
用不需要手工标注分割的训练数据来进行图像分割
点击下面卡片关注,”AI算法与图像处理”
最新CV成果,火速送达
作者:Siddhartha Chandra
编译:ronghuaiyang 来源:AI公园
导读
只需要标注包围框就可以进行图像分割的训练。

手工分割(左)特征的图像,新的弱监督系统产生的分割
语义分割是将数字图像中的每一个像素自动标注为多个类别(人、猫、飞机、表等)中的一个,应用于基于内容的图像检索、医学图像和目标识别等。
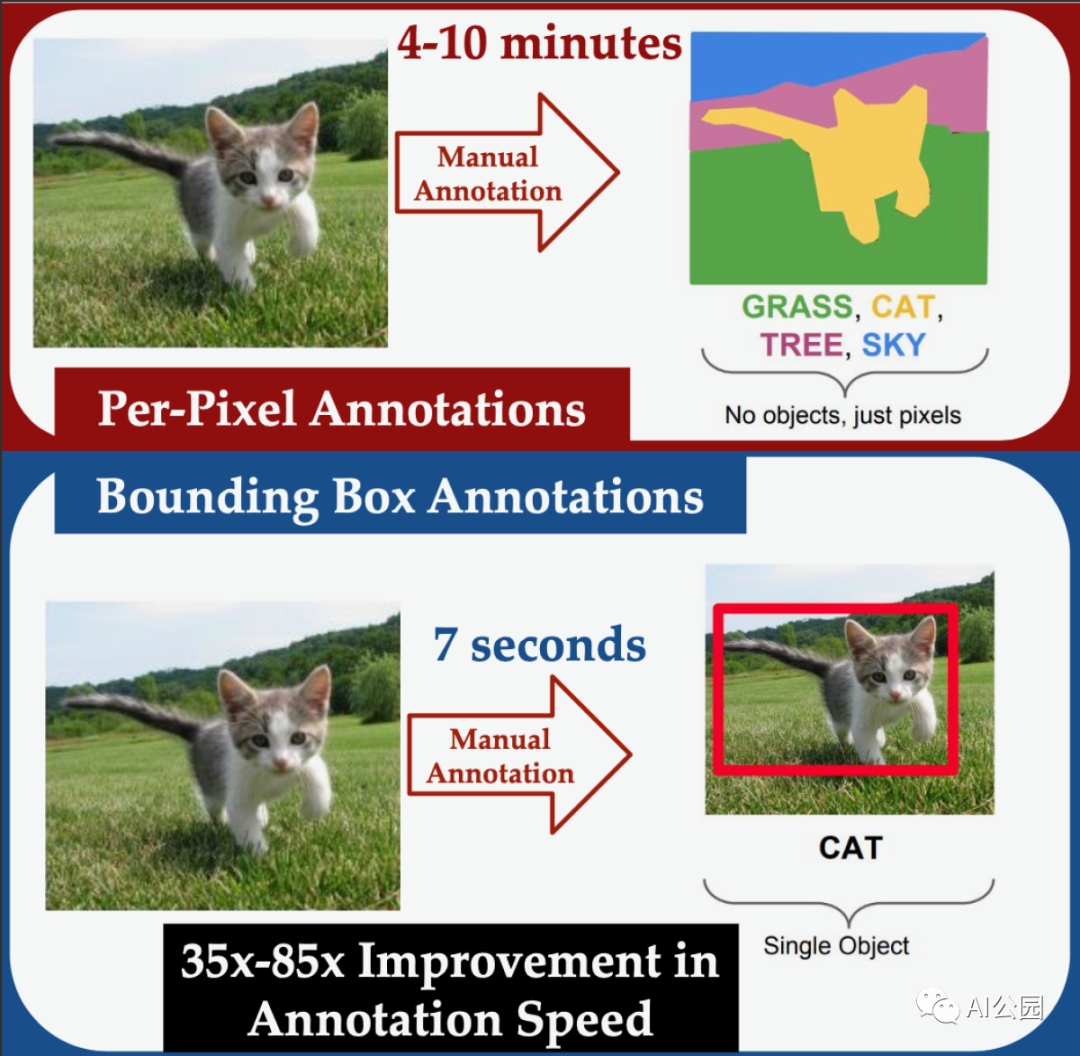
对于标注者来说,在对象周围画一个边界框要比完全分割同一幅图像容易得多。
基于机器学习的语义分割系统通常是在目标边界已经精心手工标注过的图像上训练,这是一个耗时的操作。另一方面,目标检测系统可以对图像进行训练,在这些图像中,目标被称为边界框的矩形框框起来。对于人类标注者来说,手动分割一幅图像平均花费的时间是标记边界框的35倍。
在ECCV上发表的一篇论文中,我们描述了一个新的系统,我们称之为Box2Seg,它只使用边界框训练数据来学习分割图像,这是弱监督学习的一个例子。
在实验中,我们的系统在一个(mIoU)的度量上比以前的弱监督系统提高了2%,该度量度量了系统分割图像和手动分割图像之间的一致性。我们的系统的性能也可以与对一般图像数据进行预训练,然后对完全分割的数据进行训练相比。
此外,当我们使用弱监督方法训练系统,然后对完全分割的数据进行微调时,它比对一般图像数据进行预训练的系统性能提高了16%。这表明,即使分割训练数据可用,使用我们的弱监督方法进行预处理训练仍然有优势。
有噪声的标签
我们的方法是将边界框视为噪声标签。我们把框里的每个像素当作我们要寻找的边界的对象的一部分,然而,其中一些像素被错误地标记了。框外的所有像素都被正确标记为背景像素。
在训练过程中,我们系统的输入通过三个卷积神经网络:一个目标分割网络和两个辅助网络。在运行过程中,我们丢弃了辅助网络,这样它们就不会增加已部署系统的复杂性。
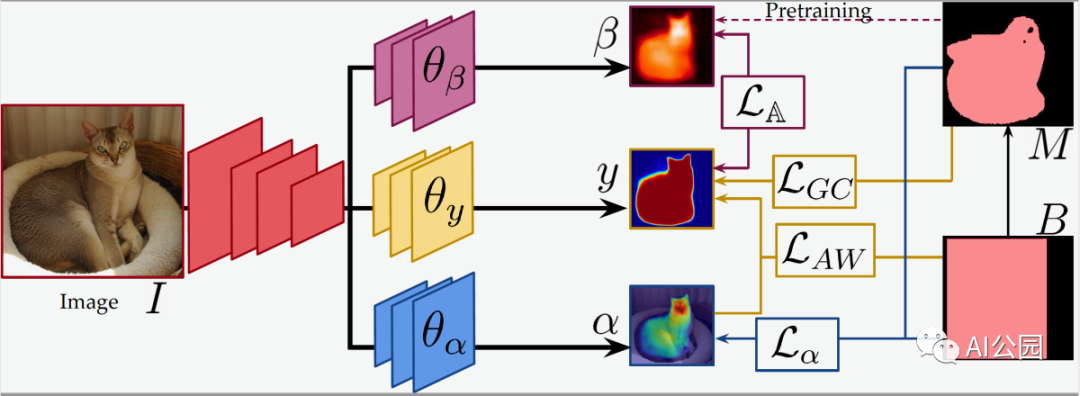
研究人员训练模型的架构。由GrabCut分割算法(M)提供的包围框本身(B)和粗分割的位置有助于监督目标分割网络(θy)和两个辅助网络(θa和θb)的训练。
其中一个辅助网络对图像中的像素进行两两比较,试图学习区分背景和前景的一般方法。直观地说,它是在边界框内寻找与框外正确标记的背景像素相似的像素,并在框内寻找彼此不同的像素簇。我们称这个网络为“嵌入”网络,因为它可以学习像素的向量表示,即嵌入,这些像素只捕捉那些对区分背景和前景有用的属性。
我们使用一种叫做GrabCut的标准分割算法提供的相对粗糙的分割来预先训练嵌入网络。在训练过程中,嵌入网络的输出为目标分割网络提供监督信号,也就是说,我们用来评价嵌入网络性能的标准之一是其输出与嵌入网络的输出是否一致。

由研究者的嵌入网络确定的“亲和性”的例子。较亮的区域表示像素,表明网络得出的结论是有一些共同之处。
另一个辅助网络是特定标签注意力网络。它学会识别具有相同标签的边框内像素之间频繁出现的视觉属性。可以将其视为一个目标检测器,其输出不是一个目标标签,而是一个突出显示特定对象类的像素簇特征的图像映射。

从左到右:手动分割图像,边界框与GrabCut算法提供的粗分割相结合,边界框与研究人员的标签特定注意网络输出相结合。在第三对图像中,光谱的红色端表示经常出现在带有特定标签的边界框内的图像特征。在训练过程中,目标分割网络应特别注意这些特征。
在使用标准基准数据集的实验中,我们发现,仅使用边界框训练数据,Box2Seg比使用完全分割训练数据训练的其他12个系统表现得更好。当使用Box2Seg训练的网络在完全分段的数据上进行微调时,性能改进甚至更显著。这表明,当没有完全分割的训练数据时,甚至在完全分割的训练数据可用时,对象分割的弱监督训练可能是有用的。

—END—
英文原文:https://www.amazon.science/blog/learning-to-segment-images-without-manually-segmented-training-data
个人微信(如果没有备注不拉群!)
请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021
在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮
,告诉大家你也在看
