Author:louwill
From:深度学习笔记
在本书前三讲中,我们学习了神经网络的基本原理、优化方法和训练算法等基础知识,主要针对的是以BP算法为支撑的深度神经网络。从本讲开始,我们将为大家介绍一种用途更为广泛、性能更加优越的神经网络结构——卷积神经网络(Convolutional Neural Network, CNN)。CNN在图像识别、目标检测和语义分割等多个计算机视觉领域有着广泛的应用。
CNN发展简史与相关人物
早在20个世纪60年代的时候,生物神经学领域的相关研究就表明,生物视觉信息从视网膜传递到大脑是由多个层次的感受野逐层激发完成的。到了20世纪80年代,出现了相应的早期感受野的理论模型。这一阶段是早期的朴素卷积网络理论时期。到了1985年,Rumelhart和Hinton等人提出了BP神经网络,也就是著名的反向传播算法来训练神经网络模型。这基本奠定了神经网络的理论基础,如今大家在谷歌学术上可以看到,提出BP算法的这篇文章的引用次数是24914(这个数字随时都在上升),如图1所示。所以如果你的论文里引用到了BP算法,这个数字还得继续往上涨。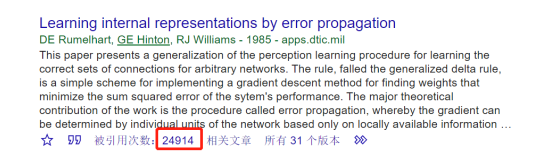
有了此前的理论积累,在 BP算法提出三年之后,如今深度学习三巨头之一的Yann LeCun发现可以用BP算法来训练一种构造出来的多层卷积网络结构,并用其训练出来的卷积网络识别手写数字。在1989年,LeCun正式提出了卷积神经网络的概念。因而,现在我们提到Yann LeCun这个人物时,除了深度学习三巨头之外,还有个名号就是深度学习之父。图2这四位深度学习顶级大咖中最左边这位就是Yann Lecun。
至于图中其他人,咱们也一并介绍了。除了第一位卷积神经网络之父的Yann Lecun之外,第二位就是前面提到的发明反向传播算法之一的Geoffrey Hinton , 第三位则是在RNN和序列模型领域成就颇丰的Yoshua Bengio,这三位便是前面我们所说的深度学习三巨头,是他们支撑起了深度学习的发展。第四位便是我们熟悉的吴恩达(Andrew Ng)。大家若想更多的了解以上深度学习人物的故事,可以参看吴恩达对三位大神的采访,看他们对大家学习机器学习和深度学习是怎样建议的。继续来看CNN的发展历程。LeCun正式提出CNN之后,经过一些年的酝酿,在1998 年提出了CNN的开山之作——LeNet5网络。提出 LeNet5 的这篇论文引用次数已达21444次,如图3所示。
进入新世纪后,由于计算能力不足和可解释性较差等多方面的原因,神经网络的发展经历了短暂的低谷,直到2012年ILSVRC ImageNet图像识别大赛上AlexNet一举夺魁,此后大数据逐渐兴起,以CNN为代表的深度学习方法逐渐成为计算机视觉、语音识别和自然语言处理等领域的主流方法,CNN才真正实现开宗立派。卷积的含义
从前面的学习中,我们了解了深度神经网络的一般结构、前向传播和反向传播机制,而CNN相较于深度神经网络,其主要区别就在于卷积层(Convolutional Layer),卷积层的存在使得神经网络具备更强的学习和特征提取能力。除了卷积层之外,池化层(Pooling Layer)的存在也使得CNN有着更强的稳定性,最后则是DNN中常见的全连接层(Fully Connected Layer)。一个典型的CNN通常包括这三层。CNN的基本结构如图4所示。 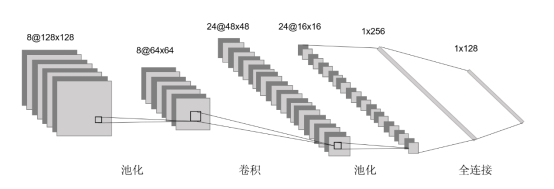
说了半天的CNN,想必很多人还没弄明白:到底什么是卷积?从数学角度来看,卷积可以理解为一种类似于加权运算一样的操作。在图像处理中,针对图像的像素矩阵,卷积操作就是用一个卷积核来逐行逐列的扫描像素矩阵,并与像素矩阵做元素相乘,以此得到新的像素矩阵。这个过程就是卷积。其中卷积核也叫过滤器或者滤波器,滤波器在输入像素矩阵上扫过的面积称之为感受野。这么说可能过于概念化,我们以一个具体的例子来看卷积操作,如图4.5所示。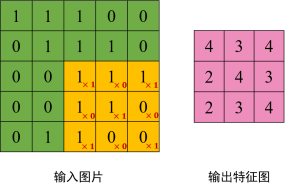
图5中我们用一个3*3的滤波器去扫描一个5*5的像素矩阵,用滤波器中每一个元素与像素矩阵中感受野内的元素进行乘积运算,可得到了一个3*3的输出像素矩阵,这个输出的3*3像素矩阵能够较大程度的提取原始像素矩阵的图像特征,这也是卷积神经网络之所以有效的原因。我们以输出像素矩阵中第一个元素4为例,演示一下计算过程:1*1 + 1*0 + 1*1 + 1*0 + 1*1 + 0*0 + 1*1 + 0*0 + 0*1 = 4这里你可能会问:如何确定经过卷积后的输出矩阵的维度?我们是有计算公式的。假设原始输入像素矩阵的shape为n*n,滤波器的shape为f*f,那么输出像素矩阵的shape为(n-f+1)*(n-f+1) 。例如,3*3的滤波器去扫描一个5*5的输入图像,按照公式计算的话输出就是 (5-3+1)*(5-3+1)=3*3。在训练卷积网络时,我们需要初始化滤波器中的卷积参数,在训练中不断迭代得到最好的滤波器参数。大体上卷积操作就是这么个过程,看起来十分简单。这也是目前大多数深度学习教程对于卷积的阐述方式。让我们来深究一下,究竟卷积为什么要这么设计,背后有没有什么数学和物理意义呢?追本溯源,我们先回到数学教科书中来看卷积。在泛函分析中,卷积也叫旋积或者褶积,是一种通过两个函数x(t)和h(t)生成的数学算子。其计算公式如下: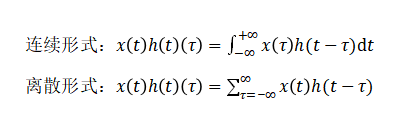
公式写的很清楚了,两个函数的卷积就是先将一个函数进行翻转(Reverse),然后再做一个平移(Shift),这便是“卷”的含义。而“积”就是将平移后的两个函数对应元素相乘求和。所以卷积本质上就是一个Reverse-Shift-Weighted Summation(翻转平移加权求和)的操作。那么为什么要卷积?直接元素相乘不好吗?就图像的卷积操作而言,卷积能够更好提取区域特征,使用不同大小的卷积算子能够提取图像各个尺度的特征。卷积这么设计的原因也正在于此。接着前面的卷积图像处理操作,这里我们需要注意两个问题:第一个就是滤波器移动的步幅问题,上面的例子中我们的滤波器的移动步长为1,即在像素矩阵上一格一格平移。但如果滤波器是以两个单位或者更多单位平移呢?这里就涉及卷积过程中的Stride问题。第二个问题涉及卷积操作的两个缺点 ,第一个缺点在于每次做卷积,你的图像就会变小,可能做了几次卷积之后,你的图像就变成1*1,这就不好办了。第二个缺点在于原始输入像素矩阵的边缘和角落的像素点只能被滤波器扫到一次,而靠近像素中心点的像素点则会被多次扫到进行卷积。这就使得边缘和角落里的像素特征提取不足,这就涉及卷积过程中的 Padding问题。针对第一个问题,也就是卷积步长问题,其实也很简单,就是按照正常的卷积过程去操作,只不过每次要多走一个像素单位。且看卷积步幅为2的卷积操作示例,如图6所示。 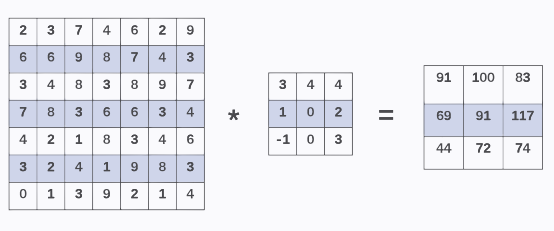
我们用一个3*3的滤波器去对原始像素为7*7的图像进行卷积操作,设定卷积步长为 2,可看到输出像素矩阵的第二行第一个元素69的计算跨越了两个像素格点,计算过程为:3*3 + 4*4 + 8*4 + 7*1 + 8*0 + 3*2 + 4*-1 + 2*0 + 1*3 = 69加入步长之后我们的输出像素矩阵的shape的计算公式需要更新为:,其中为步长。针对第二个问题,卷积神经网络采用一种叫作Padding的操作,即对原始像素边缘和角落进行零填充,以期能够在卷积过程中充分利用边缘和角落的像素特征。至于填充多少 0 像素值,一般有两个选择,一是Valid填充,也就是不填充,所以就不用管它了。我们在意的是有填充,就是第二种,Same填充方法,即填充后,输入和输出大小是一致的,对于n*n大小的输入像素,如果你用填充了p个像素点之后,就变成了n+2p,最后输出像素的shape 计算公式就变成了((n+2p-f)/s)+1,要想让的((n+2p-f)/s)+1=n话,输入输出大小相等,则p=(f-1)/2。所以,正常情况下滤波器f的大小都会选择为奇数个。以上便是CNN中卷积的基本过程描述。一个完整的卷积神经网络除了最重要的卷积层之外,还有池化层和全连接层。池化和全连接
通常在设计卷积网络结构时,卷积层后会跟着一个池化层。池化(Pooling)的操作类似于卷积,只是将滤波器与感受野之间的元素相乘改成了对感受野直接进行最大采样。简单来说,池化层是用来缩减模型大小,提高模型计算速度以及提高所提取特征的鲁棒性。池化操作通常有两种,一种是常用的最大池化(Max Pooling),另一种是不常用的平均池化(Average Pooling)。池化操作过程也非常简单,假设池化层的输入为一个4*4的图像,我们用最大池化对其进行池化,执行最大池化的树池是一个2*2的矩阵,执行过程就是将输入矩阵拆分为不同区域,对于2*2 的输出而言,输出的每个元素都是其对应区域的最大元素值。最大池化如图7所示。 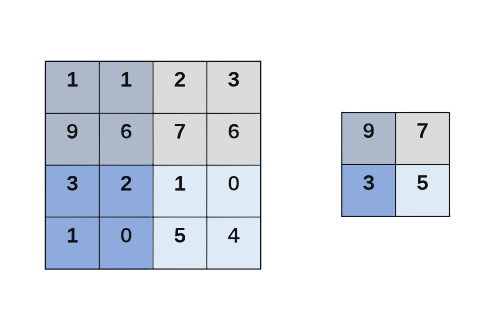
最大池化过程就像是应用了一个2*2的滤波器以步幅2进行区域最大化输出操作。我们可以这么理解:池化的参数就是滤波器的大小和步幅,池化的效果就相当于对输入图像的高度和宽度进行缩小。值得注意的是,最大池化只是计算神经网络某一层的静态属性,中间并没有什么学习过程。池化完成之后就是标准神经网络中的全连接层了。全连接层我们在本书前三讲深度神经网络中有详细描述,在此就不再赘述。总之,一个典型的卷积层通常包括卷积层-池化层和全连接层。例如,Yann LeCun在1998年提出的LeNet5网络结构就是最初的卷积网络结构。LeNet5网络结构如图8所示。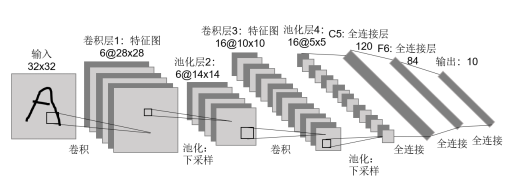
CNN发展到如今,人们早已不满足常规的卷积方式设计,除此之外,针对3维图像的3D卷积、在图像分割中应用广泛的转置卷积、GoogLeNet中常用的1*1卷积、基于1*1卷积的深度可分离卷积、为扩大感受野而设计的空洞卷积等各种花式卷积方式不断地出现在各种CNN结构设计中,感兴趣的读者可以逐一深入了解。本讲在介绍卷积神经网络发展历程的基础上,对卷积的基本过程进行了详细的描述,之后又介绍了池化和全连接卷积神经网络的另外两大组成部分。一个典型的卷积网络结构设计通常包括卷积层、池化层和全连接层三个部分。在下一讲中,我们将和大家继续深入讨论卷积神经网络的结构、训练等更加深入的内容。往期精彩:
【原创首发】机器学习公式推导与代码实现30讲.pdf
【原创首发】深度学习语义分割理论与实战指南.pdf

喜欢您就点个在看!
 下载APP
下载APP