应特征图拼接在一起。上采样路径和下采样路径中的连接模式不完全同:下采样路径中,每个密集块外有一条跳跃拼接通路,从而导致特征图数量的线性增长,而在上采样路径中没有此操作。(多说一句,这个网络的简称可以是Dense Unet,但是有一篇论文叫Fully Dense UNet for 2D Sparse Photoacoustic Tomography Artifact Removal, 是一个光声成像去伪影的论文,我看到过好多博客引用这篇论文里面的插图来谈语义分割,根本就不是一码事好么 =_=||,自己能分清即可。)

Deeplab系列网络是在编解码结构的基础上提出的改进版本,2018年DeeplabV3+网络在VOC2012和Cityscapes数据集上的表现优异,达到SOTA水平。DeepLab系列共有V1、V2、V3和V3+共四篇论文。简要总结一些各篇论文的核心内容:

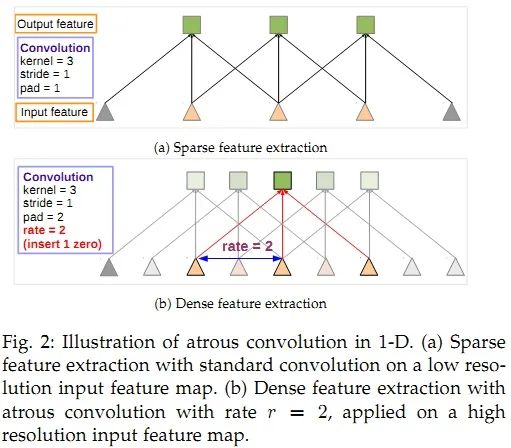




PSPNet(pyramid scene parsing network)通过对不同区域的上下文信息进行聚合,提升了网络利用全局上下文信息的能力。在SPPNet,金字塔池化生成的不同层次的特征图最终被flatten并concate起来,再送入全连接层以进行分类,消除了CNN要求图像分类输入大小固定的限制。而在PSPNet中,使用的策略是:poolling-conv-upsample,然后拼接得到特征图,然后进行标签预测。
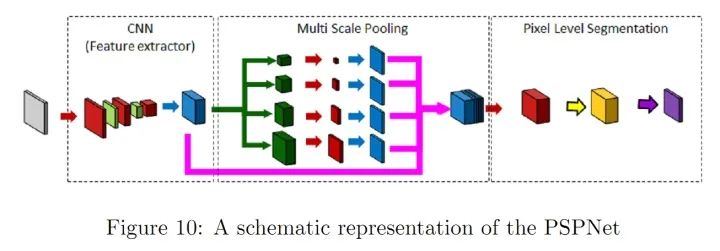
RefineNet通过细化中间激活映射并分层地将其连接到结合多尺度激活,同时防止锐度损失。网络由独立的Refine模块组成,每个Refine模块由三个主要模块组成,即:剩余卷积单元(RCU),多分辨率融合(MRF)和链剩余池(CRP)。整体结构有点类似U-Net,但在跳跃连接处设计了新的组合方式(不是简单的concat)。个人认为,这种结构其实非常适合作为自己网络设计的思路,可以加入许多其他CV问题中使用的CNN module,而且以U-Net为整体框架,效果不会太差。
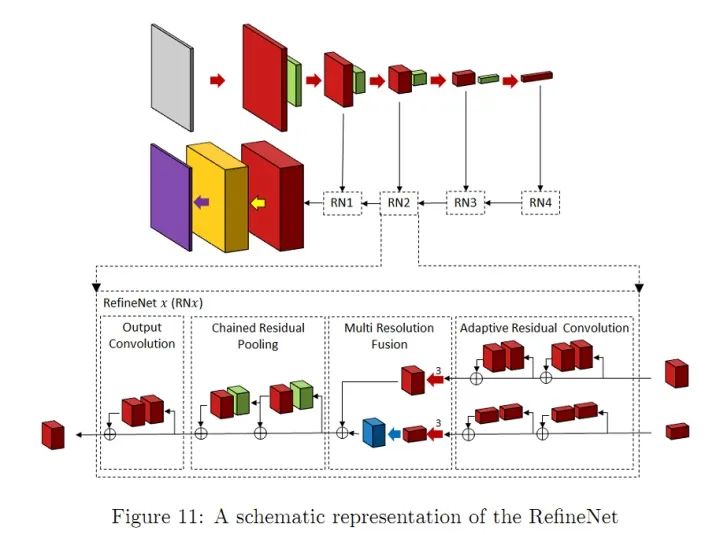
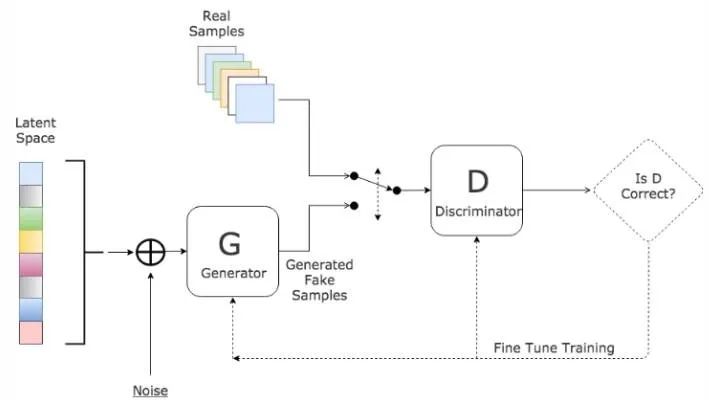

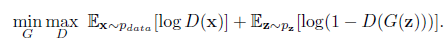
2. 网络结构创新在医学图像分割中的应用
推荐阅读

评论