
IROS 2021 | 没有图纸,机器人也会搭积木桥
点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
用积木拼搭各种建筑应该是很多小朋友童年的一大乐趣。现在,聪明的机器人也能自己玩积木了,而且不用人告诉它成品长什么样,机器人可以自己设计、建造一并完成。
AI 科技评论今天介绍一篇来自清华大学和字节跳动的研究者发表在 IROS 2021 的论文: “Learning to Design and Construct Bridge without Blueprint”

论文链接:https://arxiv.org/abs/2108.02439
介绍
这篇论文提出了机器人设计与搭积木桥任务。如图1最左所示,场景中有两个“悬崖”和若干积木,机器人的任务是利用尽量少的积木把悬崖连接起来。悬崖之间的距离是随机的,物料的数量也是变化的。
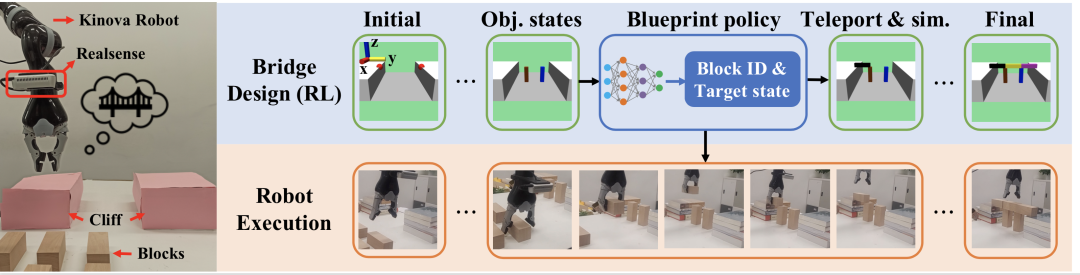
图1:机器人搭桥任务示意
需要强调的是,机器人搭桥任务中需要关注的问题和之前许多机器人操作(manipulation )任务不太一样。之前的工作比如装配 (assembly)、物体布置 (rearrangement)、堆积木 (stacking) 等,它们的最终目标状态都事先知道,不需要机器人自己规划每个物体的目标状态。这就相当于机器人拿着“设计师”给好的“图纸”,只需要负责规划怎样“施工”才能实现图纸上的状态。而在搭桥任务中,机器人手中并没有图纸,它看到的只是两个悬崖和能用来搭桥的积木。至于应该用多少块积木、每块积木摆在哪里才能把悬崖连起来、应该先放哪块再放哪块积木、具体应该怎么把积木放过去,所有的问题我们的机器人都要考虑,现在它得既当设计师又当工程师了。
由于搭桥的任务非常复杂,如果机械臂考虑的每一步动作仅仅是旋转自己关节的角度的话,那需要规划的步数是非常庞大的,直接解这样的问题几乎不可能。所以,该工作借鉴了 Task and Motion Planning (TAMP,任务与动作规划) 的做法,把搭桥抽象成两层问题来做。
在高一层,机器人只关心积木块的移动,每一步动作是“瞬移”一个积木,而省略掉机械臂操作积木的细节。在低一层,机械臂负责解算如何控制自己的关节才能把积木移动过去。换句话说,解决高层问题的智能体主要负责设计桥的形态,所以也叫它 blueprint policy(蓝图设计策略)。
而底层问题其实就是机械臂的 pick and place(抓取与放置)任务,可以交给传统的 motion planning(动作规划)方法解决。整体的框架如图1右侧所示。
搭桥的任务设定
在桌面上放置两个间距随机的物块当作悬崖,再给机器人提供数量不定的积木当物料,希望机器人能利用这些物料搭出某种结构,把两个悬崖连起来。
搭桥任务主要的难点就是在 blueprint policy 负责的桥梁设计环节。这个问题可以建模为一个 Markov 决策过程 ( MDP: Markov decision process,一种序列决策过程) ,由状态 (state),动作 (action),转移关系 (transition) 和奖励信号 (reward) 定义。Blueprint policy 在每一步会先获取环境的状态,然后决定采取什么样的动作,接着环境会转移到下一个状态,同时将奖励信号反馈给 blueprint policy。就这样,blueprint policy 通过不断地与环境交互,使用强化学习来调整自己的决策,提升自己的表现。MDP 中每个要素的具体定义是这样的:
状态:环境中所有物体的6自由度位姿(包括三维位置和三维旋转)、速度、尺寸;
动作:物体编号和目标位姿,它表示 blueprint policy 决定把该物体的位姿从当前状态变到目标状态;
转移关系:在物理引擎中先根据 blueprint policy 的动作,把选中的物体瞬移成动作中的目标状态,接着在重力作用下跑物理仿真,直到所有物体都稳定下来,物理引擎再把此时的状态作为转移到的新状态返回给 blueprint policy 。作者之所以让物理引擎继续模拟而不是直接返回瞬移结果,是因为 blueprint policy 指定的目标状态很可能在现实中没法稳定存在(比如积木悬浮在空中或者与其他物体有碰撞),通过物理仿真就能让 blueprint policy 知道什么样的状态是物理上可行的,帮助 blueprint policy 建立对物理规律的理解。
奖励信号:如果桥成功搭出来了,agent 会获得一个大的奖励信号。那怎么判断桥有没有成功搭起来呢?
本文沿着悬崖的中心连线均匀地采样若干个点,检查了每个采样点的上表面高度,如果所有采样点的高度都大于一定的阈值,就认为桥搭成功了。此外,agent 在建造的中途还可以获得一些比较小的奖励信号:当部分采样点的高度到达阈值的时候,可以获得正比于这部分点占总点数比例的奖励。为了鼓励 agent 用尽量节省物料的方式搭出平整的桥,作者还在判断搭桥成功的基础上给用物体少的桥和平整的桥额外的奖励。agent 收到的奖励信号是上面所有项的加和。
设计桥梁的策略学习
任务设定清楚之后,还要采用合适的策略网络结构和算法来解决它。Agent需要建立对环境中物体间的关系的理解,还需要具有一定的在不同数量物体之间泛化的能力。
为了更好地学习能在物体间泛化的策略,研究者采用了基于Transformer 编码器的网络结构来从场景中所有物体的状态提取特征。如图2左侧,把每一个物体的状态当作一个 token 来处理,将它们的嵌入表示 (embedding) 经过N个注意力块 (attention block) 处理,充分地建模物体与物体之间的关系信息,得到特征。之后再经过多个线性层得到策略网络 (policy) 和估值函数 (value) 输出。
作者采用 PPG (Phasic Policy Gradient,阶段策略梯度) 算法来训练 blueprint policy。PPG 是在 PPO (Proximal Policy Optimization,近端策略优化) 基础上提出的一种在线强化学习算法,它的长处在于能巧妙地将 value 网络学到的有用知识与 policy 网络共享,使得强大的 Tranformer encoder 同时惠及 policy 和 value 网络。PPG 有 "shared" 共享和 "dual" 非共享两种实现架构,其中 shared 架构中 policy 和 value head 共享了 feature extractor 的参数,而dual架构不共享 参数。
PPG的技术细节可以参考原文,在此不再展开。
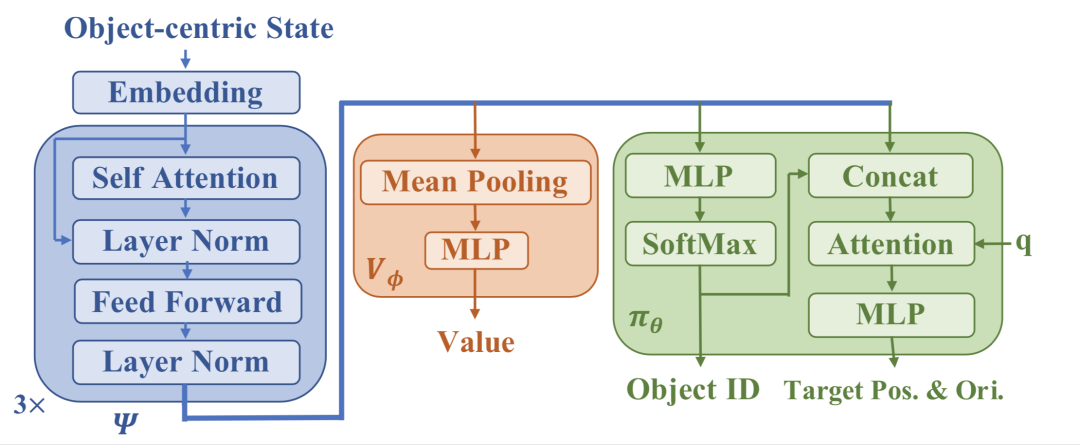
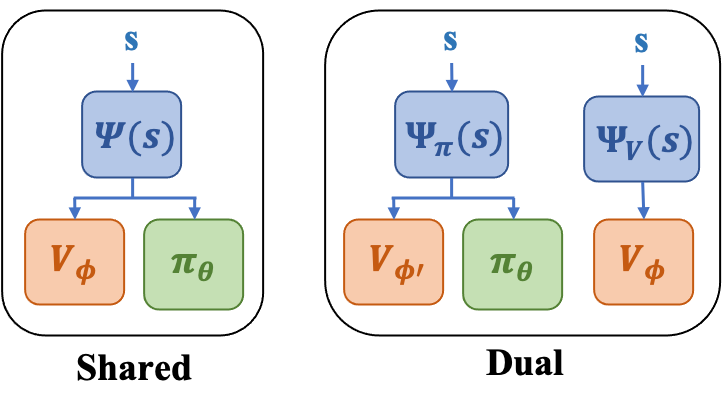
图2: Blueprint policy网络结构
虽然该文的目标是希望机器人能用很多积木搭出复杂的桥,但在训练初期 agent 水平很低的时候就提供这样的任务对它来说太困难了,就如同强行让小学生啃大学教材;因此我们采用了自适应的课程 (curriculum) 来调节训练任务的难度。最开始悬崖之间的距离是从整个任务分布中均匀采样的,有的很近有的很远;随着搭桥成功率渐渐提升,会逐渐增大采样到较远的悬崖距离的概率。
机械臂控制策略实现
机械臂底层控制策略负责用 pick and place 来完成 blueprint policy 设定的每一步目标,真正地用机械臂移动积木。研究者使用了传统的 motion planning 算法做六自由度抓取(包含抓取的三自由度位置和三自由度旋转),完成 pick and place 任务。
仿真和真机实验
文章首先在仿真环境中看看agent设计出了什么样的桥梁。在悬崖之间距离比较近的时候,agent学出先竖着放一个积木当支柱,再把两块积木横着架上去。在距离更远的时候,它能学会按照合适的间距摆放更多的支撑物,再放桥面。
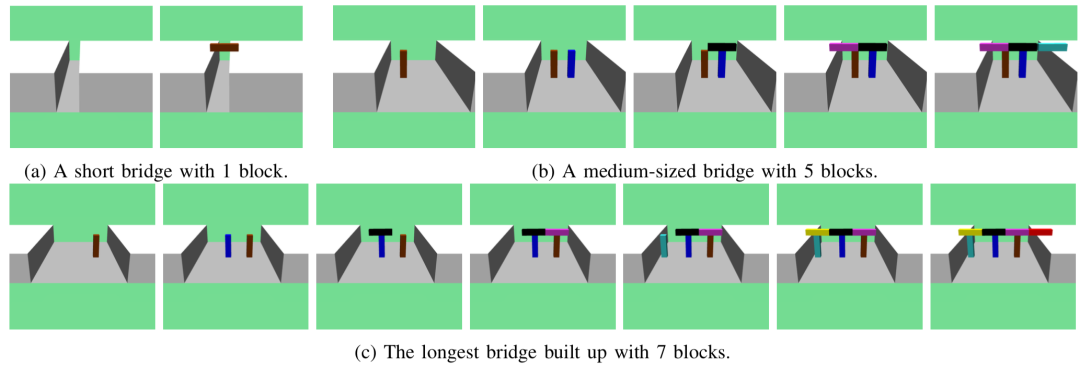
图3: Agent学会了设计不同长度的桥梁
有时候agent第一次放的位置不是特别好,它还知道回过头来微调。比如图4(a)中agent发现桥面不太平整的时候会重新放置横着的积木。图4(b)中桥成形以后它发现棕色积木是多余的,就把它挪走了。

图4: 自己微调设计得不好的桥
作者采用搭桥成功率来衡量 blueprint policy 的表现。下图左展示了使用不同算法(PPG,PPO)和不同的网络架构 (shared,dual) 时的训练曲线。红线是最终采用的组合,它能以0.8的成功率设计出需要用7块积木的桥。图右展示了 curriculum learning 的关键作用,蓝色线是不从简单的任务学起,直接挑战高难度桥梁的训练情况,它的学习效率明显低于加了curriculum的红色线。
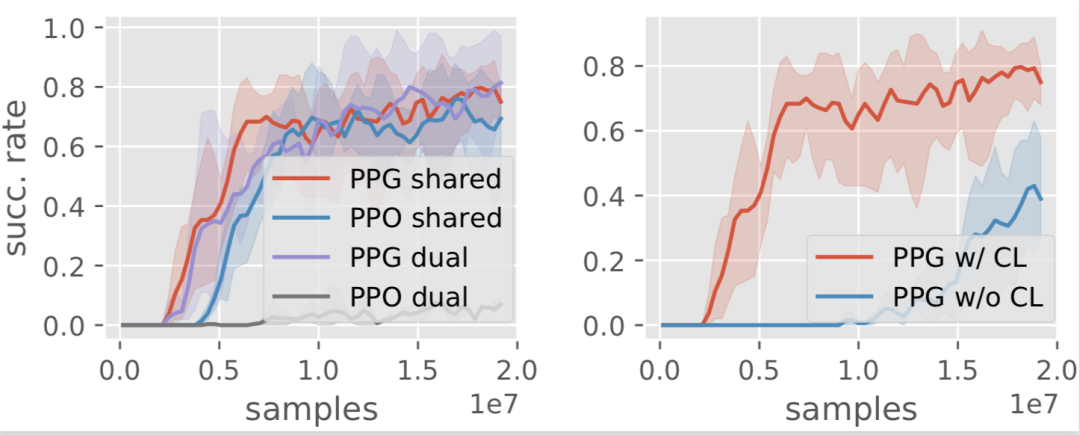
图5: 消融实验的训练曲线
最后将机械臂的底层控制加入,看看机器人搭桥的最终效果。作者用6轴的Kinova机械臂做了真机实验。不管是只需要放一块积木的迷你桥,还是需要加支撑块的T形、 形桥,机器人建造师都从容应对,成功完成任务。

图6: Kinova 机器人搭出不同长度的桥
项目视频:
总结
这篇工作提出了“机器人搭桥”的自动装配任务,研究在不事先给定蓝图的情况下如何同时进行结构设计与建造。
本文将搭桥任务拆解成高层设计与底层建造两部分,设计部分利用深度强化学习算法训练,建造部分由传统动作规划方法实现,在实验中能根据悬崖之间随机的距离成功设计建造不同形态的积木桥。
参考文献
Y. Li, T. Kong, L. Li, Y. Li, and Y. Wu, "Learning to Design and Construct Bridge without Blueprint", CoRR, vol. abs/2108.02439, 2021.
L. P. Kaelbling and T. Lozano-Pe ́rez, “Hierarchical task and motion planning in the now,” in 2011 IEEE International Conference on Robotics and Automation. IEEE, 2011, pp. 1470–1477.
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Decem- ber 4-9, 2017, Long Beach, CA, USA, I. Guyon, U. von Luxburg, S. Bengio, H. M. Wallach, R. Fergus, S. V. N. Vishwanathan, and R. Garnett, Eds., 2017, pp. 5998–6008.
K. Cobbe, J. Hilton, O. Klimov, and J. Schulman, “Phasic policy gradient,” CoRR, vol. abs/2009.04416, 2020.
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” CoRR, vol. abs/1707.06347, 2017.
Y. Bengio, J. Louradour, R. Collobert, and J. Weston, “Curriculum learning,” in Proceedings of the 26th annual international conference on machine learning, 2009, pp. 41–48.
—版权声明—
仅用于学术分享,版权属于原作者。
若有侵权,请联系微信号:yiyang-sy 删除或修改!