
深入解读 Flink SQL 1.13
一、Flink SQL 1.13 概览
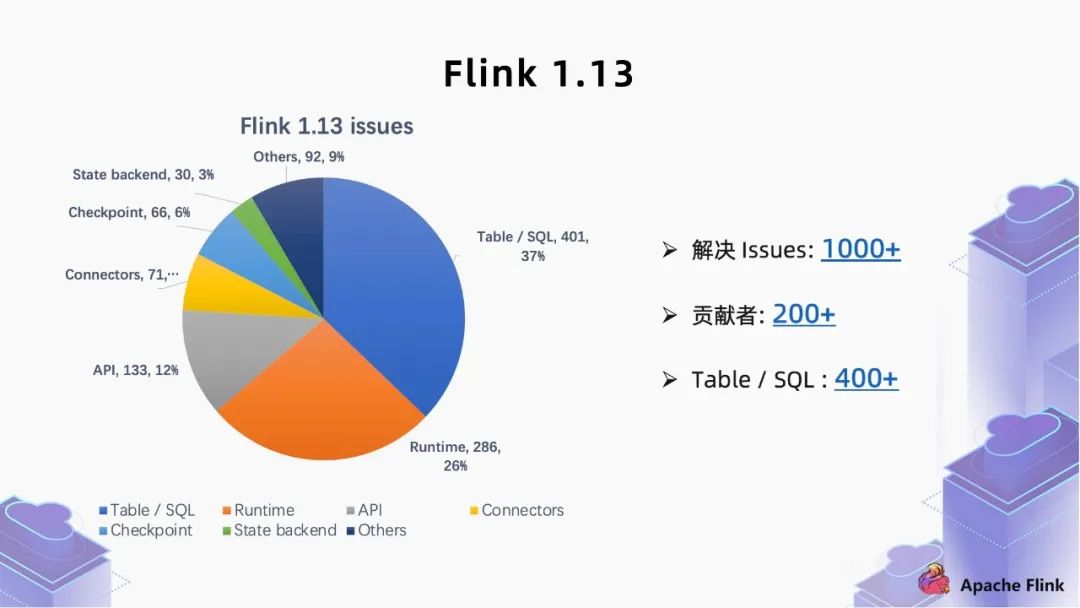
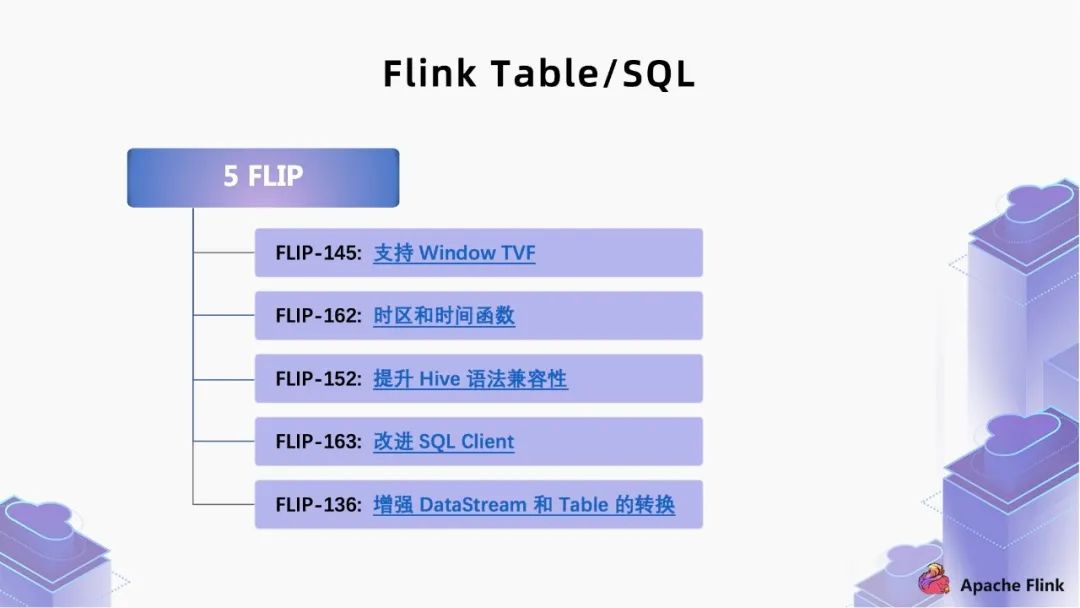
二、 核心 feature 解读
1. FLIP-145:支持 Window TVF

■ 1.1 Window TVF 语法
SELECTTUMBLE_START(bidtime,INTERVAL '10' MINUTE),TUMBLE_END(bidtime,INTERVAL '10' MINUTE),TUMBLE_ROWTIME(bidtime,INTERVAL '10' MINUTE),SUM(price)FROM MyTableGROUP BY TUMBLE(bidtime,INTERVAL '10' MINUTE)
SELECT WINDOW_start,WINDOW_end,WINDOW_time,SUM(price)FROM Table(TUMBLE(Table myTable,DESCRIPTOR(biztime),INTERVAL '10' MINUTE))GROUP BY WINDOW_start,WINDOW_end

■ 1.2 Cumulate Window
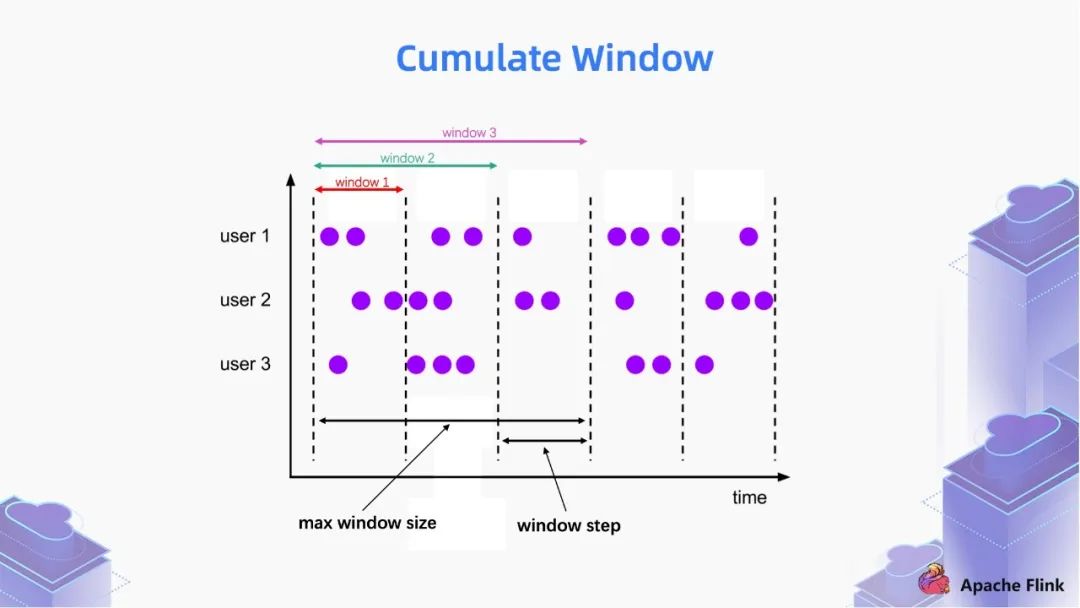
第一个 window 统计的是一个区间的数据;
第二个 window 统计的是第一区间和第二个区间的数据;
第三个 window 统计的是第一区间,第二个区间和第三个区间的数据。

INSERT INTO cumulative_UVSELECT date_str,MAX(time_str),COUNT(DISTINCT user_id) as UVFROM (SELECTDATE_FORMAT(ts,'yyyy-MM-dd') as date_str,SUBSTR(DATE_FORMAT(ts,'HH:mm'),1,4) || '0' as time_str,user_idFROM user_behavior)GROUP BY date_str
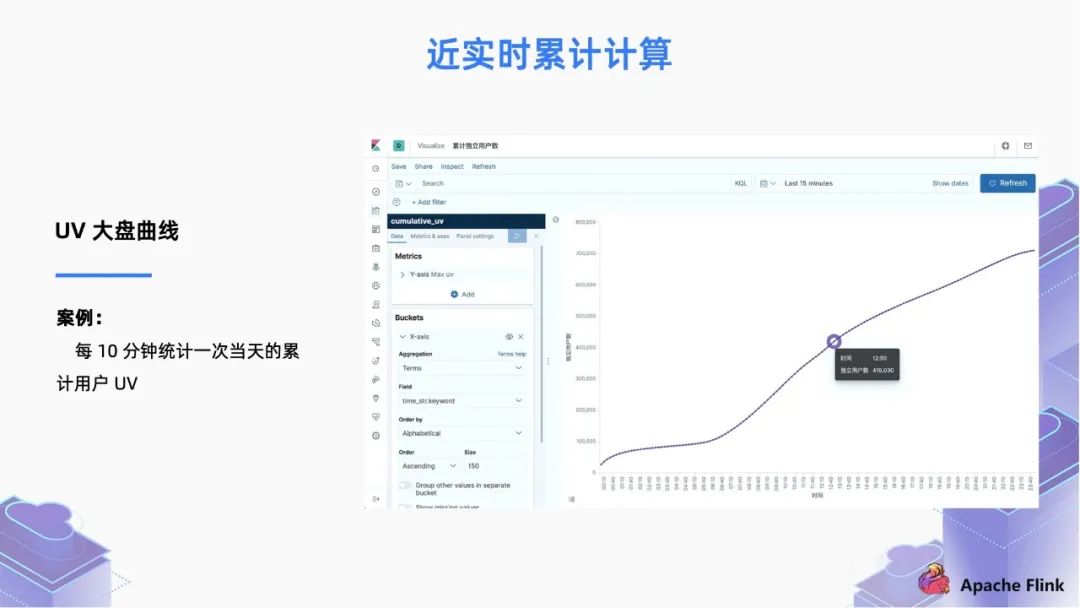
1.13 版本前的写法有很多缺点,首先这个聚合操作是每条记录都会计算一次。其次,在追逆数据的时候,消费堆积的数据时,UV 大盘的曲线就会跳变。
在 1.13 版本支持了 TVF 写法,基于 cumulate window,我们可以修改为下面的写法,将每条数据按照 Event Time 精确地分到每个 Window 里面, 每个窗口的计算通过 watermark 触发,即使在追数据场景中也不会跳变。
INSERT INTO cumulative_UVSELECT WINDOW_end,COUNT(DISTINCT user_id) as UVFROM Table(CUMULATE(Table user_behavior,DESCRIPTOR(ts),INTERVAL '10' MINUTES,INTERVAL '1' DAY)))GROUP BY WINDOW_start,WINDOW_end
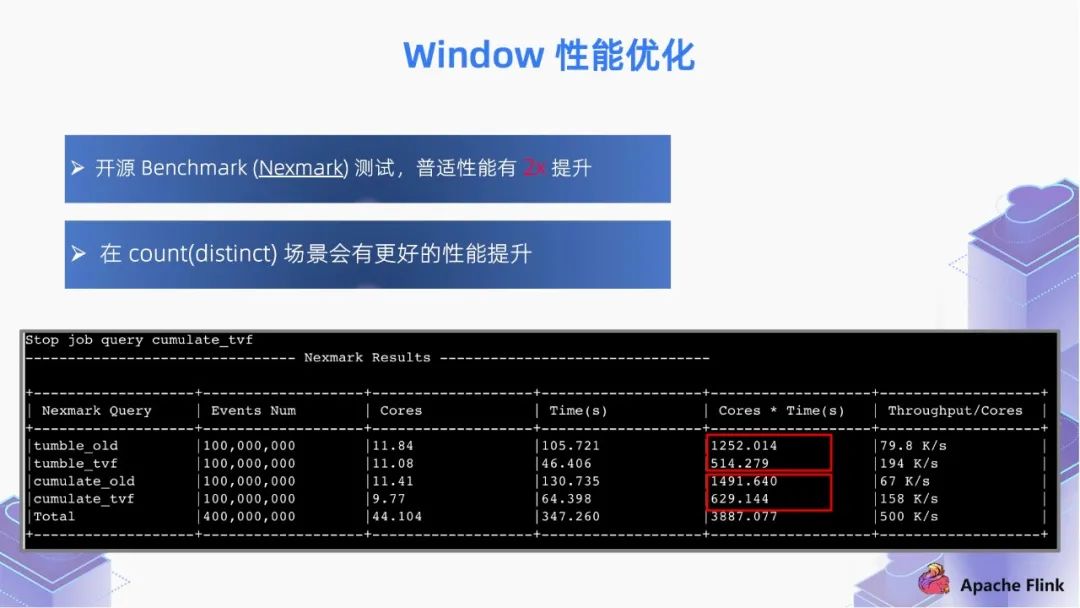
■ 1.3 Window 性能优化
内存优化:通过内存预分配,缓存 window 的数据,通过 window watermark 触发计算,通过申请一些内存 buffer 避免高频的访问 state;
切片优化:将 window 切片,尽可能复用已计算结果,如 hop window,cumulate window。计算过的分片数据无需再次计算,只需对切片的计算结果进行复用;
算子优化:window 算子支持 local-global 优化;同时支持 count(distinct) 自动解热点优化;
迟到数据:支持将迟到数据计算到后续分片,保证数据准确性。

■ 1.4 多维数据分析


2. FLIP-162:时区和时间函数
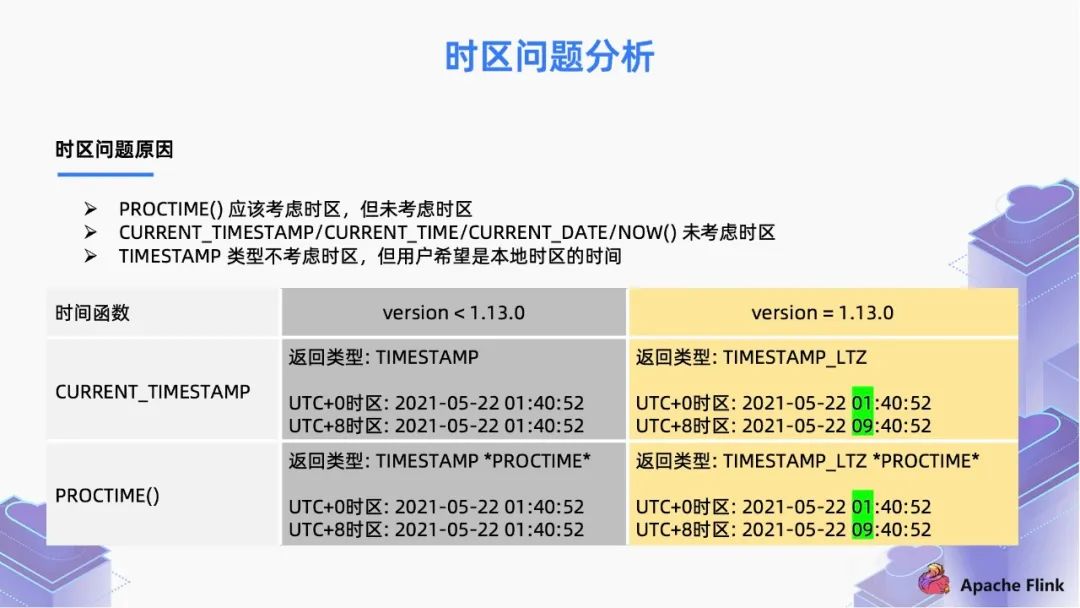
■ 2.1 时区问题分析
PROCTIME() 函数应该考虑时区,但未考虑时区;
CURRENT_TIMESTAMP/CURRENT_TIME/CURRENT_DATE/NOW() 函数未考虑时区;
Flink 的时间属性,只支持定义在 TIMESTAMP 这种数据类型上面,这个类型是无时区的,TIMESTAMP 类型不考虑时区,但用户希望是本地时区的时间。
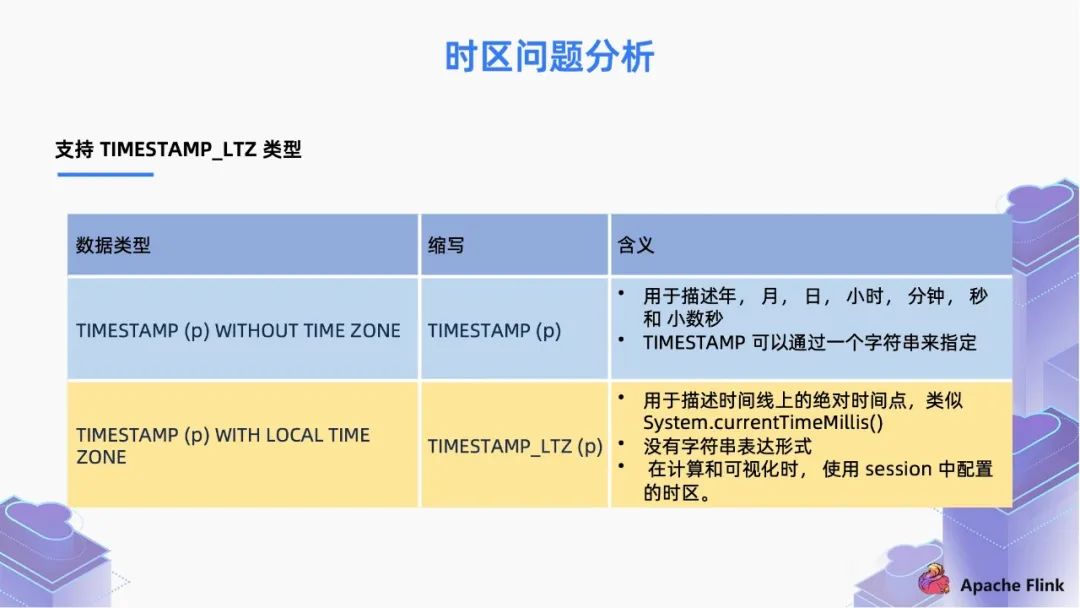
如果我们配置使用 TIMESTAMP,它可以是字符串类型的。用户不管是从英国还是中国时区来观察,这个值都是一样的;
但是对于 TIMSTAMP_TLZ 来说,它的来源就是一个 Long 值,表示从时间原点流逝过的时间。同一时刻,从时间原点流逝的时间在所有时区都是相同的,所以这个 Long 值是绝对时间的概念。当我们在不同的时区去观察这个值,我们会用本地的时区去解释成 “年-月-日-时-分-秒” 的可读格式,这就是 TIMSTAMP_TLZ 类型,TIMESTAMP_LTZ 类型也更加符合用户在不同时区下的使用习惯。

■ 2.2 时间函数纠正
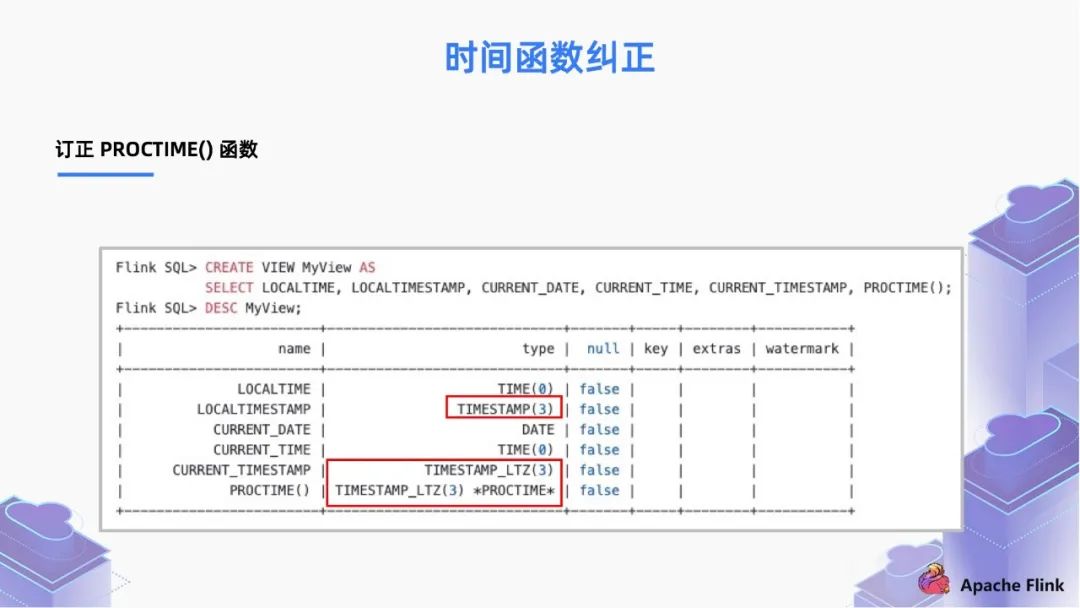
在 1.13 版本之前,它总是返回 UTC 的 TIMESTAMP;
而现在,我们把返回类型变为了 TIMESTAMP_LTZ。
PROCTIME 除了表示函数之外,也可以表示时间属性的标记。

在 1.13 版本之前,如果我们需要做按天的 window 操作,你需要手动解决时区问题,去做一些 8 小时的偏移然后再减回去;
在 FLIP-162 中我们解决了这个问题,现在用户使用的时候十分简单,只需要声明 proctime 属性,因为 PROCTIME() 函数的返回值是TIMESTAMP_LTZ,所以结果是会考虑本地的时区。下图的例子显示了在不同的时区下,proctime 属性的 window 的聚合是按照本地时区进行的。

在流模式中是 per-record 计算,即每条数据都计算一次;
在 Batch 模式是 query-start 计算,即在作业开始前计算一次。例如我们常用的一些 Batch 计算引擎,如 Hive 也是在每一个批开始前计算一次。

■ 2.3 时间类型使用
当作业的上游源数据包含了字符串的时间(如:2021-4-15 14:00:00)这样的场景,直接声明为 TIMESTAMP 然后把 Event time 定义在上面即可,窗口在计算的时候会基于时间字符串进行切分,最终会计算出符合你实际想要的预想结果;

当上游数据源的打点时间属于 long 值,表示的是一个绝对时间的含义。在 1.13 版本你可以把 Event time 定义在 TIMESTAMP_LTZ 上面。此时定义在 TIMESTAMP_LTZ 类型上的各种 WINDOW 聚合,都能够自动的解决 8 小时的时区偏移问题,无需按照之前的 SQL 写法额外做时区的修改和订正。

■ 2.4 夏令时支持

三、重要改进解读
1. FLIP-152:提升 Hive 语法兼容性



2. FLIP-163:改进 SQL Client

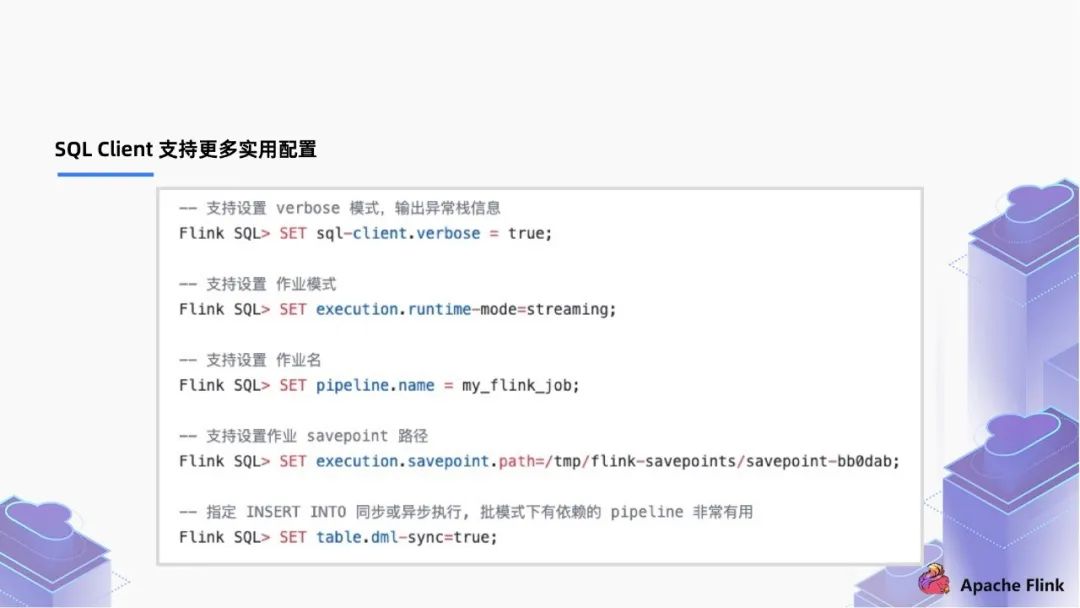
通过 SET SQL-client.verbose = true , 开启 verbose,通过开启 verbose 打印整个信息,相对以前只输出一句话更加容易追踪错误信息; 通过 SET execution.runtime-mode=streaming / batch 支持设置批/流作业模式; 通过 SET pipline.name=my_Flink_job 设置作业名称; 通过 SET execution.savepoint.path=/tmp/Flink-savepoints/savepoint-bb0dab 设置作业 savepoint 路径; 对于有依赖的多个作业,通过 SET Table.dml-sync=true 去选择是否异步执行,例如离线作业,作业 a 跑完才能跑作业 b,通过设置为 true 实现执行有依赖关系的 pipeline 调度。
4. 同时支持 STATEMENT SET语法:

在 1.13 版本之前需要启动 2 个 query 去完成这个作业; 在 1.13 版本,我们可以把这些放到一个 statement 里面,以一个作业的方式去执行,能够实现节点的复用,节约资源。
3. FLIP-136:增强 DataStream 和 Table 的转换
支持 DataStream 和 Table 转换时传递 EVENT TIME 和 WATERMARK;
Table Table = TableEnv.fromDataStream(dataStream,Schema.newBuilder().columnByMetadata("rowtime","TIMESTMP(3)").watermark("rowtime","SOURCE_WATERMARK()").build());)
支持 Changelog 数据流在 Table 和 DataStream 间相互转换。
//DATASTREAM 转 TableStreamTableEnvironment.fromChangelogStream(DataStream<ROW>): TableStreamTableEnvironment.fromChangelogStream(DataStream<ROW>,Schema): Table//Table 转 DATASTREAMStreamTableEnvironment.toChangelogStream(Table): DataStream<ROW>StreamTableEnvironment.toChangelogStream(Table,Schema): DataStream<ROW>
四、Flink SQL 1.14 未来规划
1.14 版本主要有以下几点规划:
删除 Legacy Planner:从 Flink 1.9 开始,在阿里贡献了 Blink-Planner 之后,很多一些新的 Feature 已经基于此 Blink Planner 进行开发,以前旧的 Legacy Planner 会彻底删除;
完善 Window TVF:支持 session window,支持 window TVF 的 allow -lateness 等;
提升 Schema Handling:全链路的 Schema 处理能力以及关键校验的提升;
增强 Flink CDC 支持:增强对上游 CDC 系统的集成能力,Flink SQL 内更多的算子支持 CDC 数据流。
五、总结
本文详细解读了 Flink SQL 1.13 的核心功能和重要改进。
支持 Window TVF;
系统地解决时区和时间函数问题;
提升 Hive 和 Flink 的兼容性;
改进 SQL Client;
增强 DataStream 和 Table 的转换。