
从头来看关系抽取-远程监督来袭



从早期到现在来看关系抽取任务的话,基本的做法包括基于规则匹配、监督学习、半监督学习、无监督学习以及远程监督学习等方法,上篇文章《从头来看关系抽取》已经介绍了监督学习早期的一些开山之作,而今天的主人公是远程监督来做关系抽取,那么为什么要引入远程监督的方法,什么是远程监督的方法,基于远程监督的关系抽取的方法从古至今是怎么演变发展的,带着这些疑问,我们简单了解一下。
为什么要引入远程监督方法?
监督学习
监督学习是利用标注好的训练数据,传统的机器学习模型或者是深度学习算法构建网络模型,老生常谈的问题,这种方法的问题在于虽然能够利用标注质量高的数据获取很好的效果,但是获取高质量的标注数据需要花费昂贵的人力、物力,因此引出很多其他的学习方式,比如半监督、无监督、远程监督、迁移学习等等。
半监督学习
半监督学习是解决获取大量高质量标注数据难问题的一种解决方式,利用少部分高质量标注数据,通过相关算法学习,常用的是Bootstrapping learning 以及远程监督方法。对于关系抽取任务来说,Bootstrapping 算法的输入少量实体关系数据作为种子,找到更多有某种关系的相关数据。但是我们可以想到一个问题就是利用少量的种子数据在大规模数据中搜寻出来的结果,是否是我们真正想要的,会不会存歧义的数据,毕竟利用一点种子就想达到我们的目标,肯定是存在某些问题的,这也是 Bootstraping 算法的语义漂移问题。
远程监督学习
远程监督学习很早之前就被提出来了,但是应用在关系抽取任务上面应该是2009年的一篇论文,作为远程监督学习在关系抽取的开山之作,下面会介绍这个工作。简单来说,远程监督关系抽取是通过将大规模非结构化文本中的语料与知识库对齐,这样便可以获取大量训练数据供模型训练。远程监督关系抽取的工作可以分为两阶段,其中后期以及目前的发展都集中在神经网络提取特征信息结合多实例学习思想。
开山燎原-2009-ACL
论文题目:Distant supervision for relation extraction without labeled data 论文地址:https://www.aclweb.org/anthology/P09-1113.pdf 这篇文章应该是最早的将远程监督学习用于关系抽取,是一篇开山之作。
文中提出了一个强有力的假设:如果两个实体在已知知识库中存在,并且两者有相对应的某种关系,那么当这两个实体在其他非结构化文本中存在的时候也能够表达这种关系。基于这种强有力的假设,远程监督算法可以利用已有的知识库,给外部非结构化文本中的句子标注某种关系标签,相当于自动语料标注,能够获取大量的标注数据供模型训练。
训练阶段
文中所采用的知识库为Freebase,非结构化文本采用的是维基百科等数据。既然是要判定句子中的实体是否在知识库中存在,那么必然要识别出对应的实体,识别实体部分文中依赖NER标注工具。如果句子中的两个实体存在于知识库中且具有某种关系,便从句子中抽取出特征(很多特征),并把具有这种关系的多个句子中特征拼接作为这个关系的某一特征向量,从不同的句子中抽取出的特征拼接,会让后面的分类器获取更多的信息。
特征
训练的分类器需要很多的特征,2009年的时候还在大量的构造特征工程,因此构造的也正也几乎完全是词典或者语法特征,主要包括以下:
Lexical features
1、The sequence of words between the two entities
2、The part-of-speech tags of these words
3、A flag indicating which entity came first in the sentence
4、A window of k words to the left of Entity 1 and their part-of-speech tags
5、A window of k words to the right of Entity 2 and their part-of-speech tags
另外还有关系依存句法树以及实体类别特征等。
测试阶段
在测试阶段中,将再次使用NER工具识别实体,句子中一起出现的每一对实体都被认为是一个潜在的关系实例,当这些实体同时出现便从句子中提取特征添加到该实体对的特征向量中。例如在测试集中10个句子中出现了一对实体,每个句子提取3个特征,那么这个实体对将有30个相关特征,对测试语料库中每个句子的每个实体对进行特征提取,分类器根据实体对出现的所有特征为每个实体对预测关系。
问题
1、文中提出的假设太过强横,必然会出现大量的badcase,比如句子中出现的两个实体刻画的并非实体库中对应的关系描述,这样会引入噪音脏数据,影响最终的结果。例如,创始人(乔布斯,苹果)和ceo(乔布斯,苹果)都是正确的。
2、文中依赖于NER工具、以及构造词典语法句法等特征,也会存在错误传播问题。
多实例学习-2011-ACL
论文题目:Knowledge-Based Weak Supervision for Information Extraction of Overlapping Relations 论文地址:https://www.aclweb.org/anthology/P11-1055.pdf
本文针对上篇文章中的强假设导致的badcase,采用多实例学习的思想,减少远程监督噪音数据的影响。提出新的模型MULTIR,引入多实例学习的概率图形模型,从而解决重叠关系抽取问题,重叠关系问题指的是同一对实体之间的存在多种不同类型的关系,同时结合句子级别和文档级别的特征进行关系抽取,MULTIR在计算推理上面具有很高的效率。
多实例学习可以被描述为:假设训练数据集中的每个数据是一个包(Bag),每个包都是一个示例(instance)的集合,每个包都有一个训练标记,而包中的示例是没有标记的;如果包中至少存在一个正标记的示例,则包被赋予正标记;而对于一个有负标记的包,其中所有的示例均为负标记。(这里说包中的示例没有标记,而后面又说包中至少存在一个正标记的示例时包为正标记包,是相对训练而言的,也就是说训练的时候是没有给示例标记的,只是给了包的标记,但是示例的标记是确实存在的,存在正负示例来判断正负类别)。通过定义可以看出,与监督学习相比,多示例学习数据集中的样本示例的标记是未知的,而监督学习的训练样本集中,每个示例都有一个一已知的标记;与非监督学习相比,多示例学习仅仅只有包的标记是已知的,而非监督学习样本所有示例均没有标记。但是多示例学习有个特点就是它广泛存在真实的世界中,潜在的应用前景非常大。from http://blog.csdn.net/tkingreturn/article/details/39959931
经典-2015-EMNLP
论文题目:Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks 论文地址:https://www.aclweb.org/anthology/D15-1203.pdf
上面的几篇文章已经提出了远程监督学习在关系抽取的开山之作,以及后面会通过多实例学习(Multi Instance Learning, MIL)来减少其中的噪音数据,这篇文章也是在前人的基础之上去做的工作,主要有两部分,其中之一是提出piece-wise卷积神经网络自动抽取句子中的特征信息,从而替换之前设计的特征工程;另外和之前一样,采用多实例学习思想来减缓错误的badcase数据,既这篇文章将多实例学习整合到卷积神经网络中来完成关系抽取任务。
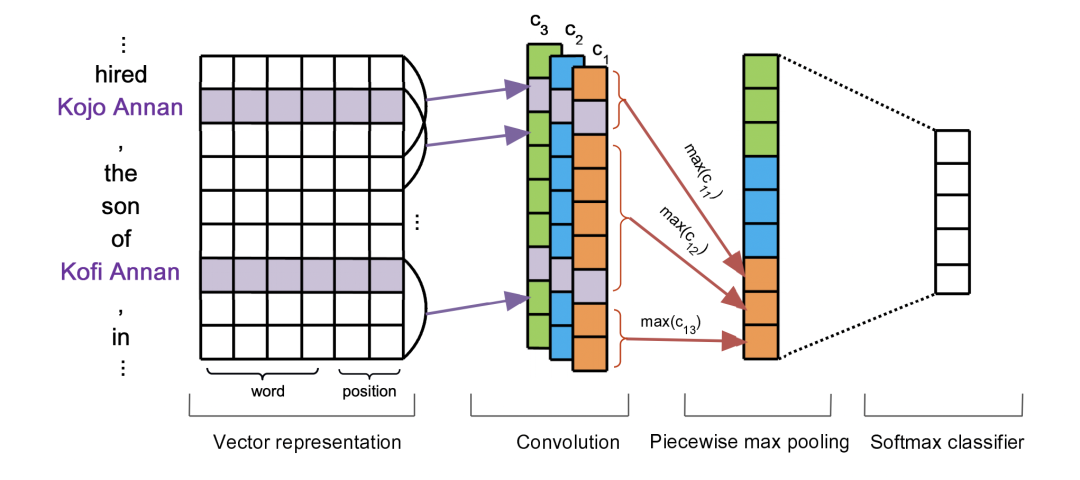
Piecewise-CNN
Vector representation
上图是PCNN针对bags中的一个句子编码的情况,主要分为几部分,其中向量表示部分也和之前我们介绍过的几篇一样,采用的预训练的word embedding以及句子中词和两个实体之间的相对距离向量,下图中再对这个解释一下,图中 son 对两个实体的相对距离分为是-2和3,到时候会把这些均转换为向量表示,采用随机初始化的方式。

Convolution
卷积部分从图中便可以看出采用的是多卷积核操作,文中的Zero Padding值为1 , 卷积核的长为向量矩阵的长,宽为3,从上到下,单向滑动。
Piecewise max pooling
这部分也是之前介绍过的一篇论文中的类似做法,根据实体的位置将句子分为左中右三部分,对左中右三部分分别max-pooling,最后将所有的结果拼接,过softmax层,图中的一个细节就是分段pooling的时候并没有丢失两个实体,而是将两个实体划分在在左中两段中,这是一个细节,图中也很明显给画出来了。
MIL-PCNN
上面的PCNN网络结构展示的是多实例学习中一个bag(包)中的一个instance(句子)的情况,而多实例学习的输入到网络中的是一个包,里面包含了很多句子。假设我们存在 个bags {},每个bag包含个句子 。多实例学习的目的是预测看不见的袋子的标签。在本文中,bag中的所有实例都是独立考虑的,并且bag中的instance是没有label的,只有bag中才有label,因此只需要关注bag的label即可。
模型图中经过softmax得到的是bag中的一个instance的关系类别概率,而非bag的,因此重新定义了基于bag的损失函数,文中采取的措施是At-Least-One的假设,每个bag中至少有一个标注正确的instance,这样就可以找到bag中置信度得分最高的instance,代表当前bag的结果。定义如下的目标函数
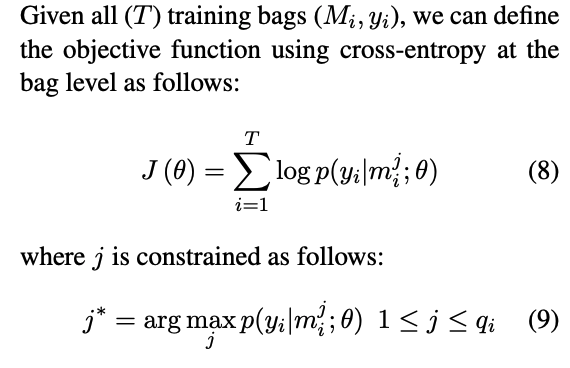
2016-ACL
论文题目:Neural Relation Extraction with Selective Attention over Instances 论文地址:https://www.aclweb.org/anthology/P16-1200.pdf
这篇文章是在上一篇文章PCNN的基础之上进行的改进,主要是因为PCNN在多实例学习部分采用的是选取bag中置信度最高的instance(句子)作为bag的标签,这样的做法可能会丢失太多的信息,因为一个bag中正负样本的数量是不定的,可能存在多个正样本或者多个负样本。这篇文章为了充分利用bag中的所有instance信息,利用注意力机制充分利用instance信息,减弱噪音的影响。模型的整体结构如下图。
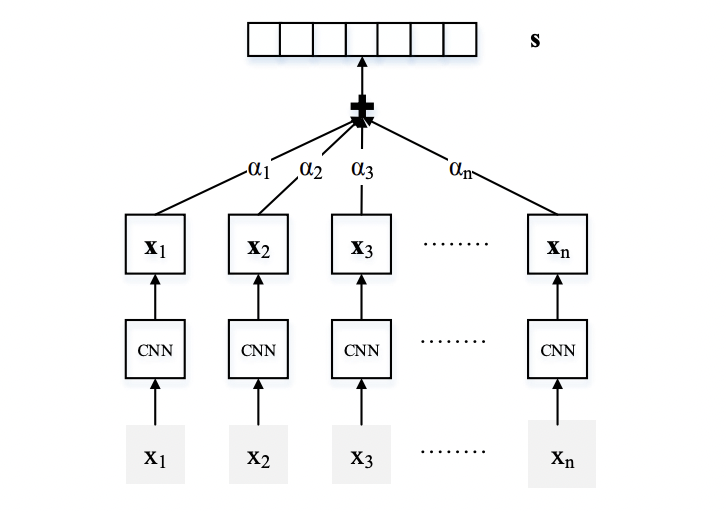
模型的整体结构也是分为两大部分
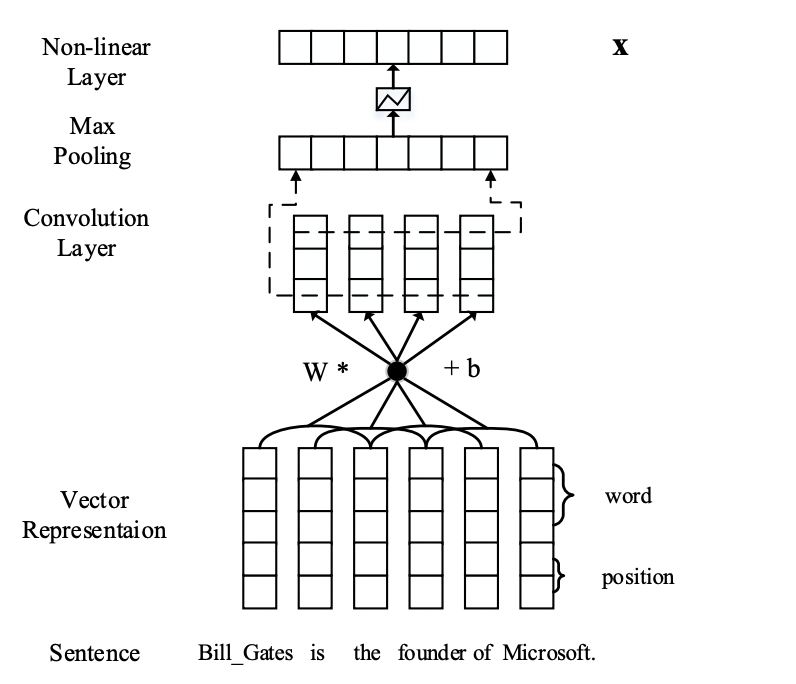
Sentence Encoder:句子编码部分采用的方式和上文的PCNN一样,包括输入部分的词向量和位置向量,卷积神经网络,以及分段max-pooling,这部分的方式没有区别,这部分的模型结构如下图所示。
Selective Attention over Instances:这部分是文章的重点,改进的地方主要是在这里,利用注意力机制对bag中的instance进行加权,得到bag的最终向量表示,,其中 是权重,文中具体的有两种计算权重的方式。
Average: 将bag中所有instance的重要程度都等同看待,即,这会放大instance的噪音影响,文中将其作为对比实验的一个baseline。
Selective Attention: 这部分attention的目的是加强正样本的instance、弱化负样本instance的噪音影响。具体的计算公式见下面,其中 代表的是句子句子和关系 的相关程度, 为attention的对角矩阵,这样就可以得到加权后的bag向量表示 。
2016-COLING
论文题目:Relation Extraction with Multi-instance Multi-label Convolutional Neural Networks 论文地址:https://www.aclweb.org/anthology/C16-1139.pdf
这篇文章也是在PCNN的基础之上进行的改进,主要有两方面,其一也是和上文一样认为PCNN的at-least-once假设太过强硬,应该充分利用bag中的所有instance信息,另外是评估了数据集中存在18.3%的重叠关系数据,因此之前的单标签是不合理的,所以这篇文章针对这两部分进行了改进,模型的整体结构如下图。
Sentence-level Feature Extraction:这部分和之前的PCNN一样,Embedding (word + position) -> CNN -> 分段最大池化获取每一个instance的句子表示。
Cross-sentence Max-pooling:这篇文章融合bag中所有instance信息的方法和上文不一样,不是采用的注意力机制,而是采用了非常简单直观或者说粗暴的方式,将bag中每个instance的句子信息取每一维度的最大值,获取bag的向量表示,就如图中中间部分所示。
Multi-label Relation Modeling:之前的方式都是采用softmax多标签分类的方式,而这篇文章为了解决重叠关系问题,将不在采用softmax,而是对每一个 relation 做 sigmoid ,然后根据阈值来判定该instance是否应该包含这个 relation 。
2017-AAAI
论文题目:Distant Supervision for Relation Extraction with Sentence-Level Attention and Entity Descriptions 论文地址:https://www.aaai.org/ocs/index.php/AAAI/AAAI17/paper/download/14491/14078
这篇文章的关键点主要也是两部分,其一也是考虑了at-least-once的假设太多强硬,需要采用注意力机制考虑bag中更多的instance信息,另外一个是之前的方法都过多关注实体本身,而忽略了实体背后的文本描述信息,因此,这篇文章的将实体链接到实体描述文本上面获取很多的信息表达,文章的主要结构如下。
主要包括三部分
(a) PCNNs Module:这部分还是和之前一样,完全延续了 PCNN 的模型结构,采用word + position -> CNN -> Piecewise Max-pooling获取文中的 bag 中的句子信息表达。
(b) Sentence-level Attention Module:这部分类似之前的 Selective Attention ,也是计算 bag 中每个 instance 与 relation 的相关性,这里关系的向量采用的是 两个实体信息来表达,然后计算相关的权重(如下),最后通过加权的方式获取 bag 的向量表达,然后过线性层和softmax层做多分类,没有考虑重叠关系。
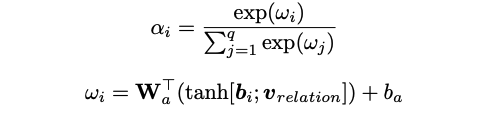
Entity Descriptions:这部分是将实体的文本描述信息编码,采用的是简单的CNN + max-pooling 获取实体描述文本的向量表达,文中提出,为了尽可能使实体的向量表达与实体描述文本的向量表达在语义空间中接近,直接定义了一个距离公式计算loss, ,然后和上面判别关系的loss结合, ,两个损失函数联合训练。

2018-EMNLP
论文题目:Hierarchical Relation Extraction with Coarse-to-Fine Grained Attention 论文地址:https://www.aclweb.org/anthology/D18-1247.pdf
这篇文章主要考虑到之前的关系抽取方法中,没有考虑到关系之间是存在语义依赖关系的,而且,知识库的关系中很多都是带有层级结构的,另外,之前的方法没有对关系的长尾分布问题进行仔细的考量,易导致关系数量多的则准确率更高,关系数量极少的准确率堪忧,针对上面的问题,这篇文章提出了在多实例学习中采用注意力机制的思想,提出层次化注意力机制来做具有层级的关系抽取问题,而且对于长尾分布的关系抽取也有很明显的改善。
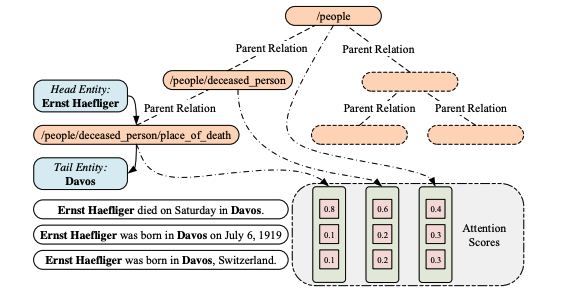
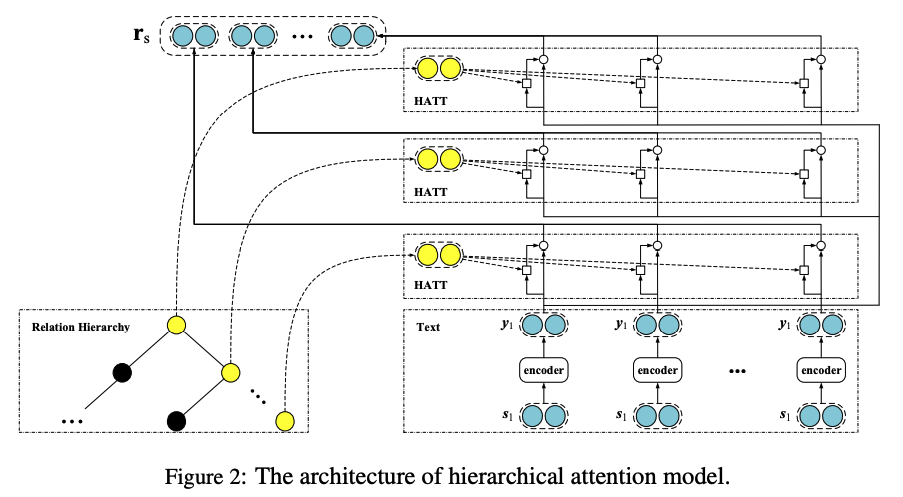
2018-EMNLP
论文题目:RESIDE: Improving Distantly-Supervised Neural Relation Extraction using Side Information 论文地址:https://www.aclweb.org/anthology/D18-1157.pdf
这篇文章主题思想还是远程监督的思想,考虑到知识库中除了实体关系之外,还有很多其他的信息可以加以利用,因此在模型中考虑了这部分特征信息,比如关系的别名信息以及实体的类别信息。另外,之前看到的很多文章都是采用了CNN的网络结构,但是本文不同,摒弃了之前的CNN网络结构,而是采用Bi-GRU以及GCN的文本编码方式,考虑到采用GCN的编码方式还是考量了Bi-GRU对文本的长距离信息依赖。文章的模型结构如下。
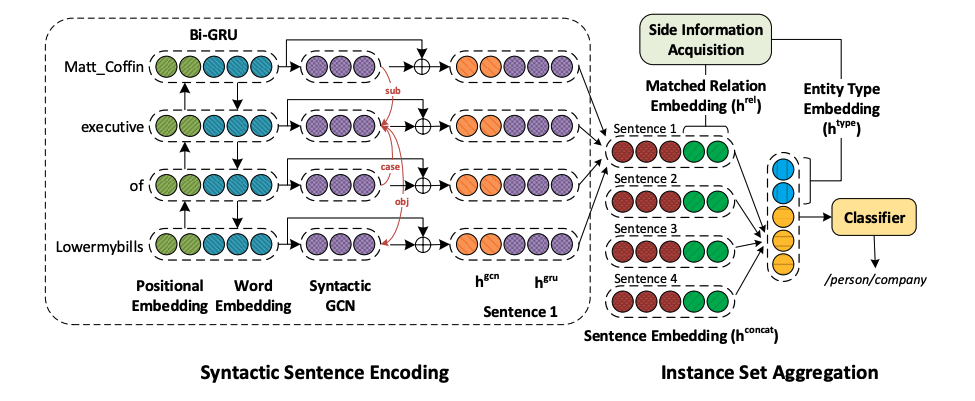
总结
以上是几篇远程监督关系抽取的论文,从09年的开山之作,到前两年的一些工作,文中的工作虽然没有覆盖全部,但是基本的方法已有大概的脉络梳理,总体来说,输入表示部分基本都是词向量与位置编码结合,获取句子语义部分采用CNN,Piecewise max-pool池化较多,当然也有采用GRU/GCN等,另外大多数工作基本都是多实例学习 + 注意力机制的改进与创新,其他的一些涉及到重叠关系、长尾分布等相关处理。除了前几年的一些工作之外,最近也有远程监督关系抽取的一些工作。
参考资料
Distant supervision for relation extraction without labeled data Knowledge-Based Weak Supervision for Information Extraction of Overlapping Relations Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks Neural Relation Extraction with Selective Attention over Instances Relation Extraction with Multi-instance Multi-label Convolutional Neural Networks Distant Supervision for Relation Extraction with Sentence-Level Attention and Entity Descriptions Hierarchical Relation Extraction with Coarse-to-Fine Grained Attention RESIDE: Improving Distantly-Supervised Neural Relation Extraction using Side Information