
【深度学习】RetinaNet 代码完全解析
本文就是大名鼎鼎的focalloss中提出的网络,其基本结构backbone+fpn+head也是目前目标检测算法的标准结构。RetinaNet凭借结构精简,清晰明了、可扩展性强、效果优秀,成为了很多算法的baseline。本文不去过多从理论分析focalloss的机制,从代码角度解析RetinaNet的实现过程,尤其是anchor生成与匹配、loss计算过程。
论文链接:
参考代码链接:
网络结构
网络结构非常清晰明了,使用的组件都是标准公认的,并且容易替换掉的。在这里,你不会看到SSD没有特征融合的多尺度,你也不会看到只有yolo才用的darknet。预测输出就是类别+位置,也是目标检测任务面临的本质。
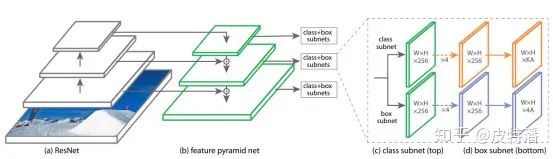
FPN
这部分无需过多介绍,就是融合不同尺度的特征,融合的方式一般是element-wise相加。当遇到尺度不一致时,利用卷积+上采样操作来处理。为了清晰理解,给出实例:
一般backbone会提取4层特征,尺度分别是,假设batch为1:
c2:1*64*W/4*H/4
c3:1*128*W/8*H/8
c4:1*256*W/16*H/16
c5:1*512*W/32*H/32:这里只需要后三层特征;假设输入数据为[1,3,320,320],FPN输出的特征维度分别为:
torch.Size([1, 256, 40, 40])
torch.Size([1, 256, 20, 20])
torch.Size([1, 256, 10, 10])
torch.Size([1, 256, 5, 5])
torch.Size([1, 256, 3, 3])当然FPN是非常容易定制的组件,当你的场景不需要太多尺度的话,可以删减输出分支。
Head
Fpn输出的分支,每一个都会进行分类和回归操作
分类输出
每层特征经过4次卷积+relu操作,然后再通过head 卷积
self.output = nn.Conv2d(feature_size, num_anchors * num_classes, kernel_size=3, padding=1)
self.output_act = nn.Sigmoid()输出最终预测输出,尺度是
torch.Size([1, 14400, 80])
torch.Size([1, 3600, 80])
torch.Size([1, 900, 80])
torch.Size([1, 225, 80])
torch.Size([1, 81, 80])其中14400 = 40*40*9,9为anchor个数,最后在把所有结果拼接在一起[1,19206,80]的tensor。可以理解为每一个特征图位置预测9个anchor,每个anchor具有80个类别。拼接操作为了和anchor的形式统一起来,方便计算loss和前向预测。注意,这里的激活函数使用的是sigmoid(),如果你想使用softmax()输出,那么就需要增加一个类别。不过论文证明了Sigmoid()效果要优于softmax().
回归输出
和分类头类似,同样是4层卷积+relu()操作,最后是输出卷积。由于是回归问题,所以没有进行激活操作。
self.output = nn.Conv2d(feature_size, num_anchors * 4, kernel_size=3, padding=1)尺度变化为:
torch.Size([1, 14400, 4])
torch.Size([1, 3600, 4])
torch.Size([1, 900, 4])
torch.Size([1, 225, 4])
torch.Size([1, 81, 4])最后在把所有结果拼接在一起[1,19206,4],4代表预测box的中心点+宽高。
Anchor生成
大的特征图预测小的物体,小的特征图预测大的物体,fpn有5个输出,所以会有5中尺度的anchor,每种尺度又分为9中宽高比。
首先定义特征图的level:
self.pyramid_levels = [3, 4, 5, 6, 7]获取对应stride为:
self.strides = [2 ** x for x in self.pyramid_levels]
# [8,16,32,64,128]获取每一层上的base size:
self.sizes = [2 ** (x + 2) for x in self.pyramid_levels]
# [32,64,128,256,512]将3种框高比和3个scale进行搭配,获取9个anchor:
ratios = np.array([0.5, 1, 2])
scales = np.array([2 ** 0, 2 ** (1.0 / 3.0), 2 ** (2.0 / 3.0)])=[1,1.26,1.587]首先计算大小:
anchors[:, 2:] = base_size * np.tile(scales, (2, len(ratios))).T获取初步的anchor的宽高 (举例,最小的输出层):
[[ 0. 0. 32. 32. ]
[ 0. 0. 40.3174736 40.3174736 ]
[ 0. 0. 50.79683366 50.79683366]
[ 0. 0. 32. 32. ]
[ 0. 0. 40.3174736 40.3174736 ]
[ 0. 0. 50.79683366 50.79683366]
[ 0. 0. 32. 32. ]
[ 0. 0. 40.3174736 40.3174736 ]
[ 0. 0. 50.79683366 50.79683366]]获取每一种尺度的面积:
[1024. 1625. 2580. 1024. 1625. 2580. 1024. 1625. 2580.]然后按照宽高比生成anchor:
[[ 0. 0. 45.254834 22.627417 ]
[ 0. 0. 57.01751796 28.50875898]
[ 0. 0. 71.83757109 35.91878555]
[ 0. 0. 32. 32. ]
[ 0. 0. 40.3174736 40.3174736 ]
[ 0. 0. 50.79683366 50.79683366]
[ 0. 0. 22.627417 45.254834 ]
[ 0. 0. 28.50875898 57.01751796]
[ 0. 0. 35.91878555 71.83757109]]最后转化为xyxy的形式:
[[-22.627417 -11.3137085 22.627417 11.3137085 ]
[-28.50875898 -14.25437949 28.50875898 14.25437949]
[-35.91878555 -17.95939277 35.91878555 17.95939277]
[-16. -16. 16. 16. ]
[-20.1587368 -20.1587368 20.1587368 20.1587368 ]
[-25.39841683 -25.39841683 25.39841683 25.39841683]
[-11.3137085 -22.627417 11.3137085 22.627417 ]
[-14.25437949 -28.50875898 14.25437949 28.50875898]
[-17.95939277 -35.91878555 17.95939277 35.91878555]]因此获取了其中一层的base anchor,这组anchor是特征图上位置(0,0)的特征图片,只需要复制+平移到其他位置,就可以获取整张特征图上所有的anchor。其他尺度的特征图做法类似最后将所有特征图上的anchor拼接起来,size同样为为[1,19206,4]
anchor编码
代码没有将anchor编码拆分成一个独立的模块,
首先gt box转化成中心点和宽高的形式:
gt_widths = assigned_annotations[:, 2] - assigned_annotations[:, 0]
gt_heights = assigned_annotations[:, 3] - assigned_annotations[:, 1]
gt_ctr_x = assigned_annotations[:, 0] + 0.5 * gt_widths
gt_ctr_y = assigned_annotations[:, 1] + 0.5 * gt_heights同理anchor也转换成中心点和宽高的形式:
anchor_widths = anchor[:, 2] - anchor[:, 0]
anchor_heights = anchor[:, 3] - anchor[:, 1]
anchor_ctr_x = anchor[:, 0] + 0.5 * anchor_widths
anchor_ctr_y = anchor[:, 1] + 0.5 * anchor_heights计算二者的相对值
targets_dx = (gt_ctr_x - anchor_ctr_x_pi) / anchor_widths_pi
targets_dy = (gt_ctr_y - anchor_ctr_y_pi) / anchor_heights_pi
targets_dw = torch.log(gt_widths / anchor_widths_pi)
targets_dh = torch.log(gt_heights / anchor_heights_pi)当然我们的目标就是网络预测值和这四个相对值相等。
anchor分配
这部分主要是根据iou的大小划分正负样本,既挑出那些负责预测gt的anchor。分配的策略非常简单,就是iou策略。
需要求iou:
IoU_max, IoU_argmax = torch.max(IoU, dim=1) # num_anchors x 1正样本:和gt的iou大于0.5的ancho样本
负样本:和gt的iou小于0.4的anchor
忽略样本:其他anchor
问题:没有像yolo系列一样,如果没有大于0.5的anchor预测,至少会分配一个iou最大的anchor。因为retinanet认为coco数据集按照此策略,匹配不到的情况非常少。
loss计算
focal loss 请参考:

当图片没有目标时,只计算分类loss,不计算box位置loss,所有anchor都是负样本:
alpha_factor = torch.ones(classification.shape) * alpha
alpha_factor = 1. - alpha_factor
focal_weight = classification
focal_weight = alpha_factor * torch.pow(focal_weight, gamma)
bce = -(torch.log(1.0 - classification))
cls_loss = focal_weight * bce
classification_losses.append(cls_loss.sum())
# 回归loss为0
regression_losses.append(torch.tensor(0).float())分类loss:
# 注意,这里是利用sigmoid输出,可以直接使用alpha和1-alpha。每一个分支都在做目标和背景的二分类
alpha_factor = torch.where(torch.eq(targets, 1.), alpha_factor, 1. - alpha_factor)
focal_weight = torch.where(torch.eq(targets, 1.), 1. - classification, classification)
focal_weight = alpha_factor * torch.pow(focal_weight, gamma)
bce = -(targets * torch.log(classification) + (1.0 - targets) * torch.log(1.0 - classification))
cls_loss = focal_weight * bce回归loss:
# 只在正样本的anchor上计算,abs就是f1 loss
regression_diff = torch.abs(targets - regression[positive_indices, :])
# 进行smooth一下,就是smooth l1 loss
regression_loss = torch.where(
torch.le(regression_diff, 1.0 / 9.0),
0.5 * 9.0 * torch.pow(regression_diff, 2),
regression_diff - 0.5 / 9.0)测试推理
因为测试推理过程一般比较简单,部分代码如下:
def forward(self, boxes, deltas):
widths = boxes[:, :, 2] - boxes[:, :, 0]
heights = boxes[:, :, 3] - boxes[:, :, 1]
ctr_x = boxes[:, :, 0] + 0.5 * widths
ctr_y = boxes[:, :, 1] + 0.5 * heights
dx = deltas[:, :, 0] * self.std[0] + self.mean[0]
dy = deltas[:, :, 1] * self.std[1] + self.mean[1]
dw = deltas[:, :, 2] * self.std[2] + self.mean[2]
dh = deltas[:, :, 3] * self.std[3] + self.mean[3]
'''其中boxes为anchor,deltas为网络回归的box分支。
注意这里的self.std[0] + self.mean[0]是对输出的标准化逆向操作,
因为网络输出时的监督有标准化操作。使用的均值和方差是固定数值。
目的是对相对数值进行放大,帮助网络回归'''
pred_ctr_x = ctr_x + dx * widths
pred_ctr_y = ctr_y + dy * heights
pred_w = torch.exp(dw) * widths
pred_h = torch.exp(dh) * heights
pred_boxes_x1 = pred_ctr_x - 0.5 * pred_w
pred_boxes_y1 = pred_ctr_y - 0.5 * pred_h
pred_boxes_x2 = pred_ctr_x + 0.5 * pred_w
pred_boxes_y2 = pred_ctr_y + 0.5 * pred_h
pred_boxes = torch.stack([pred_boxes_x1, pred_boxes_y1, pred_boxes_x2, pred_boxes_y2], dim=2)
return pred_boxes解码完成后,获得真实预测的box,还要经过clipBoxes操作,就是保证所有数不会超过图片的尺度范围。然后对每一个类别进行遍历,获取类别的score,提取大于一定阈的box,再进行nms就可以了。没啥。
结语
RetinaNet是一个结构非常清晰的目标检测框架,backbone以及neck的FPN非常容易更换掉,head的定义也非常简单。又有focal loss的加成,成为了很多算法baseline,例如任意角度的目标检测。本文从代码层面进行剖析,希望和大家一起学习。
往期精彩回顾
获取本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/qFiUFMV
本站qq群704220115。
加入微信群请扫码: