
深度理解:神经网络的训练过程
来源丨CV技术指南 作者丨Daryl Chang 编辑丨极市平台
这篇文章非常全面细致地介绍了Batch Size的相关问题。结合一些理论知识,通过大量实验,文章探讨了Batch Size的大小对模型性能的影响、如何影响以及如何缩小影响等有关内容。
在本文中,我们试图更好地理解批量大小对训练神经网络的影响。具体而言,我们将涵盖以下内容:
什么是Batch Size? 为什么Batch Size很重要? 小批量和大批量如何凭经验执行? 为什么大批量往往性能更差,如何缩小性能差距?
什么是Batch Size?
训练神经网络以最小化以下形式的损失函数:
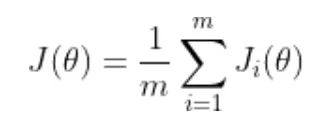
theta 代表模型参数 m 是训练数据样本的数量 i 的每个值代表一个单一的训练数据样本 J_i 表示应用于单个训练样本的损失函数
通常,这是使用梯度下降来完成的,它计算损失函数相对于参数的梯度,并在该方向上迈出一步。随机梯度下降计算训练数据子集 B_k 上的梯度,而不是整个训练数据集。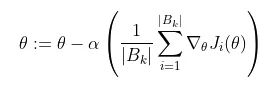
B_k 是从训练数据集中采样的一批,其大小可以从 1 到 m(训练数据点的总数)。这通常称为批量大小为 |B_k| 的小批量训练。我们可以将这些批次级梯度视为“true”梯度的近似值,即整体损失函数相对于 theta 的梯度。我们使用小批量是因为它倾向于更快地收敛,因为它不需要完全遍历训练数据来更新权重。
为什么Batch Size很重要?
Keskar 等人指出,随机梯度下降是连续的,且使用小批量,因此不容易并行化 。使用更大的批量大小可以让我们在更大程度上并行计算,因为我们可以在不同的工作节点之间拆分训练示例。这反过来可以显着加快模型训练。
然而,较大的批大小虽然能够达到与较小的批大小相似的训练误差,但往往对测试数据的泛化效果更差 。训练误差和测试误差之间的差距被称为“泛化差距”。因此,“holy grail”是使用大批量实现与小批量相同的测试误差。这将使我们能够在不牺牲模型准确性的情况下显着加快训练速度。
实验是如何设置的?
我们将使用不同的批量大小训练神经网络并比较它们的性能。
数据集:我们使用 Cats and Dogs 数据集,该数据集包含 23,262 张猫和狗的图像,在两个类之间的比例约为 50/50。由于图像大小不同,我们将它们全部调整为相同大小。我们使用 20% 的数据集作为验证数据,其余作为训练数据。
评估指标:我们使用验证数据上的二元交叉熵损失作为衡量模型性能的主要指标。

基础模型:定义了一个受 VGG16 启发的基础模型,在其中重复应用 (convolution ->max-pool) 操作,使用 ReLU 作为卷积的激活函数。然后,将输出量展平并将其送入两个完全连接的层,最后是一个带有 sigmoid 激活的单神经元层,产生一个介于 0 和 1 之间的输出,它表明模型是预测猫(0)还是 狗 (1).
训练:使用学习率为 0.01 的 SGD。一直训练到验证损失在 100 次迭代中都没有改善为止。
Batch Size如何影响训练?
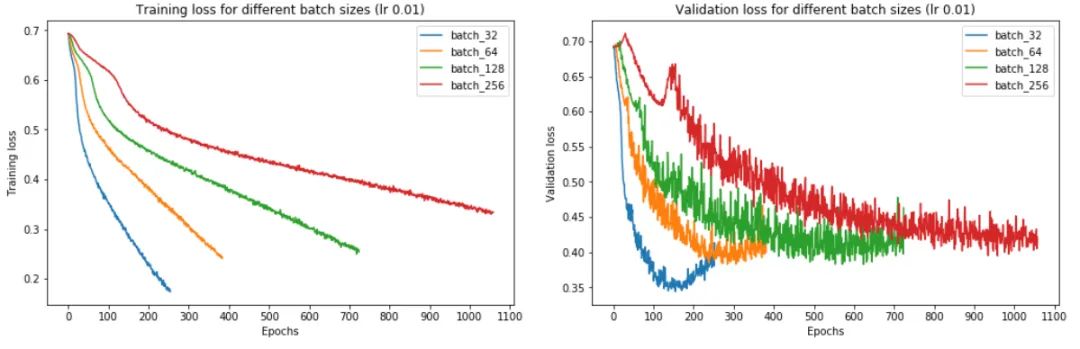
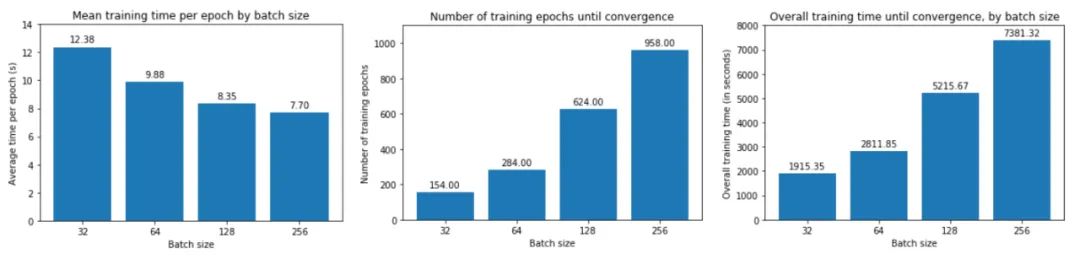
从上图中,我们可以得出结论,batch size越大:
训练损失减少的越慢。
最小验证损失越高。
每个时期训练所需的时间越少。
收敛到最小验证损失所需的 epoch 越多。
让我们一一了解这些。首先,在大批量训练中,训练损失下降得更慢,如红线(批量大小 256)和蓝线(批量大小 32)之间的斜率差异所示。
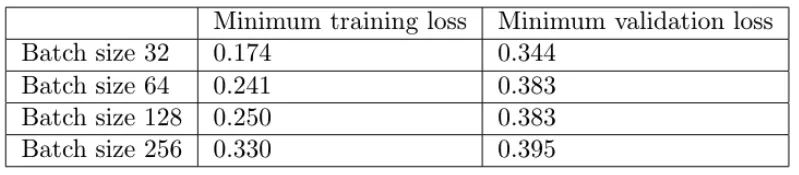
其次,大批量训练比小批量训练实现更糟糕的最小验证损失。例如,批量大小为 256 的最小验证损失为 0.395,而批量大小为 32 时为 0.344。
第三,大批量训练的每个 epoch 花费的时间略少——批量大小 256 为 7.7 秒,而批量大小 256 为 12.4 秒,这反映了与加载少量大批量相关的开销较低,而不是许多小批量依次。如果我们使用多个 GPU 进行并行训练,这种时间差异会更加明显。
然而,大批量训练需要更多的 epoch 才能收敛到最小值——批量大小 256 为 958,批量大小 32 为 158。因此,大批量训练总体上花费的时间更长:批量大小 256 花费的时间几乎是 32 的四倍!请注意,我们没有在这里并行化训练——如果我们这样做了,那么大批量训练的训练速度可能与小批量训练一样快。
如果我们并行化训练运行会发生什么?为了回答这个问题,我们使用 TensorFlow 中的 MirroredStrategy 在四个 GPU 上并行训练:
with tf.distribute.MirroredStrategy().scope(): # Create, compile, and fit model # ...
MirroredStrategy 将模型的所有变量复制到每个 GPU,并将前向/后向传递计算批量分发到所有 GPU。然后,它使用 all-reduce 组合来自每个 GPU 的梯度,然后将结果应用于每个 GPU 的模型副本。本质上,它正在划分批次并将每个块分配给 GPU。
我们发现并行化使每个 epoch 的小批量训练速度稍慢,而它使大批量训练速度更快——对于 256 批大小,每个 epoch 需要 3.97 秒,低于 7.70 秒。然而,即使有 per-epoch 加速,它也无法在总训练时间方面匹配批量大小 32——当我们乘以总训练时间 (958) 时,我们得到大约 3700 秒的总训练时间,即 仍然远大于批大小 32 的 1915 秒。
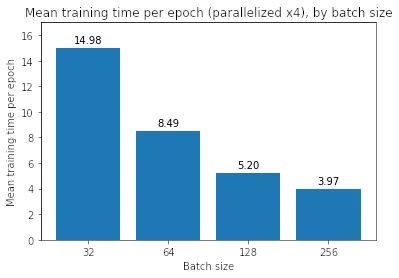
到目前为止,大批量训练看起来并不值得,因为它们需要更长的时间来训练,并且训练和验证损失更严重。 为什么会这样?有什么办法可以缩小性能差距吗?
为什么较小的批量性能更好?
Keskar 等人对小批量和大批量之间的性能差距提出了一种解释:使用小批量的训练倾向于收敛到平坦的极小化,该极小化在极小化的小邻域内仅略有变化,而大批量则收敛到尖锐的极小化,这变化很大。平面minimizers 倾向于更好地泛化,因为它们对训练集和测试集之间的变化更加鲁棒 。
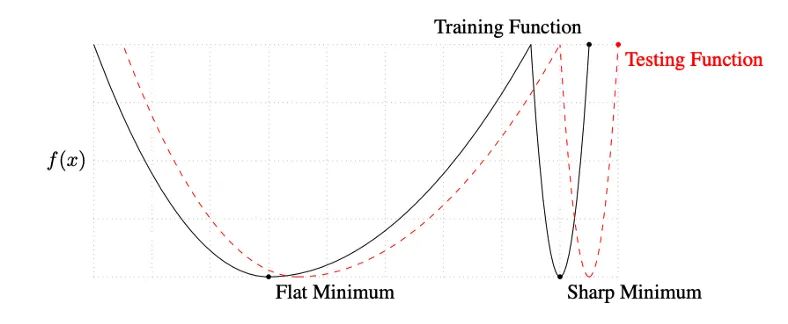
此外,他们发现与大批量训练相比,小批量训练可以找到距离初始权重更远的最小值。他们解释说,小批量训练可能会为训练引入足够的噪声,以退出锐化minimizers 的损失池,而是找到可能更远的平坦minimizers 。
让我们验证这些假设。
假设 1:与大批量最小化器相比,小批量minimizers 离初始权重更远。
我们首先测量初始权重和每个模型找到的最小值之间的欧几里德距离。
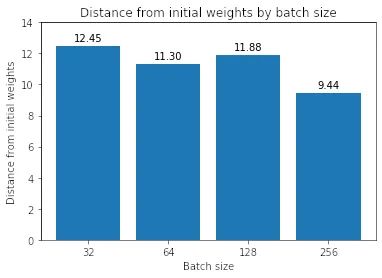
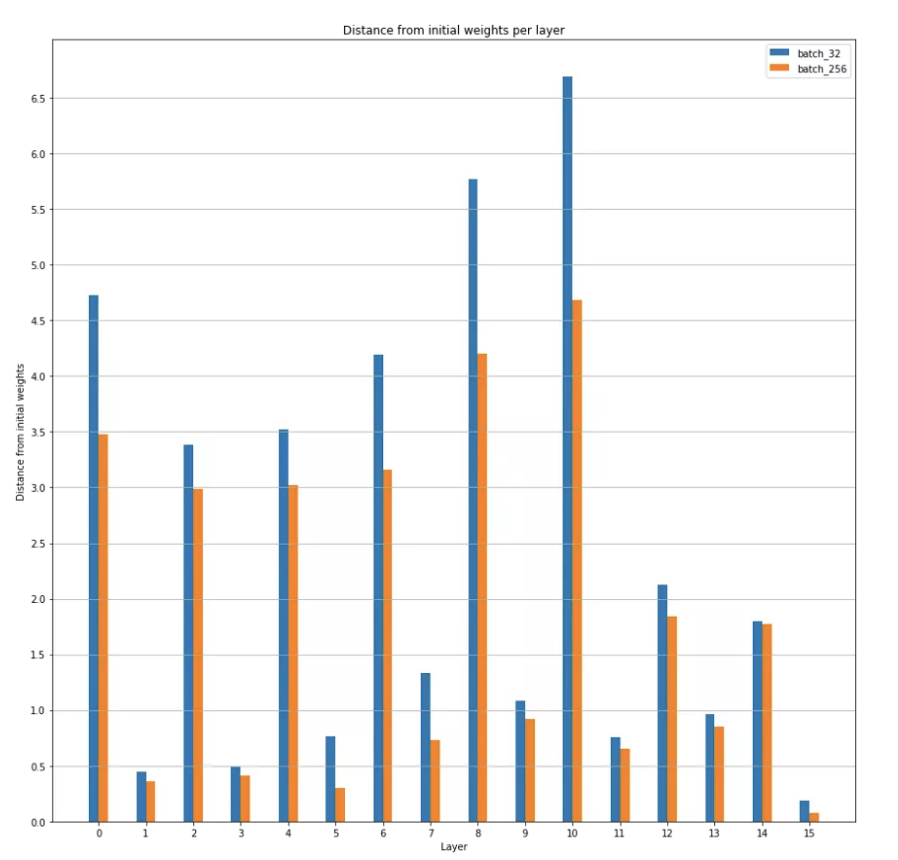
按层与初始权重的距离,批大小 32 和 256 的比较
事实上,我们发现一般来说,批量越大,最小值越接近初始权重。(除了批量大小 128 比批量大小 64 离初始权重更远)。我们还在图 11 中看到,模型中的不同层都是如此。
为什么大批量训练最终更接近初始权重?是否采取较小的更新步骤?让我们通过测量epoch距离——即epoch i 中的最终权重与epoch i 中的初始权重之间的距离——找出批量大小 32 和 256 的原因。
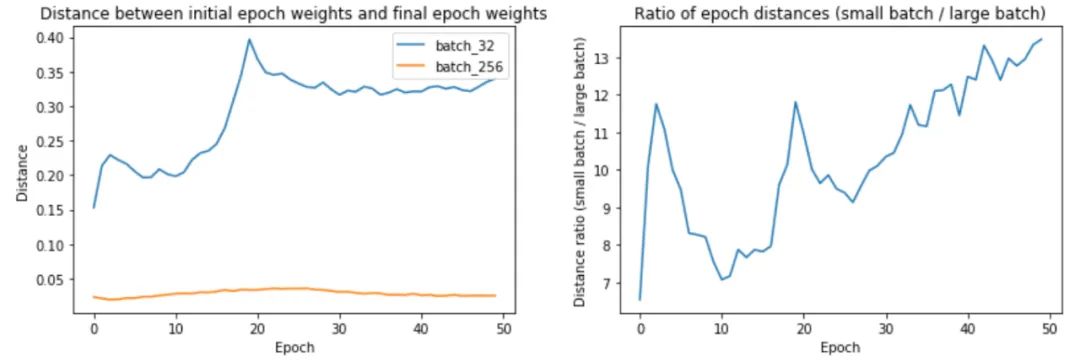
上面的第一幅图显示,较大的批次大小确实确实在每个 epoch 中遍历的距离更短。第 32 批训练的 epoch 距离从 0.15 到 0.4 不等,而第 256 批训练的距离约为 0.02–0.04。事实上,正如我们在第二个图中所看到的,epoch距离的比率随着时间的推移而增加!
但是为什么大批量训练每个 epoch 遍历的距离更短呢?是因为我们的批次较少,因此每个 epoch 的更新较少吗?还是因为每次批量更新遍历的距离更短?或者,答案是两者的结合?
为了回答这个问题,让我们测量每个批量更新的大小。
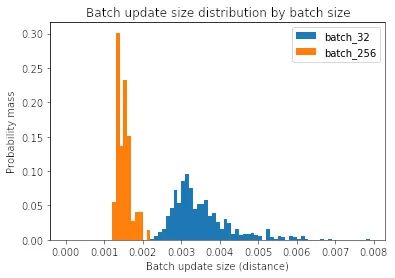
Median batch update norm for batch size 32: 3.3e-3Median batch update norm for batch size 256: 1.5e-3
我们可以看到,当批大小较大时,每次批更新较小。为什么会这样?
为了理解这种行为,让我们设置一个虚拟场景,其中我们有两个梯度向量 a 和 b,每个表示一个训练示例的梯度。让我们考虑一下批量大小 = 1 的平均批量更新大小与批量大小 = 2 的情况相比如何。
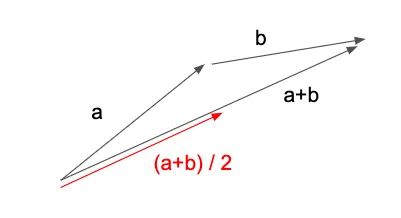
如果我们使用 1 的批量大小,我们将在 a 的方向上迈出一步,然后是 b,最终在 a+b 表示的点上。(从技术上讲,b 的梯度将在应用 a 后重新计算,但我们现在先忽略它)。这导致平均批量更新大小为 (|a|+|b|)/2 — 批量更新大小的总和除以批量更新的数量。
但是,如果我们使用批量大小为 2,批量更新将改为由向量 (a+b)/2 表示 — 图 12 中的红色箭头。因此,平均批量更新大小为 |(a+b)/ 2| / 1 = |a+b|/2。
现在,让我们比较两个平均批量更新大小:
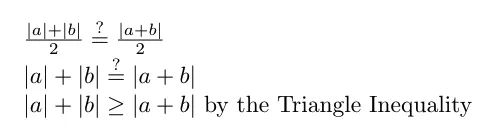
在最后一行中,我们使用三角不等式来表明批量大小 1 的平均批量更新大小始终大于或等于批量大小 2 的平均批量更新大小。
换句话说,为了使批量大小 1 和批量大小 2 的平均批量大小相等,向量 a 和 b 必须指向相同的方向,因为那是 |a| 的时候。+ |b| = |a+b|。我们可以将此参数扩展到 n 个向量——只有当所有 n 个向量都指向同一方向时,batch size=1 和 batch size=n 的平均批量更新大小才相同。然而,这几乎从来都不是这样的,因为梯度向量不太可能指向完全相同的方向。
如果我们回到图 16 中的小批量更新方程,我们在某种意义上说,当我们扩大批量大小 |B_k| 时,梯度总和的大小相对较慢地扩大。这是因为梯度向量指向不同的方向,因此将批量大小(即要加在一起的梯度向量的数量)加倍并不会使生成的梯度向量总和的大小加倍。同时,我们除以分母 |B_k|这是两倍大,导致整体更新步骤更小。
这可以解释为什么更大批量的批量更新往往更小——梯度向量的总和变得更大,但不能完全抵消更大的分母|B_k|。
假设 2:小批量训练找到更平坦的最小值
现在让我们测量两个minimizers的锐度,并评估小批量训练找到更平坦的minimizers的说法。(请注意,第二个假设可以与第一个假设共存——它们并不相互排斥。)为此,我们从 Keskar 等人那里借用了两种方法。
在第一个中,我们沿着小批量minimizers(批量大小 32)和大批量minimizers(批量大小 256)之间的线绘制训练和验证损失。这条线由以下等式描述:
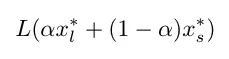
其中 x_l* 是大批量minimizers,x_s* 是小批量minimizers,alpha 是一个介于 -1 和 2 之间的系数。
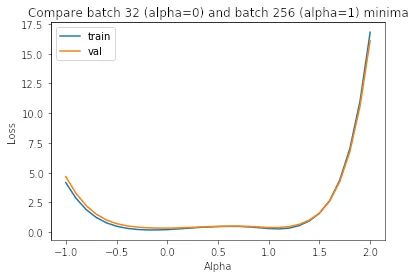
正如我们在图中所见,小批量minimizers (alpha=0) 比大批量minimizers (alpha=1) 平坦得多,后者的变化更加剧烈。
请注意,这是一种相当简单的锐度测量方法,因为它只考虑一个方向。因此,Keskar 等人提出了一个锐度度量,用于衡量损失函数在最小值附近的邻域内的变化程度。首先,我们定义邻域如下:
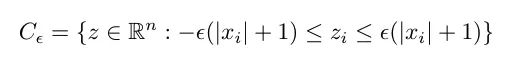
其中 epsilon 是定义邻域大小的参数,x 是最小值(权重)。
然后,我们将锐度度量定义为最小值附近的最大损失:
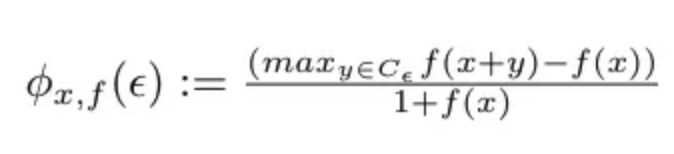
其中 f 是损失函数,输入是权重。
使用上面的定义,让我们计算各种批量大小下的最小化器的锐度,epsilon 值为 1e-3:
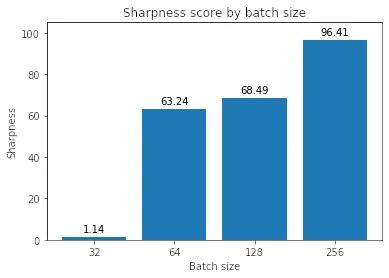
这表明大批量最小化器确实更清晰,正如我们在插值图中看到的那样。
最后,让我们尝试用 Li 等人制定的过滤器归一化损失可视化来绘制最小化器。这种类型的图选择两个与模型权重具有相同维度的随机方向,然后将每个卷积滤波器(或神经元,在 FC 层的情况下)归一化为与模型权重中的相应滤波器具有相同的范数。这确保了最小化器的锐度不受其权重大小的影响。然后,它沿着这两个方向绘制损失,图的中心是我们希望表征的最小值。
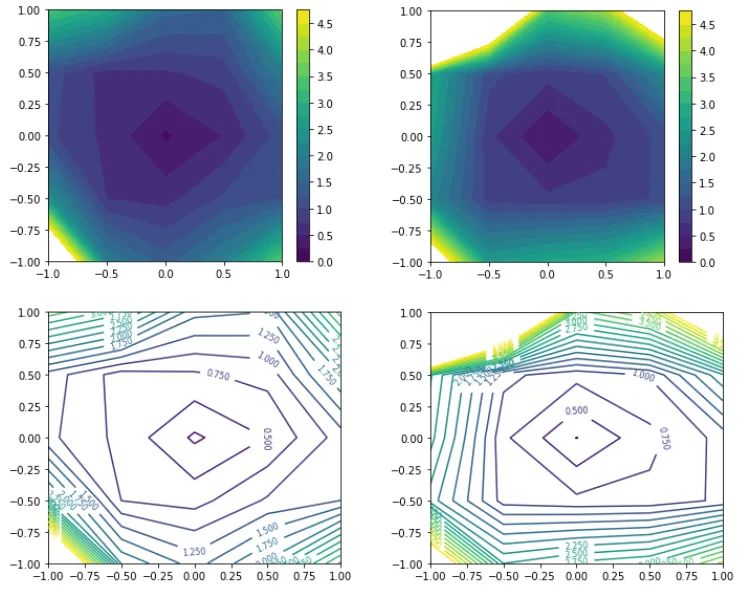
同样,我们可以从等高线图中看到,对于大批量最小化器,损失变化更加剧烈。
通过提高学习率可以提高大批量的性能吗
在假设 1 中,我们看到大批量的更新大小和每个 epoch 的更新频率都较低,而在假设 2 中,我们看到大批量无法探索与小批量一样大的区域。知道了这一点,我们是否可以通过简单地提高学习率来使大批量训练表现更好?
这种方法以前曾被建议过,例如 Goyal 等人提出:“线性缩放规则:当 minibatch 大小乘以 k 时,将学习率乘以 k。”
让我们试试这个,批量大小为 32、64、128 和 256。我们将对批量大小 32 使用 0.01 的基本学习率,并相应地缩放其他批量大小。
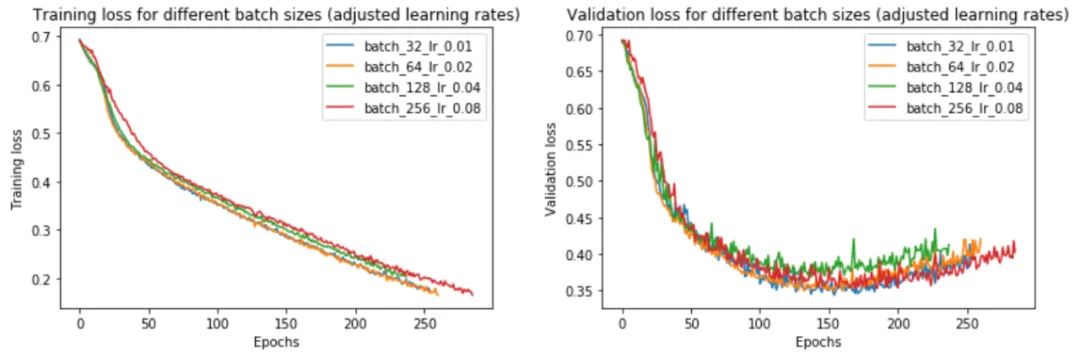

事实上,我们发现调整学习率确实消除了小批量和大批量之间的大部分性能差距。现在,批量大小 256 的验证损失为 0.352 而不是 0.395——更接近批量大小 32 的损失 0.345。
提高学习率如何影响训练时间?由于大批量训练现在可以在与小批量训练大致相同的迭代次数中收敛,如图 25 中的左图所示,现在总体训练时间更短——批量大小 256 为 2197 秒,而批量为 3156 大小为 32。如果我们跨 4 个 GPU 并行化,则加速更加明显。
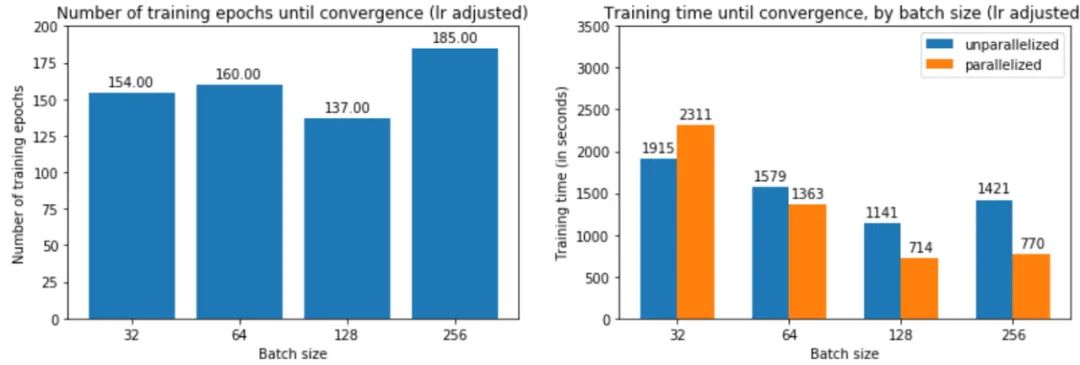
这是否意味着大批量现在正在收敛到平面minimizers?如果我们绘制锐度分数,我们可以看到调整学习率确实使大批量最小化器更平坦:
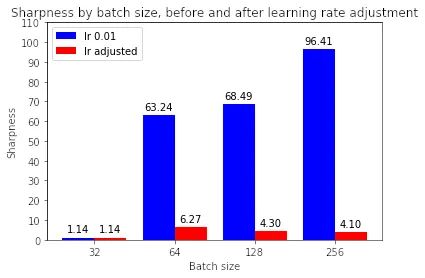
有趣的是,虽然调整学习率使大批量minimizers更平坦,但它们仍然比最小批量最小化器更锐利(4-7 与 1.14 相比)。为什么会这样仍然是未来调查的问题。
较大批量的训练运行现在是否与小批量的初始权重相差甚远?
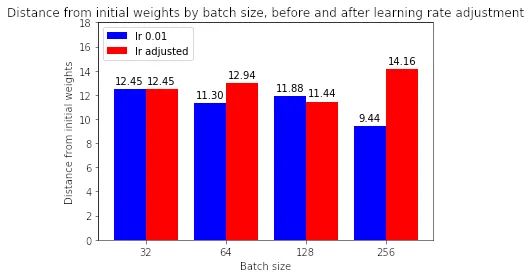
大多数情况下,答案是肯定的。如果我们看上面的图,调整学习率有助于缩小批量大小 32 与其他批量大小之间在与初始权重的距离方面的差距。(请注意,128 似乎是一个异常,其中增加学习率会降低距离——为什么会出现这种情况,有待未来调查。)
小批量训练总是优于大批量训练吗?
鉴于上述观察和文献,如果我们保持学习率不变,我们可能会期望小批量训练总是优于大批量训练。事实上,事实并非如此,正如我们在使用学习率 0.08 时所看到的:
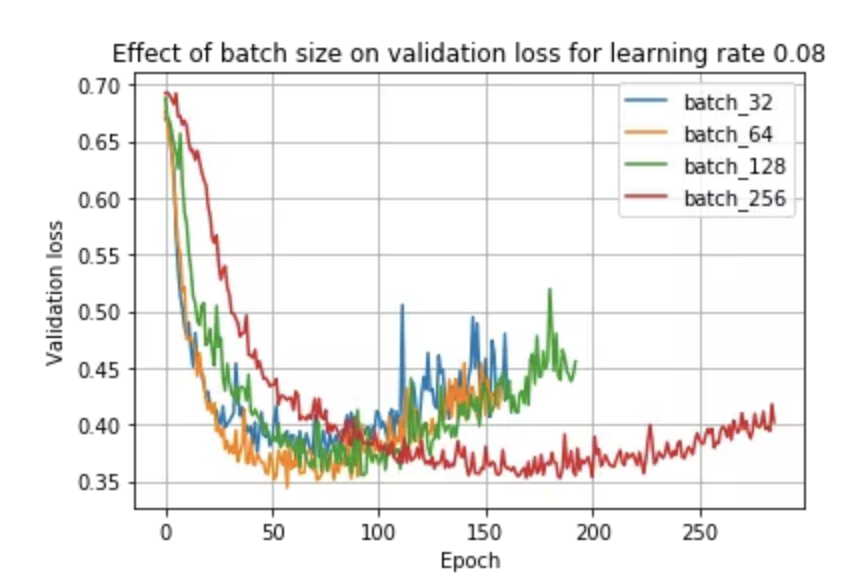
在这里,我们看到批量大小 64 实际上优于批量大小 32!这是因为学习率和批量大小密切相关——小批量在较小的学习率下表现最好,而大批量在较大的学习率下表现最好。我们可以在下面看到这种现象:
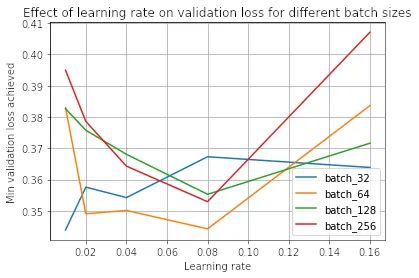
我们看到,0.01 的学习率对于批大小 32 是最好的,而 0.08 对于其他批大小是最好的。
因此,如果您注意到大批量训练在相同学习率下优于小批量训练,这可能表明学习率大于小批量训练的最佳值。
结论
那么,这意味着什么?我们可以从这些实验中得到什么?
线性缩放规则:当 minibatch 大小乘以 k 时,将学习率乘以 k。尽管我们最初发现大批量性能更差,但我们能够通过提高学习率来缩小大部分差距。我们看到这是由于较大的批次大小应用了较小的批次更新,这是由于批次内梯度向量之间的梯度竞争。
选择合适的学习率时,较大的批量尺寸可以更快地训练,特别是在并行化时。对于大批量,我们不受 SGD 更新的顺序性质的限制,因为我们不会遇到与将许多小批量顺序加载到内存中相关的开销。我们还可以跨训练示例并行化计算。
然而,当学习率没有针对较大的批量大小向上调整时,大批量训练可能比小批量训练花费的时间更长,因为它需要更多的训练时期来收敛。因此,您需要调整学习率以实现更大批量和并行化的加速。
大批量,即使调整了学习率,在我们的实验中表现稍差,但需要更多的数据来确定更大的批量是否总体上表现更差。我们仍然观察到最小批量大小(val loss 0.343)和最大批量大小(val loss 0.352)之间的轻微性能差距。一些人认为小批量具有正则化效果,因为它们将噪声引入更新,帮助训练摆脱次优局部最小值的吸引力 。然而,这些实验的结果表明,性能差距相对较小,至少对于这个数据集。这表明,只要您为批量大小找到合适的学习率,您就可以专注于可能对性能产生更大影响的其他方面的训练。
参考论文
Keskar, Nocedal, Mudigere, Smelyanskiy, and Tang. On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima. https://arxiv.org/pdf/1609.04836.pdf Li, Xu, Taylor, Studer, and Goldstein. Visualizing the Loss Landscape of Neural Nets. https://papers.nips.cc/paper/7875-visualizing-the-loss-landscape-of-neural-nets.pdf. Goyal, Dollar, Girshick, Noordhuis, Wesolowski, Kyrola, Tulloch, Jia, and He. Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour. https://research.fb.com/wp-content/uploads/2017/06/imagenet1kin1h5.pdf