
深入解读 Elasticsearch 热点线程 hot_threads
1、实战问题来源
问题1:大佬们 GET /_nodes/hot_threads 查看热线程的这个API有没有讲解请求结果的文章呢?返回一堆堆栈看不懂......
问题2:ES集群就一台机器 CPU 爆高,但IO、heap_mem都正常。咋搞?hot_thread 我查了,报了一坨,SOS
死磕 Elasticsearch 知识星球微信群
于是就有了这篇文章。
2、hot_threads 干什么的?能吃吗?
实战业务场景中,当我们遇到集群响应比平常慢且 CPU 使用率高时,我们需要做问题排查,找到根因集群才能恢复“如丝般流畅"。
Elasticsearch提供了监视热线程的能力,
以便能够了解问题所在。
在 Java 中,热点线程(hot threads)是占用大量 CPU 且执行时间很长的线程。
排查如上问题最常用的 API 就是:hot_threads API。
GET /_nodes/hot_threads
GET /_nodes//hot_threads
Hot Threads API 从CPU 端返回有关 ElasticSearch 代码的哪些部分是热点或返回当前集群因某些原因而被卡在何处的信息。
3、hot_threads 支持的参数列表
ignore_idle_threads
(可选,布尔值)
如果为true,则会过滤掉已知的空闲线程(例如,在套接字选择中等待,或从空队列中获取任务)。
默认为true。
interval
(可选,时间单位)执行热点线程的采样间隔。
默认为500毫秒。
snapshots
(可选,整数)它是要获取的堆栈跟踪(在特定时间点嵌套的方法调用序列)数量。

默认为10。
threads
(可选,整数)查看由type参数确定的信息,ElasticSearch将采用指定数量的最“热门”线程。
最“热门”的线程,往往就是我们的问题所在。

默认为3。也就是返回TOP 3 热点线程。
master_timeout
(可选,时间单位)指定等待连接到主节点的时间段。
如果在超时到期之前未收到任何响应,则请求将失败并返回错误。
默认为30秒。
timeout
(可选,时间单位)指定等待响应的时间段。
如果在超时到期之前未收到任何响应,则请求将失败并返回错误。
默认为30秒。
type
(可选,字符串)要采样的类型。
可用的选项是:
1)block ——线程阻塞状态的时间。
2)cpu ——线程占据CPU时间。
3)wait ——线程等待状态的时间。
如果您想进一步了解线程状态,请参见:
https://docs.oracle.com/javase/6/docs/api/java/lang/Thread.State.html
默认为:cpu。
4、hot_threads 实战举例
结合刚才的参数,实战一把。以下命令将告诉ElasticSearch以一秒钟的间隔检查处于 WAITING 状态的线程。
GET /_nodes/hot_threads?type=wait&interval=1s
5、hot_threads API 原理
与其他返回 JSON 结果的 API 不同,Hot Threads API返回格式化的文本,你可以在其中区分几个部分。这也是文章开头说的“返回一堆堆栈看不懂”的原因。
在看返回堆栈结果信息之前,先看一些有关Hot Threads API背后的逻辑原理知识。
ElasticSearch 接收所有正在运行的线程,并收集有关每个线程所花费的 CPU 时间,特定线程被阻塞或处于等待状态的次数,被阻塞或处于等待状态的时间等各种信息。
然后等待特定的时间间隔 interval(由时间间隔参数指定)后,ElasticSearch 再次收集相同的信息,并根据运行的时间(降序)对热点线程进行排序。
注意,上述时间是针对 type 参数指定的给定操作类型统计的。
之后,由 ElasticSearch 分析前 N 个线程(其中 N 是由线程参数 threads 指定的线程数)。
ElasticSearch 所做的是每隔几毫秒就会捕获线程堆栈跟踪的快照(快照数量由快照参数 snapshot 指定)。
最终:对堆栈跟踪进行分组以可视化展示线程状态的变化,就是我们看到的执行API 返回的结果信息。
以上的内容,把 hot_threads API 的相关参数串联起来,相信读到这里你会对 hot_threads 有大致的了解。
还是不理解返回结果怎么办?别着急,下面就解读了。
6、hot_threads API 返回结果
现在,终于到了 hot_threads APi 返回结果部分。
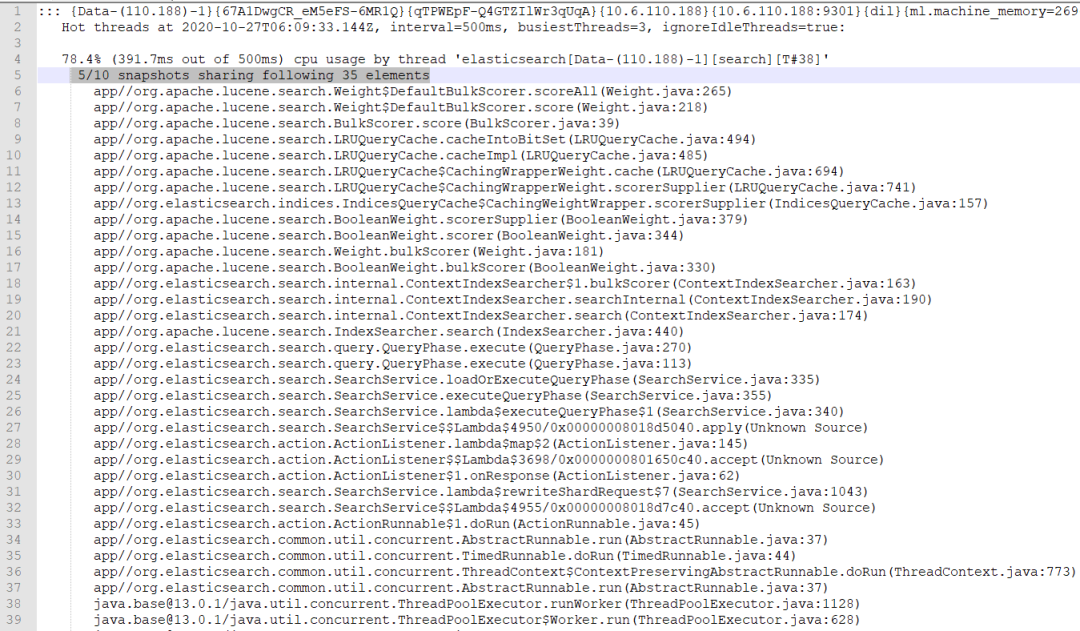
建议放大图片查看。
6.1 响应的第一部分
包含节点的基本信息。
如下所示:
{Data-(110.188)-1}{67A1DwgCR_eM5eFS-6MR1Q}{qTPWEpF-Q4GTZIlWr3qUqA}{10.6.110.188}{10.6.110.188:9301}{dil}
通过如上信息,我们可以知道 Elasticsearch 的热点线程所在节点信息,当热线程API调用涉及多个节点时,这很方便。
6.2 响应的第二部分
接下来的几行可以分为几个子部分。
6.2.1 开头部分拆解
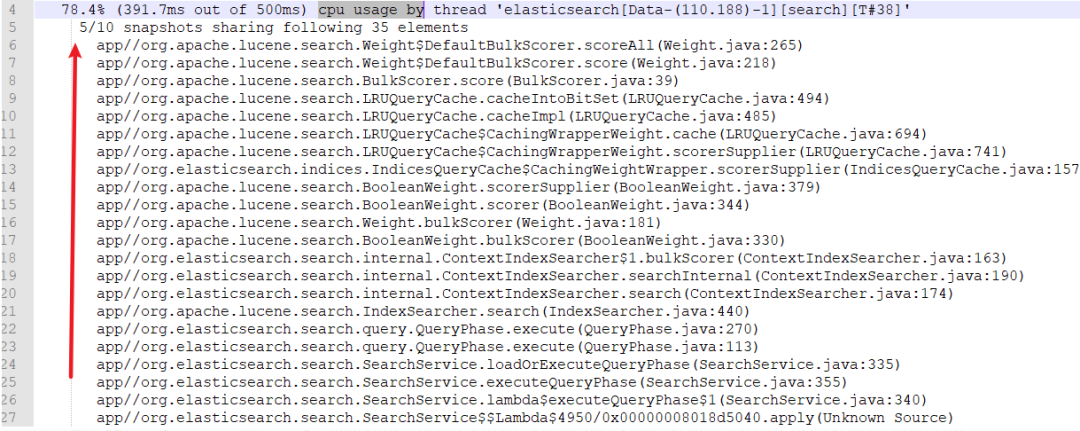
78.4% (391.7ms out of 500ms) cpu usage by thread 'elasticsearch[Data-(110.188)-1][search][T#38]'
[search] ——代表 search线程操作。 78.4% —— 代表名为 search 的线程在完成统计时占据了所有CPU时间的78.4%。 cpu usage ——指示我们正在使用 cpu 的类型,当前是线程 CPU的使用率。 block usage —— 处于阻塞状态的线程的阻塞使用率。 wait usage —— 处于等待状态的线程的等待使用率。
注意:线程名称在这里非常重要,这是因为它,我们可以猜测 ElasticSearch 的哪些功能会导致问题。
上面的示例,我们可以初步得出是 search 线程占据了大量的CPU。
实战中,除了 search 还有其他的线程,列举如下:
recovery_stream —— 用于恢复模块事件 cache —— 用于缓存事件 merge —— 用于段合并线程 index ——用于数据索引(写入)线程
等等。
6.2.2 第二子部分拆解
Hot Threads API响应的下一部分是从以下信息开始的部分:
5/10 snapshots sharing following 35 elements
如上展示了:先前的线程信息将伴随堆栈跟踪信息。
在我们的示例中,
5/10 —— 表示拍摄的 5 个快照具有相同的堆栈跟踪信息。
这在大多数情况下意味着对于当前线程,检查时间有一半都花在 ElasticSearch 代码的同一部分中。
7、小结
Elasticsearch CPU 使用率高的排查一般都会借助:hot_thread API 或者 top jstack 定位线程堆栈。
本文就 hot_thread API 应用场景、使用、返回结果进行了详细解读,希望对你有帮助。
欢迎留言说一下你对热点线程的理解或者你的实践经验。
如果,你有开头类似的问题,查官方文档也梳理不清楚,也欢迎你留言,根据留言点赞量,我们会写文章专门梳理。
和你一起,死磕 Elasticsearch!
参考:
《Mastering Elasticsearch》
《Elasticsearch 7.0 bookbook》
https://www.elastic.co/guide/en/elasticsearch/reference/current/cluster-nodes-hot-threads.html
推荐:
重磅 | 死磕 Elasticsearch 方法论认知清单(2020年国庆更新版)
更短时间更快习得更多干货!
中国 近 50%+ Elastic 认证工程师出自于此!
和全球 800+ Elastic 爱好者一起死磕 Elasticsearch!
加微信:elastic6,索要价值18元星球入场券