
深入解读:英伟达最强异构平台


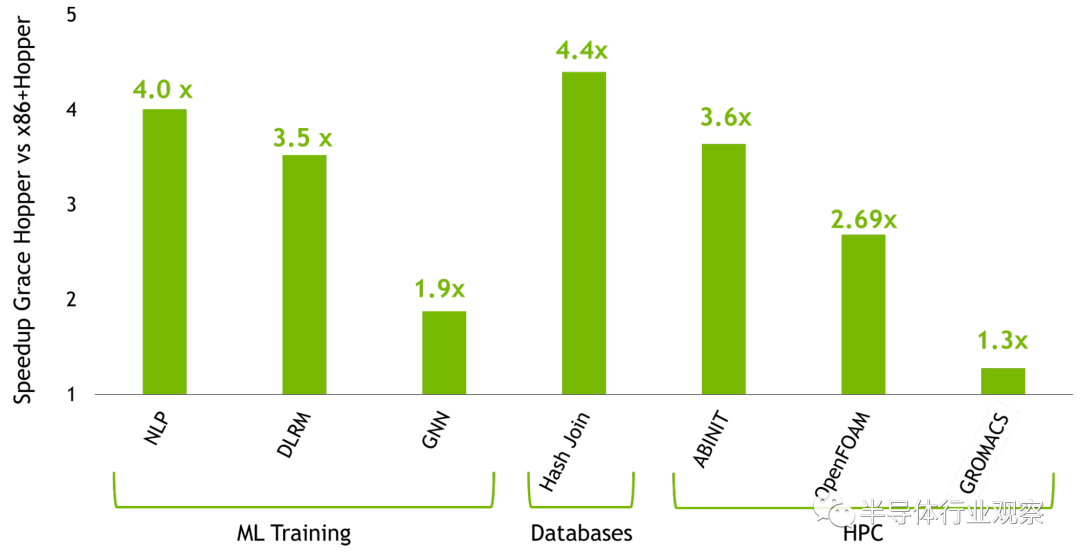
强大的可扩展 HPC 和大型 AI 工作负载的性能和生产力
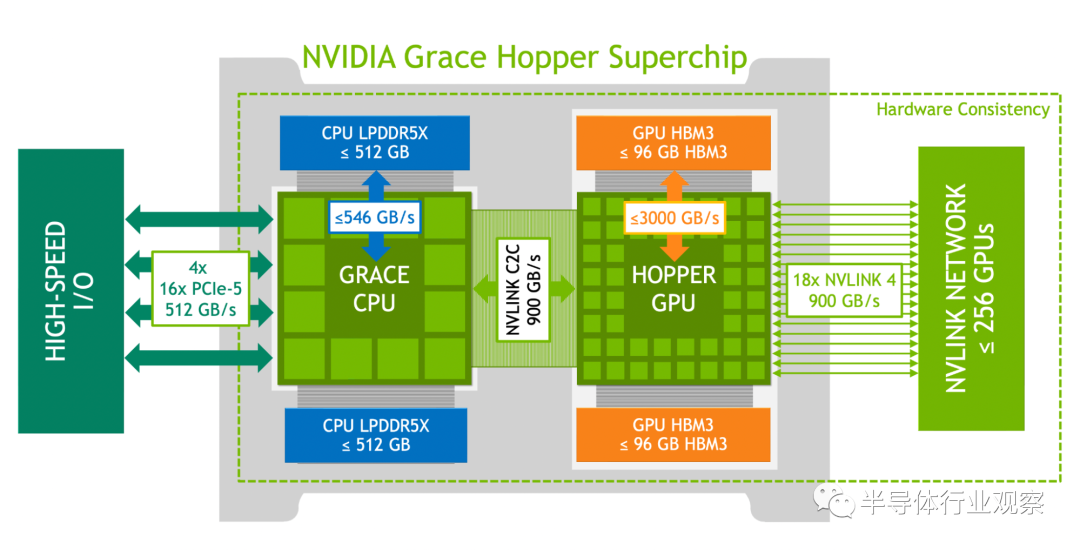
英伟达 Grace CPU: 多达 72 个 Arm Neoverse V2 内核,每个内核具有 Armv9.0-A ISA 和 4 个 128 位 SIMD 单元。 高达 117 MB 的 L3 缓存。 高达 512 GB 的 LPDDR5X 内存,提供高达 546 GB/s 的内存带宽。 多达 64 个 PCIe Gen5 通道。 NVIDIA 可扩展一致性结构 (SCF) 网格和分布式缓存,内存带宽高达 3.2 TB/s。 单个 CPU NUMA 节点可提高开发人员的工作效率。
与 NVIDIA A100 GPU 相比,多达 144 个带有第四代张量核心、Transformer Engine、DPX 和 3 倍高 FP32 和 FP64 的 SM。 高达 96 GB 的 HBM3 内存提供高达 3000 GB/s 的速度。 60 MB 二级缓存。 NVLink 4 和 PCIe 5。
Grace CPU 和 Hopper GPU 之间的硬件一致性互连。 高达 900 GB/s 的总带宽,450 GB/s/dir。 扩展 GPU 内存功能使 Hopper GPU 能够将所有 CPU 内存寻址为 GPU 内存。每个 Hopper GPU 可以在超级芯片内寻址多达 608 GB 的内存。
使用 NVLink 4 连接多达 256 个 NVIDIA Grace Hopper 超级芯片。 每个连接 NVLink 的 Hopper GPU 都可以寻址网络中所有超级芯片的所有 HBM3 和 LPDDR5X 内存,最高可达 150 TB 的 GPU 可寻址内存。
性能、可移植性和生产力的编程模型

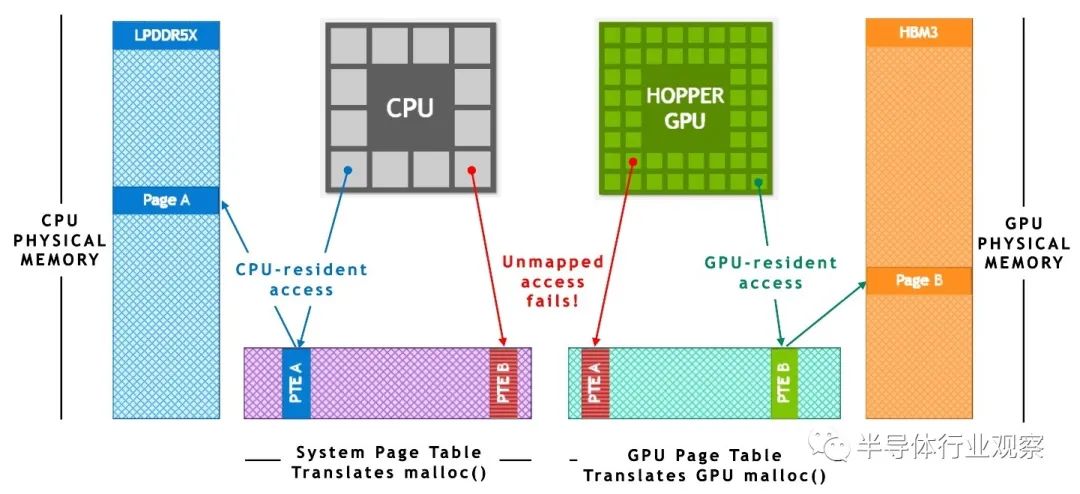
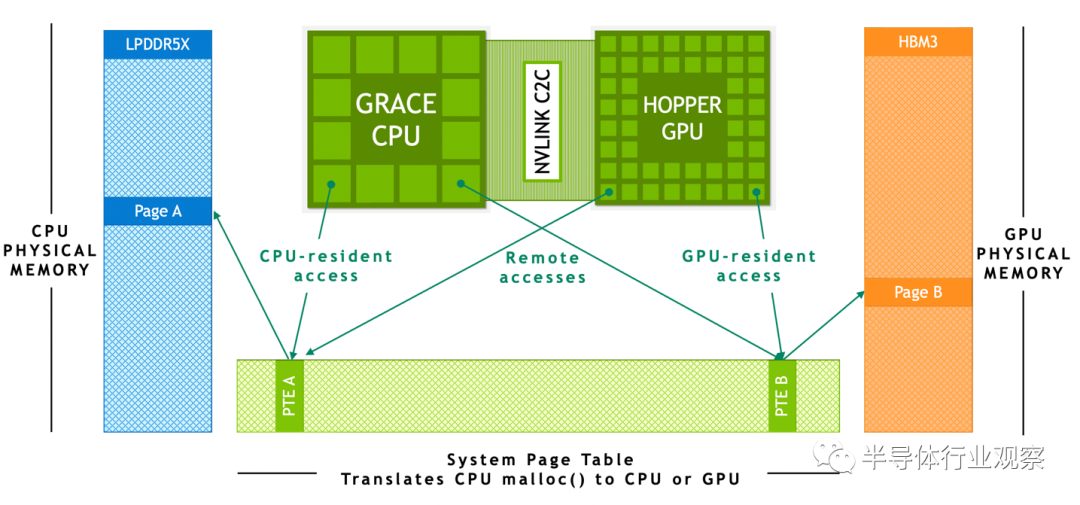
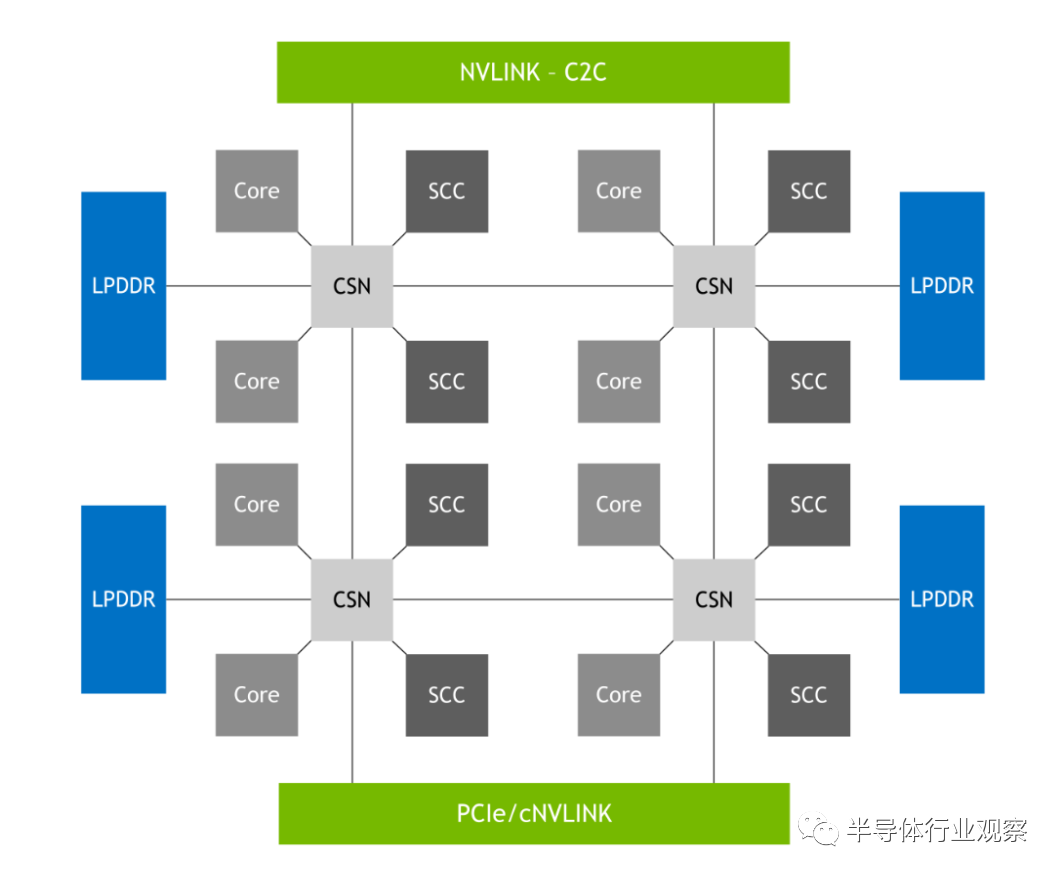
Superchip 架构特点
NVIDIA Grace CPU NVIDIA Hopper GPU NVLink-C2C NVLink Switch System Extended GPU memory NVIDIA Grace CPU

NVIDIA Hopper GPU
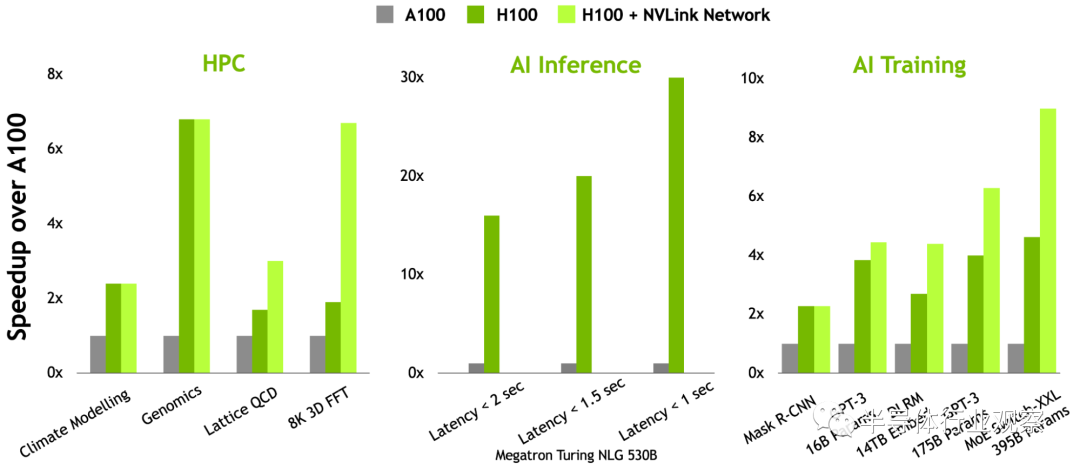
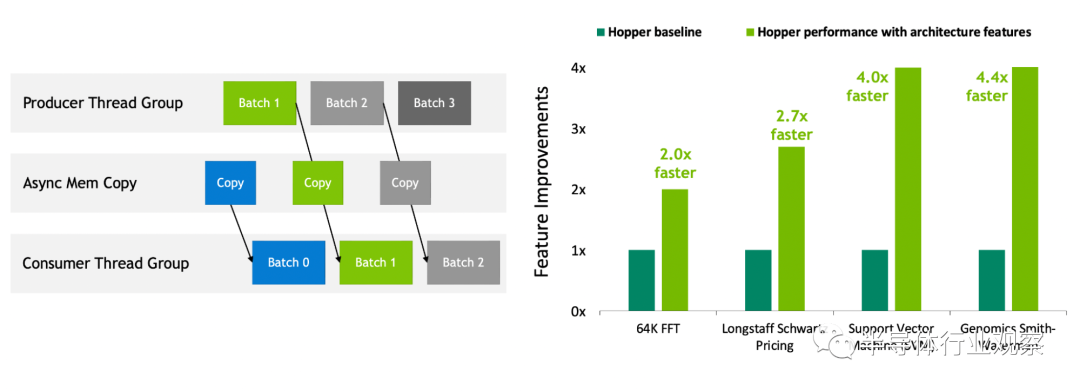
新的第四代张量核心在更广泛的 AI 和 HPC 任务中执行比以往更快的矩阵计算。 与上一代 NVIDIA A100 GPU 相比,新的 Transformer 引擎使 H100 在大型语言模型上的 AI 训练速度提高了 9 倍,AI 推理速度提高了 30 倍。 空间和时间数据局部性和异步执行的改进功能使应用程序能够始终保持所有单元忙碌并最大限度地提高能效。 安全多实例 GPU (MIG )将 GPU 划分为隔离的、大小合适的实例,以最大限度地提高较小工作负载的服务质量 (QoS)。
NVLink-C2C:用于超级芯片的高带宽、芯片到芯片互连
NVLink 开关系统

扩展 GPU 显存

本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
电子书<服务器基础知识全解(终极版)>更新完毕。
获取方式:点击“阅读原文”即可查看182页 PPT可编辑版本和PDF阅读版本详情。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。

评论