
重读经典:完全解析特征学习大杀器ResNet
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文转自极市平台
导读
通过堆叠神经网络层数(增加深度)可以非常有效地增强表征,提升特征学习效果,但是会出现深层网络的性能退化问题,ResNet的出现能够解决这个问题。本文用论文解读的方式展现了ResNet的实现方式、分类、目标检测等任务上相比SOTA更好的效果。
论文标题:Deep Residual Learning for Image Recognition


1 motivation
深度学习很不好解释,大概的解释可以是:网络的不同层可以提取不同抽象层次的特征,越深的层提取的特征越抽象。因此深度网络可以整合low-medium-high各种层次的特征,增强网络表征能力。
 ,不如让网络尝试拟合一个residual mapping
,不如让网络尝试拟合一个residual mapping  。
。 ,被转换为了
,被转换为了  是比优化原映射 要容易的。
是比优化原映射 要容易的。比如如果现在恒等映射(identity mapping)是最优的,那么似乎通过堆叠一些非线性层的网络将残差映射为0,从而拟合这个恒等映射,最种做法是更容易的。
 可以通过如上图所示的短路连接(shortcut connection)结构来实现。
可以通过如上图所示的短路连接(shortcut connection)结构来实现。deep residual nets比它对应版本的plain nets更好优化,training error更低。
deep residual nets能够从更深的网络中获得更好的表征,从而提升分类效果。
2 solution
2.1 Residual Learning
表示目标拟合函数。 ,不如考虑拟合其对应的残差函数  .这两种拟合难度可能是不同的。
.这两种拟合难度可能是不同的。
2.2 Identity Mapping by Shortcuts

 表示residual mapping,比如上图,实际上就是2层网络,也就是
表示residual mapping,比如上图,实际上就是2层网络,也就是 
 与
与  element-wise相加。
element-wise相加。 套一个激活函数
套一个激活函数  .
. 是element-wise相加,那么如果 和 维度不一样怎么办? 补0.
是element-wise相加,那么如果 和 维度不一样怎么办? 补0. ),改变 的维度。即:
),改变 的维度。即: (实现起来可以就是个感知机)。不需要做维度转化时, 就是个方阵。但是后面实验表明,直接shortcut就已经足够好了,不需要再加那么多参数浪费计算资源。 的结构应该是什么样的呢? 可以是2层或者3层,也可以是更多;但是不要是1层,效果会不好。
(实现起来可以就是个感知机)。不需要做维度转化时, 就是个方阵。但是后面实验表明,直接shortcut就已经足够好了,不需要再加那么多参数浪费计算资源。 的结构应该是什么样的呢? 可以是2层或者3层,也可以是更多;但是不要是1层,效果会不好。2.3 网络架构

for the same output feature map size, the layers have the same number of filters
if the feature map size is halved, the number of filters is doubled so as to preserve the time complexity per layer
3 dataset and experiments
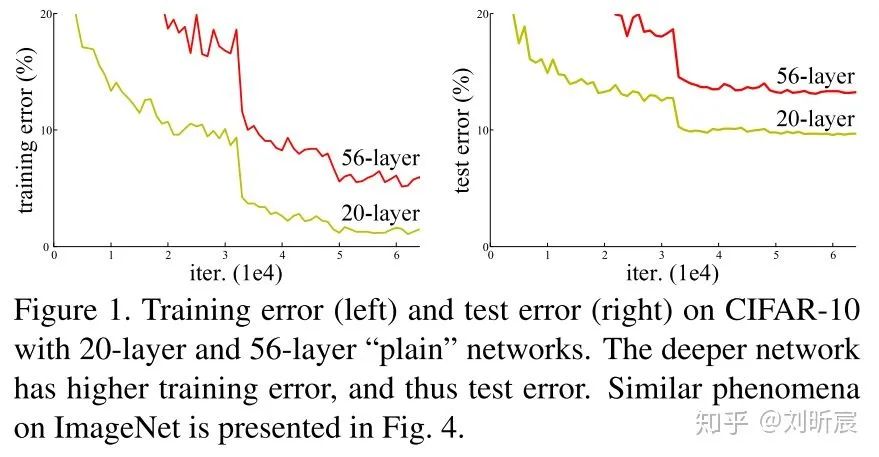
首先排除过拟合,因为train error也会升高
其次排除梯度消失,网络中使用了batch normalization,并且作者也做实验验证了梯度的存在
事实上,34-layers plain network也是可以实现比较好的准确率的,这说明网络在一定程度上也是work了的。
作者猜测:We conjecture that the deep plain nets may have exponentially low convergence rates. 层数的提升会在一定程度上指数级别影响收敛速度。
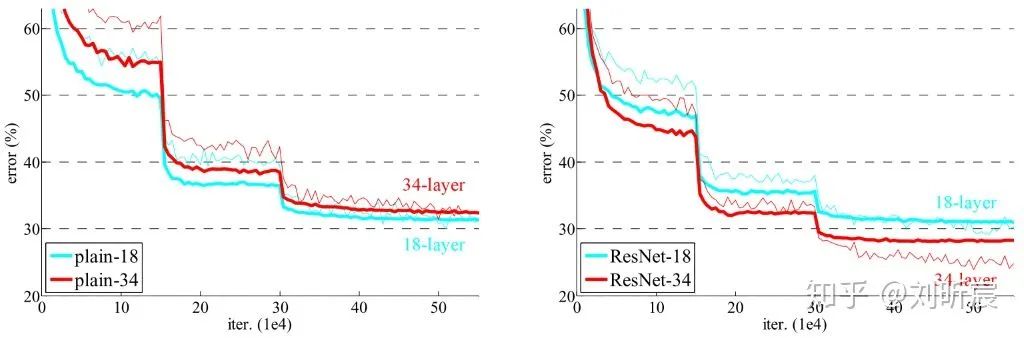
而ResNet却真正实现了网络层数增加,train error和val error都降低了,证明了网络深度确实可以帮助提升网络的性能。degradation problem在一定程度上得到了解决。
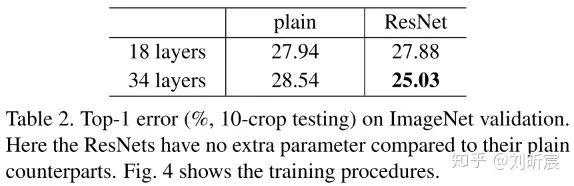
相对于plain 34-layers,ResNet 34-layers的top-1 error rate也降低了3.5%。resnet实现了在没有增加任何参数的情况下,获得了更低error rate,网络更加高效。
从plain/residual 18-layers的比较来看,两者的error rate差不多,但是ResNet却能够收敛得更快。
3.1.2 Identity v.s. Projection shortcuts

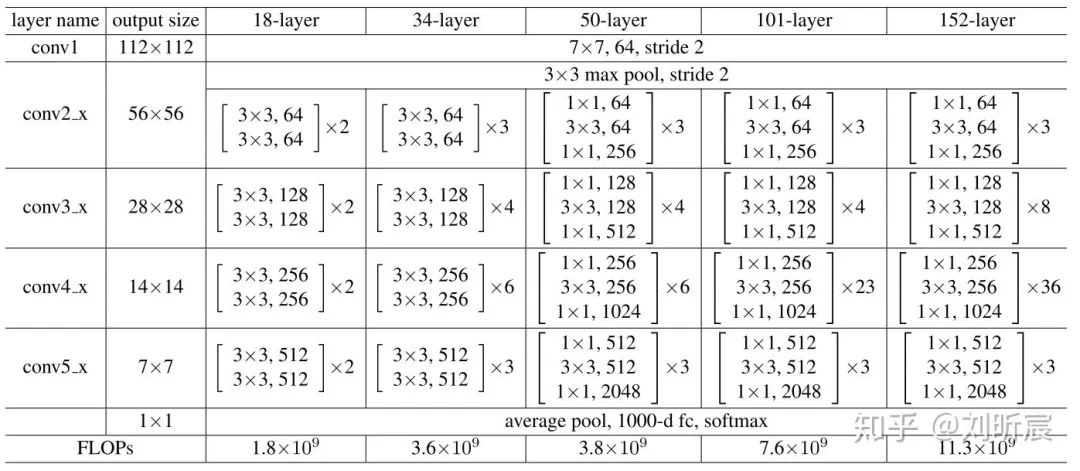
3.1.3 Deeper Bottleneck Architectures.

作者在这里是想探索深度的真正瓶颈,而不是追求很低的error rate,因此在这里使用了更加精简的bottleneck building block
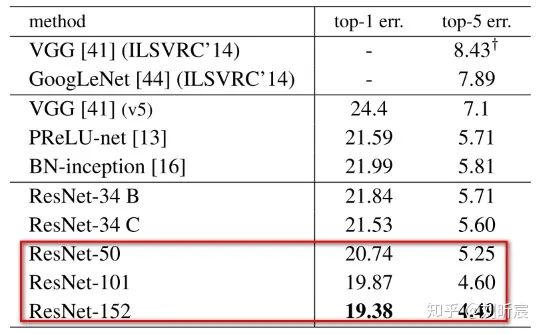
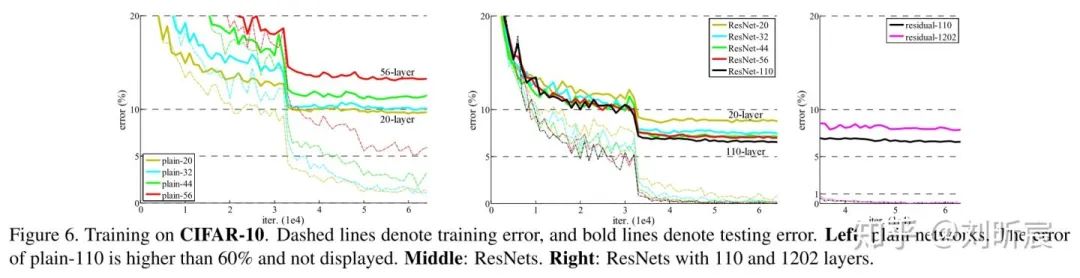
3.2 CIFAR-10实验与分析
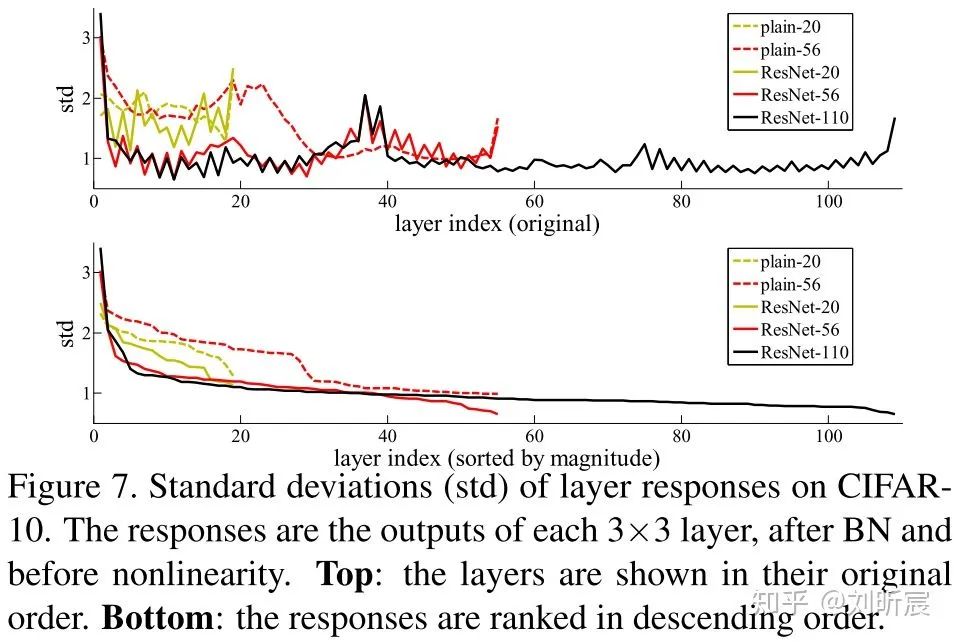
 layer, after BN and before other nonlinearity (ReLU/addition).
layer, after BN and before other nonlinearity (ReLU/addition).residual functions(即
) might be generally closer to zero than the non-residual functions.When there are more layers, an individual layer of ResNets tends to modify the signal less.(也就是后面逐渐就接近identity mapping,要拟合的残差越来越小,离目标越来越近)
4 code review
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_planes, planes, stride=1, option='A'):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != planes:
if option == 'A':
"""
For CIFAR10 ResNet paper uses option A.
"""
self.shortcut = LambdaLayer(lambda x:
F.pad(x[:, :, ::2, ::2], (0, 0, 0, 0, planes//4, planes//4), "constant", 0))
elif option == 'B':
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion * planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion * planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = F.relu(out)
return out
首:1层conv
身:由BasicBlock构成layer1、layer2、layer3,个数分别为
 ,因为每个BasicBlock有2层,所以总层数是
,因为每个BasicBlock有2层,所以总层数是 
尾:1层fc
 层!
层!class ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=10):
super(ResNet, self).__init__()
self.in_planes = 16
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(16)
self.layer1 = self._make_layer(block, 16, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 32, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 64, num_blocks[2], stride=2)
self.linear = nn.Linear(64, num_classes)
self.apply(_weights_init)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = F.avg_pool2d(out, out.size()[3])
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
def resnet20():
return ResNet(BasicBlock, [3, 3, 3])
def resnet32():
return ResNet(BasicBlock, [5, 5, 5])
def resnet44():
return ResNet(BasicBlock, [7, 7, 7])
def resnet56():
return ResNet(BasicBlock, [9, 9, 9])
def resnet110():
return ResNet(BasicBlock, [18, 18, 18])
def resnet1202():
return ResNet(BasicBlock, [200, 200, 200])
5 conclusion

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~