
超详细的语义分割中的Loss大盘点

极市导读
作为一篇超详细的大盘点,本文介绍了超过十种语义分割的常见Loss及组合。大部分介绍附有代码实现,帮助大家掌握新的损失函数并进行应用。>>>极市七夕粉丝福利活动:炼丹师们,七夕这道算法题,你会解吗?
前言
交叉熵Loss
one-hot向量,元素只有和两种取值,如果该类别和样本的类别相同就取,否则取,至于表示预测样本属于的概率。#二值交叉熵,这里输入要经过sigmoid处理import torchimport torch.nn as nnimport torch.nn.functional as Fnn.BCELoss(F.sigmoid(input), target)#多分类交叉熵, 用这个 loss 前面不需要加 Softmax 层nn.CrossEntropyLoss(input, target)
带权交叉熵Loss
Focal Loss
10k数量级的框,但只有极少数是正样本,正负样本数量非常不平衡。我们在计算分类的时候常用的损失——交叉熵的公式如下: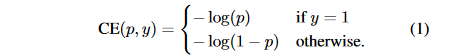
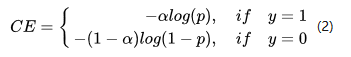
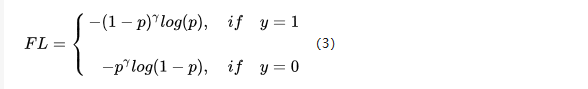
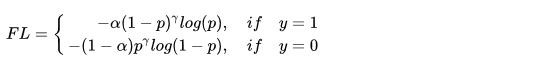
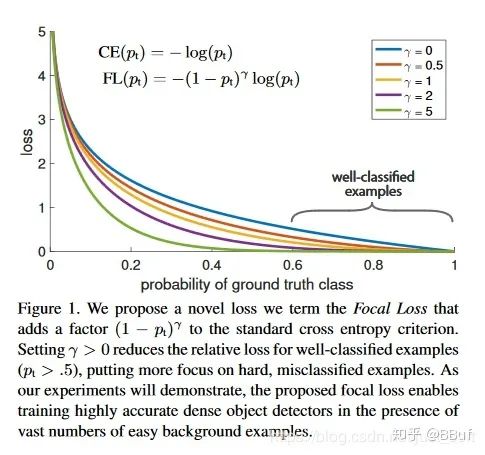
class FocalLoss(nn.Module):def __init__(self, gamma=0, alpha=None, size_average=True):super(FocalLoss, self).__init__()self.gamma = gammaself.alpha = alphaif isinstance(alpha,(float,int,long)): self.alpha = torch.Tensor([alpha,1-alpha])if isinstance(alpha,list): self.alpha = torch.Tensor(alpha)self.size_average = size_averagedef forward(self, input, target):if input.dim()>2:input = input.view(input.size(0),input.size(1),-1) # N,C,H,W => N,C,H*Winput = input.transpose(1,2) # N,C,H*W => N,H*W,Cinput = input.contiguous().view(-1,input.size(2)) # N,H*W,C => N*H*W,Ctarget = target.view(-1,1)logpt = F.log_softmax(input)logpt = logpt.gather(1,target)logpt = logpt.view(-1)pt = Variable(logpt.data.exp())if self.alpha is not None:if self.alpha.type()!=input.data.type():self.alpha = self.alpha.type_as(input.data)at = self.alpha.gather(0,target.data.view(-1))logpt = logpt * Variable(at)loss = -1 * (1-pt)**self.gamma * logptif self.size_average: return loss.mean()else: return loss.sum()
Dice Loss
Dice系数:根据 Lee Raymond Dice[1]命令,是用来度量集合相似度的度量函数,通常用于计算两个样本之间的像素,公式如下: 分子中之所以有一个系数2是因为分母中有重复计算和的原因,最后的取值范围是。而针对我们的分割任务来说,表示的就是Ground Truth分割图像,而Y代表的就是预测的分割图像。这里可能需要再讲一下,其实除了上面那种形式还可以写成: 其中分别代表真阳性,假阳性,假阴性的像素个数。
Dice Loss:公式定义为 : Dice Loss使用与样本极度不均衡的情况,如果一般情况下使用Dice Loss会回反向传播有不利的影响,使得训练不稳定。
训练分割网络,例如FCN,UNet是选择交叉熵Loss还是选择Dice Loss?
代码实现:
import torch.nn as nnimport torch.nn.functional as Fclass SoftDiceLoss(nn.Module):def __init__(self, weight=None, size_average=True):super(SoftDiceLoss, self).__init__()def forward(self, logits, targets):num = targets.size(0)// 为了防止除0的发生smooth = 1probs = F.sigmoid(logits)m1 = probs.view(num, -1)m2 = targets.view(num, -1)intersection = (m1 * m2)score = 2. * (intersection.sum(1) + smooth) / (m1.sum(1) + m2.sum(1) + smooth)score = 1 - score.sum() / numreturn score
IOU Loss
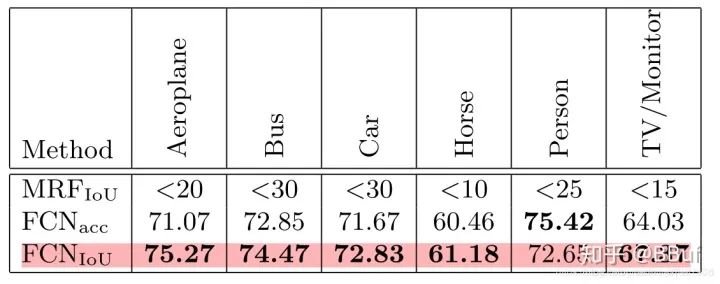
Person类却性能反而下降了。Tversky Loss
https://arxiv.org/pdf/1706.05721.pdf。实际上Dice Loss只是Tversky loss的一种特殊形式而已,我们先来看一下Tversky系数的定义,它是Dice系数和Jaccard系数(就是IOU系数,即)的广义系数,公式为: 这里A表示预测值而B表示真实值。当和均为的时候,这个公式就是Dice系数,当和均为的时候,这个公式就是Jaccard系数。其中代表FP(假阳性),代表FN(假阴性),通过调整和这两个超参数可以控制这两者之间的权衡,进而影响召回率等指标。下表展示了对FCN使用Tversky Loss进行病灶分割,并且取不同的和参数获得的结果,其中Sensitivity代表召回率Recall,而Specificity表示准确率Precision: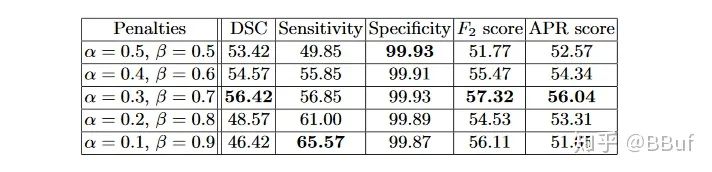
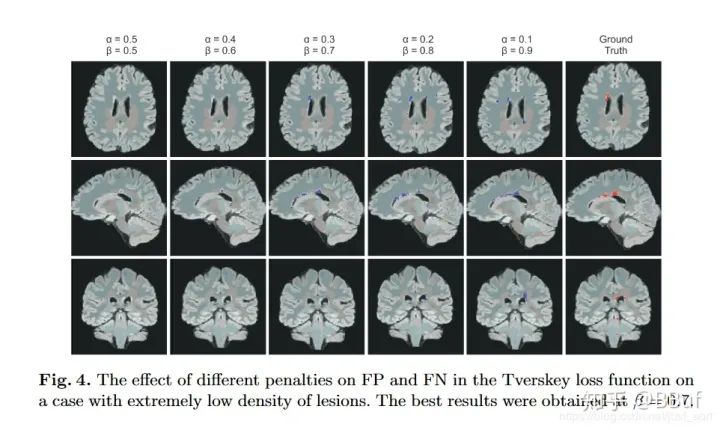

def tversky(y_true, y_pred):y_true_pos = K.flatten(y_true)y_pred_pos = K.flatten(y_pred)true_pos = K.sum(y_true_pos * y_pred_pos)false_neg = K.sum(y_true_pos * (1-y_pred_pos))false_pos = K.sum((1-y_true_pos)*y_pred_pos)alpha = 0.7return (true_pos + smooth)/(true_pos + alpha*false_neg + (1-alpha)*false_pos + smooth)def tversky_loss(y_true, y_pred):return 1 - tversky(y_true,y_pred)
Generalized Dice loss
Generalized Overlap Measures for Evaluation and Validation in Medical Image Analysis 刚才分析过Dice Loss对小目标的预测是十分不利的,因为一旦小目标有部分像素预测错误,就可能会引起Dice系数大幅度波动,导致梯度变化大训练不稳定。另外从上面的代码实现可以发现,Dice Loss针对的是某一个特定类别的分割的损失。当类似于病灶分割有多个场景的时候一般都会使用多个Dice Loss,所以Generalized Dice loss就是将多个类别的Dice Loss进行整合,使用一个指标作为分割结果的量化指标。GDL Loss在类别数为2时公式如下: 其中表示类别在第个位置的真实像素类别,而表示相应的预测概率值,表示每个类别的权重。的公式为:。def generalized_dice_coeff(y_true, y_pred):Ncl = y_pred.shape[-1]w = K.zeros(shape=(Ncl,))w = K.sum(y_true, axis=(0,1,2))w = 1/(w**2+0.000001)# Compute gen dice coef:numerator = y_true*y_prednumerator = w*K.sum(numerator,(0,1,2,3))numerator = K.sum(numerator)denominator = y_true+y_preddenominator = w*K.sum(denominator,(0,1,2,3))denominator = K.sum(denominator)gen_dice_coef = 2*numerator/denominatorreturn gen_dice_coefdef generalized_dice_loss(y_true, y_pred):return 1 - generalized_dice_coeff(y_true, y_pred)
BCE + Dice Loss
Focal Loss + Dice Loss
https://arxiv.org/pdf/1808.05238.pdf。论文提出了使用Focal Loss和Dice Loss来处理小器官的分割问题。公式如下: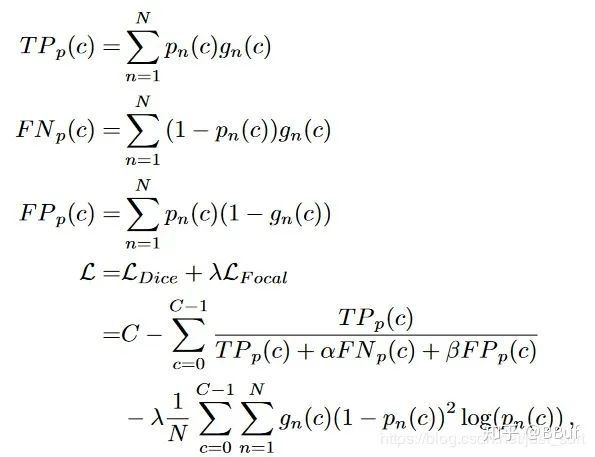
c的真阳性,假阴性,假阳性。可以看到这里使用Focal Loss的时候,里面的两个参数直接用对于类别c的正样本像素个数来代替。具体实验细节和效果可以去看看原论文。Exponential Logarithmic loss
3D Segmentation with Exponential LogarithmicLoss for Highly Unbalanced Object Sizes提出来的,论文地址为:https://arxiv.org/abs/1809.00076。这个Loss结合了Focal Loss以及Dice loss。公式如下: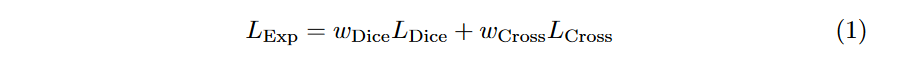
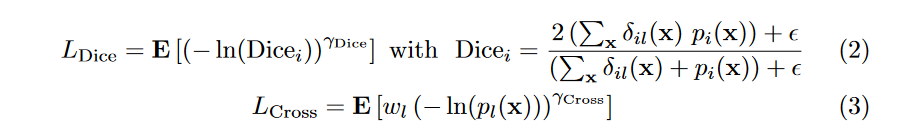
softmax操作之后的概率值。其中: 其中表示标签出现的频率,这个参数可以减小出现频率较高的类别权重。和可以提升函数的非线性,如Figure2所示: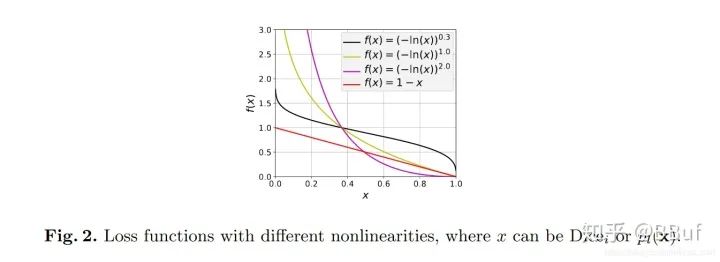
Lovasz-Softmax Loss
https://arxiv.org/pdf/1705.08790.pdf。对原理感兴趣可以去看一下论文,这个损失是对Jaccard(IOU) Loss进行Lovaze扩展,表现更好。因为这篇文章的目的只是简单盘点一下,就不再仔细介绍这个Loss了。之后可能会单独介绍一下这个Loss,论文的官方源码见附录,使用其实不是太难。补充(Softmax梯度计算)
c'=0(c为常数)(x^a)'=ax^(a-1),a为常数且a≠0(a^x)'=a^xlna(e^x)'=e^x(logax)'=1/(xlna),a>0且 a≠1(lnx)'=1/x(sinx)'=cosx(cosx)'=-sinx(tanx)'=(secx)^2(secx)'=secxtanx(cotx)'=-(cscx)^2(cscx)'=-csxcotx(arcsinx)'=1/√(1-x^2)(arccosx)'=-1/√(1-x^2)(arctanx)'=1/(1+x^2)(arccotx)'=-1/(1+x^2)(shx)'=chx(chx)'=shx(uv)'=uv'+u'v(u+v)'=u'+v'(u/)'=(u'v-uv')/^2
如果, 如果,。
#coding=utf-8import numpy as npdef softmax_loss_native(W, X, y, reg):'''Softmax_loss的暴力实现,利用了for循环输入的维度是D,有C个分类类别,并且我们在有N个例子的batch上进行操作输入:- W: 一个numpy array,形状是(D, C),代表权重- X: 一个形状为(N, D)为numpy array,代表输入数据- y: 一个形状为(N,)的numpy array,代表类别标签- reg: (float)正则化参数f返回:- 一个浮点数代表Loss- 和W形状一样的梯度'''loss = 0.0dW = np.zeros_like(W) #dW代表W反向传播的梯度num_classes = W.shape[1]num_train = X.shape[0]for i in xrange(num_train):scores = X[i].dot(W)shift_scores = scores - max(scores) #防止数值不稳定loss_i = -shift_scores[y[i]] + np.log(sum(np.exp(shift_scores)))loss += loss_ifor j in xrange(num_classes):softmax_output = np.exp(shift_scores[j]) / sum(np.exp(shift_scores))if j == y[i]:dW[:, j] += (-1 + softmax_output) * X[i]else:dW[:, j] += softmax_output * X[i]loss /= num_trainloss += 0.5 * reg * np.sum(W * W)dW = dW / num_train + reg * Wreturn loss, dWdef softmax_loss_vectorized(W, X, y, reg):loss = 0.0dW = np.zeros_like(W)num_class = W.shape[1]num_train = X.shape[0]scores = X.dot(W)shift_scores = scores - np.max(scores, axis=1).reshape(-1, 1)softmax_output = np.exp(shift_scores) / np.sum(np.exp(shift_scores), axis=1).reshape(-1, 1)loss = -np.sum(np.log(softmax_output[range(num_train), list(y)]))loss /= num_trainloss += 0.5 * reg * np.sum(W * W)dS = softmax_output.copy()dS[range(num_train), list(y)] += -1dW = (x.T).dot(dS)dW = dW/num_train + reg*Wreturn loss, dW
总结
附录
推荐阅读

评论