
机器学习数据不满足同分布,怎么整?
机器学习作为一门科学,不可避免的是,科学本身是基于归纳得到经验总结,必然存在历史经验不适用未来的情况(科学必可证伪)。这里很应景地讲一个小故事--By 哲学家罗素:
农场有一群火鸡,农夫每天来给它们喂食。经过长期观察后,一只火鸡(火鸡中的科学鸡)得出结论,“每天早上农夫来到鸡舍,我就有吃的”,之后每天的经历都在证实它的这个结论。但是有一天,农夫来到鸡舍,没有带来食物而是把它烤了,因为这天是圣诞节,做成了圣诞节火鸡。

通过有限的观察,得出自以为正确的规律性结论的,结局如是此。以这角度,我们去看AI/机器学习的应用,也能看到很多类似的例子。
机器学习是研究怎样使用计算机模拟或实现人类学习活动的科学,是基于一系列假设(基本的如,独立同分布假设)归纳得到经验,进行预测的过程。
也不可避免的,机器学习中也可能出现预测的数据与训练数据不满足同分布,历史数据经验不那么适用了! 导致预测效果变差或失效的情况。这就类似我们考试的时候,发现这类型的题目我没有见过,歇菜了...
一、什么是数据不满足同分布
实际预测与训练数据不满足同分布的问题,也就是数据集偏移(Dataset shift),是机器学习一个很重要的问题。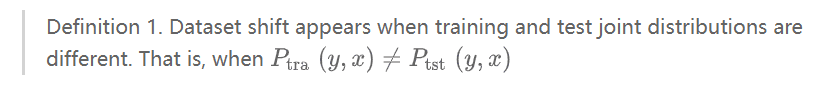
从贝叶斯定理可得P(y,x) = P(y|x) * P(x) = P(x|y) * P(y),当输入空间的边缘概率分布P(x) , 输出空间的标签分布P(y) 以及表示该机器学习任务的条件概率分布 P(y|x) 之中,有任一项因素发生偏移导致训练数据与预测数据 P(y,x)造成差异,即为数据集偏移现象。
不同因素对应着如下三种情况得数据偏移:
Covariate shift:协变量偏移(统计学中的协变量即机器学习中的特征的概念), 指的是输入空间的边缘概率分布P(x),也就输入特征x分布变化导致的偏移。这个应该是最为常见的,比如图像识别任务中,训练时输入的人脸图像数据没戴口罩,而预测的时候出现了很多戴口罩人脸的图像。 再如反欺诈识别中,实际预测欺诈用户的欺诈行为发生升级改变,与训练数据的行为特征有差异的情况。
Prior probability shift:先验偏移,指的是标签分布P(Y) 差异导致的。比如反欺诈识别中,线上某段时间欺诈用户的比例 对比 训练数据 突然变得很大的情况。
Concept shift:映射关系偏移,指P(y|x) 分布变化,也就是x-> y的映射关系发生变化。比如农场的火鸡,本来x是【 早上/农夫/来到/鸡舍】对应着 y是【火鸡被喂食】,但是圣诞节那天这层关系突然变了,x还是【 早上/农夫/来到/鸡舍】但对应着 y是【火鸡被烤了】..hah,留下心疼的口水..
二、为什么数据不满足同分布
可能导致数据不满足同分布的两个常见的原因是:
(1)样本选择偏差(Sample Selection Bias) :分布上的差异是由于训练数据是通过有偏见的方法获得的。
比如金融领域的信贷客群是通过某种渠道/规则获得的,后面我们新增加营销渠道获客 或者 放宽了客户准入规则。这样就会直接导致实际客群样本比历史训练时点的客群样本更加多样了(分布差异)。
(2)不平稳环境(Non-stationary Environments):由于时间上的或空间上的变化导致训练与测试环境不同。
比如金融领域,预测用户是否会偿还贷款的任务。有一小类用户在经济环境好的时候有能力偿还债务,但是由于疫情或其他的影响,宏观经济环境不太景气,如今就无法偿还了。
三、如何检测数据满足同分布
可能我们模型在训练、验证及测试集表现都不错,但一到OOT(时间外样本)或者线上预测的时候,效果就掉下来了。这时我们就不能简单说是模型复杂导致过拟合了,也有可能是预测数据的分布变化导致的效果变差。我们可以通过如下常用方式检测数据分布有没有变化:
3.1 统计指标的方法
通过统计指标去检测分布差异是很直接的,我们通常用群体稳定性指标(Population Stability Index,PSI), 衡量未来的样本(如测试集)及训练样本评分的分布比例是否保持一致,以评估数据/模型的稳定性(按照经验值,PSI<0.1分布差异是比较小的。)。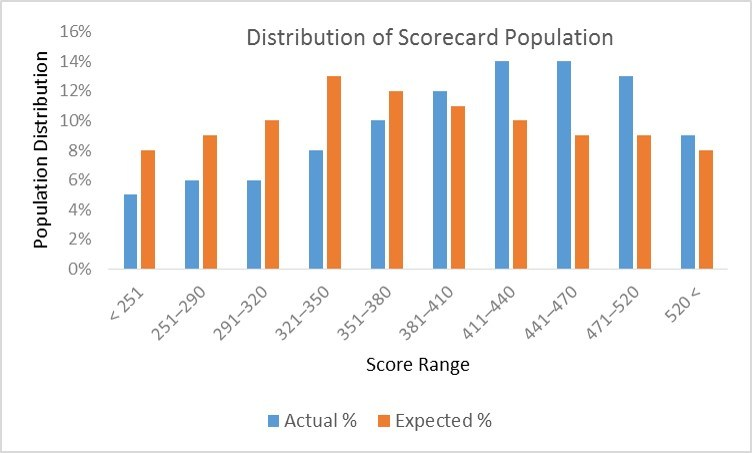 同理,PSI也可以细化衡量特征值的分布差异,评估数据特征层面的稳定性。PSI指标计算公式为 SUM(各分数段的 (实际占比 - 预期占比)* ln(实际占比 / 预期占比) ),介绍可见:指标。其他的方法如 KS检验,KDE (核密度估计)分布图等方法可见参考链接[2]
同理,PSI也可以细化衡量特征值的分布差异,评估数据特征层面的稳定性。PSI指标计算公式为 SUM(各分数段的 (实际占比 - 预期占比)* ln(实际占比 / 预期占比) ),介绍可见:指标。其他的方法如 KS检验,KDE (核密度估计)分布图等方法可见参考链接[2]
3.2 异常(新颖)点检测的方法
可以通过训练数据集训练一个模型(如 oneclass-SVM),利用模型判定哪些数据样本的不同于训练集分布(异常概率)。异常检测方法可见:异常检测算法速览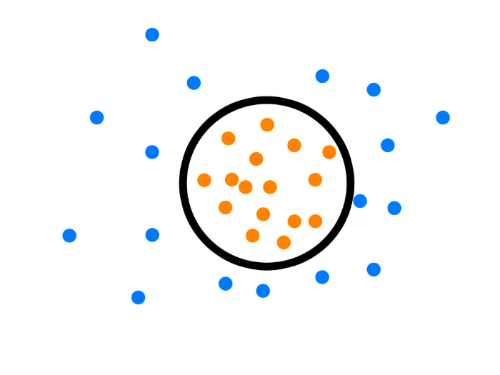
3.3 分类的方法
混合训练数据与测试数据(测试数据可得情况),将训练数据与测试数据分别标注为’1‘和’0‘标签,进行分类,若一个模型,可以以一个较好的精度将训练实例与测试实例区分开,说明训练数据与测试数据的特征值分布有较大差异,存在协变量偏移。
相应的对这个分类模型贡献度比较高的特征,也就是分布偏差比较大的特征。分类较准确的样本(简单样本)也就是分布偏差比较大的样本。
四、如何解决数据不满足同分布
4.1 增加数据
增加数据是王道,训练数据只要足够大,什么场面没见过,测试数据的效果自然也可以保证。
如上面的例子,作为一只农场中的科学鸡,如果观察到完整周期、全场景的数据,或者被灌输一些先验知识,就能更为准确预测火鸡的命运。
但是现实情况可能多少比较无奈,可能业务场景的原因限制,并不一定可以搞得到更多数据,诸如联邦学习、数据增强等方法也是同样的思路。
4.2 数据增强
在现实情况没法新增数据的时候,数据增强(Data Augmentation)是一个备选方案,在不实质性的增加数据的情况下,从原始数据加工出更多的表示,提高原数据的数量及质量,以接近于更多数据量产生的价值。
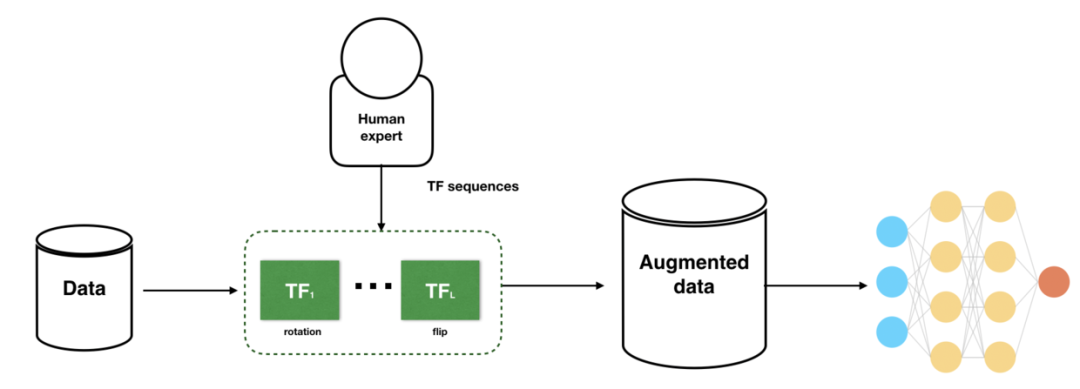
其原理是通过对原始数据融入先验知识,加工出更多数据的表示,有助于模型判别数据中统计噪声,加强本体特征的学习,减少模型过拟合,提升泛化能力。具体可见:数据增强方法
4.3 选择数据
我们可以选择和待预测样本分布比较一致的数据做模型训练,使得在待预测样本的效果变得更好。
这个方法看起来有点投机,这在一些数据波动大的数据竞赛中很经常出现,直接用全量训练样本的结果不一定会好,而我们更改下数据集划分split的随机种子(如暴力for循环遍历一遍各个随机种子的效果),或者 人工选择与线上待预测样本业务类型、 时间相近的样本集用于训练模型(或者 提高这部分样本的学习权重),线上数据的预测效果就提升了。
4.4 半监督学习
半监督学习 是介于传统监督学习和无监督学习之间,其思想是通过在模型训练中直接引入无标记样本,以充分捕捉数据整体潜在分布,以改善如传统无监督学习过程盲目性、监督学习在训练样本不足导致的学习效果不佳的问题。
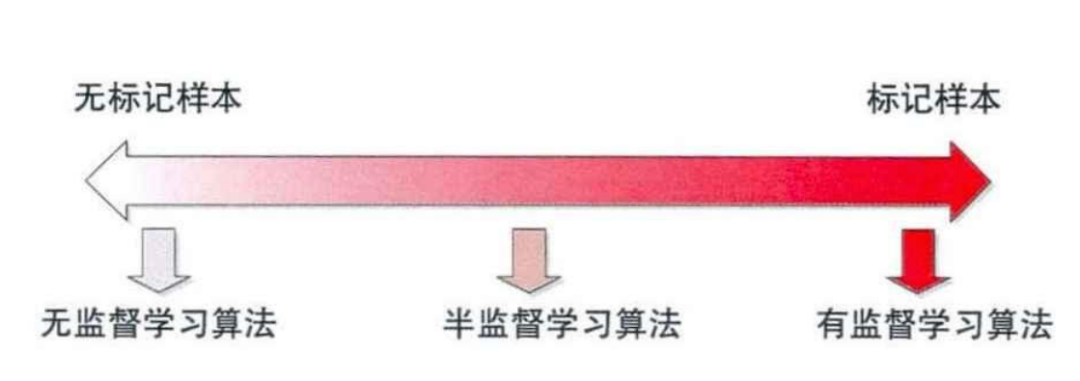
通过半监督学习,训练时候可以充分捕捉数据整体潜在分布,同理也可以缓解预测数据分布有差异的问题。半监督分类常用的做法是,通过业务含义或者模型选择出一些虽然无标签的样本,并打上大概率的某个标签(伪标签)加入到训练数据中,验证待预测样本的效果有没有变好。
经典的如金融信贷领域的拒绝推断方法(参考链接[6]),我们可以从贷款被拒绝的用户中(这部分用户是贷款的时候直接被拒绝了,没有"是否违约"的标签),通过现有信贷违约模型(申请评分卡)预测这部分拒绝用户的违约概率,并把模型认为大概率违约的用户作为坏样本加入到训练样本中,以提升模型的泛化效果。
4.5 特征选择
对于常见的协变量偏移,用特征选择是一个不错的方法。我们可以分析各个特征在分布稳定性(如PSI值)的情况,筛选掉分布差异比较大的特征。需要注意的是,这里适用的是筛掉特征重要性一般且稳定性差的特征。如果重要特征的分布差距也很大,这就难搞了,还是回头搞搞数据或者整整其他的强特征。特征选择方法可见:python特征选择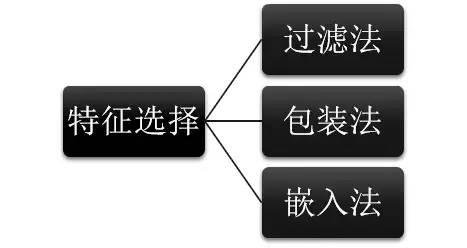
4.6 均衡学习
均衡学习适用与标签分布差异(先验偏移)导致的数据集偏移。均衡学习的方法可以归结为:通过某种方法,使得不同类别的样本对于模型学习中的Loss(或梯度)贡献是比较均衡的,以消除模型对不同类别的偏向性,学习到更为本质的决策。
比如原反欺诈训练样本中,好坏样本的比例是1000:1,但到了预测,有时实际的好坏样本的比例是10:1。这时如果没有通过均衡学习,直接从训练样本学习到模型,会先天认为欺诈坏样本的概率就是很低的,导致很多欺诈坏样本的漏判。

不均衡的任务中,一方面可以通过代价敏感、采样等方法做均衡学习;另一方面也可以通过合适指标(如AUC),减少非均衡样本的影响去判定模型的效果。具体可见:一文解决样本不均衡(全)
最后,机器学习是一门注重实践的科学,在实践中验证效果,不断探索原理。
仅以此文致敬我们的数据科学鸡啊。
参考链接:
1、理解数据集偏移 https://zhuanlan.zhihu.com/p/449101154
3、训练集和测试集的分布差距太大有好的处理方法吗 https://www.zhihu.com/question/265829982/answer/1770310534
4、训练集与测试集之间的数据偏移(dataset shift or drifting) https://zhuanlan.zhihu.com/p/304018288
5、数据集偏移&领域偏移 Dataset Shift&Domain Shift https://zhuanlan.zhihu.com/p/195704051
6、如何量化样本偏差对信贷风控模型的影响?https://zhuanlan.zhihu.com/p/350616539
-推荐阅读-
深度学习系列
回复【课程】:即可免费领取Python、机器学习、AI 等精品课程资料大全
回复【加群】:可提问咨询、共享资源...与群内伙伴一起交流,共同进步
或扫码👇,备注“加群”
