
忒修斯之船启发下的知识蒸馏新思路 | EMNLP 2020

新智元报道
新智元报道
来源:微软研究院AI头条
作者:许灿文、周王春澍、葛涛
【新智元导读】基于 Transformer 的预训练模型也在自然语言理解和自然语言生成领域中成为主流。然而,这些模型所包含的参数量巨大,计算成本高昂,极大地阻碍了此类模型在生产环境中的应用。为了解决该问题,来自微软亚洲研究院自然语言计算组的研究员们提出了一种模型压缩的新思路。
随着深度学习的流行,很多大型神经网络模型诞生,并在多个领域中取得当前最优的性能。尤其是在自然语言处理(NLP)领域中,预训练和调参已经成为其中大多数任务的新范式。
基于Transformer的预训练模型在自然语言理解(NLU)和自然语言生成(NLG)领域中成为主流。尽管这些模型从“过参数化”的特性中获益,但它们往往包含数百万甚至数十亿个参数,这就使得此类模型的计算成本高昂,且从内存消耗和高延迟的角度来看计算低效。
这一缺陷极大地阻碍了此类模型在生产环境中的应用。

为了解决该问题,研究人员提出了很多神经网络压缩技术。一般而言,这些技术可以分为三类:量化、权重剪枝和知识蒸馏(Knowledge Distillation)。其中,由于知识蒸馏能够压缩预训练语言模型,所以得到了极大关注。
知识蒸馏利用大型教师模型“教”紧凑的学生模型模仿教师的行为,从而将教师模型中嵌入的知识迁移到较小的模型中。但是,学生模型的性能状况取决于设计良好的蒸馏损失函数,正是这个函数使得学生模型可以模仿教师的行为。
近期关于知识蒸馏的研究甚至利用更复杂的模型特定蒸馏损失函数,以实现更好的性能。

近日,来自微软亚洲研究院自然语言计算组的研究员们提出了一种与显式地利用蒸馏损失函数来最小化教师模型与学生模型距离的知识蒸馏不同的模型压缩新方法。
受到著名哲学思想实验“忒修斯之船”的启发(即如果船上的木头逐渐被替换,直到所有的木头都不是原来的木头,那这艘船还是原来的那艘船吗?),研究员们在 EMNLP 2020 上发表了 Theseus Compression for BERT (BERT-of-Theseus),该方法逐步将 BERT 的原始模块替换成参数更少的替代模块。
研究员们将原始模型叫做“前辈”(predecessor),将压缩后的模型叫做“接替者”(successor),分别对应知识蒸馏中的教师和学生。
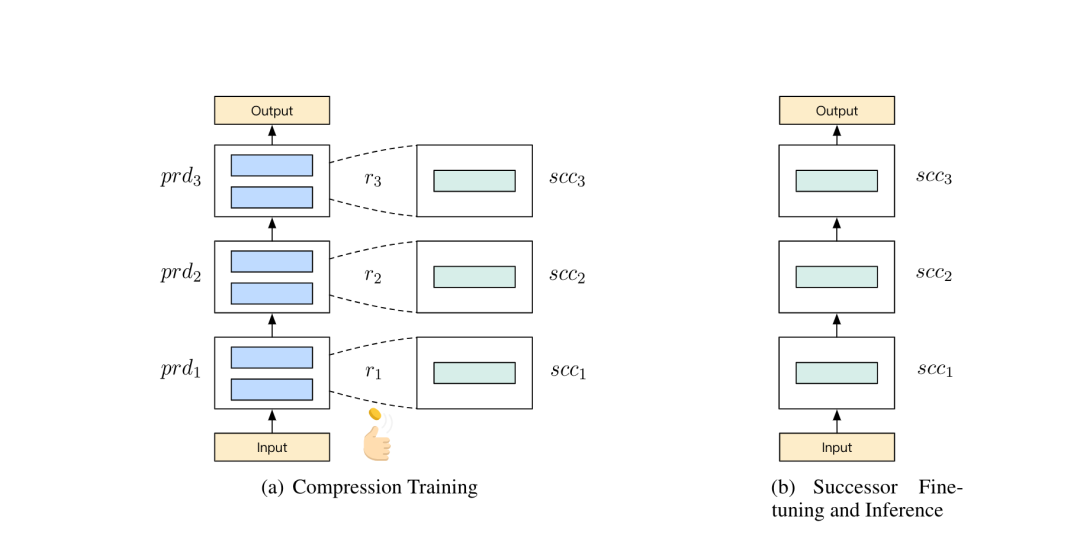
该方法的工作流程如下图所示。首先为每个前辈模块指定一个接替者模块,然后在训练阶段中以一定的概率(如抛硬币)决定是否用替代模块随机替换对应的前辈模块,并按照新旧模块组合的方式继续训练。
在模型收敛后,将所有接替者模块组合成接替者模型,进而执行推断。这样就可以将大型前辈模型压缩成紧凑的接替者模型了。
举例来说,假设现在有两支篮球队每支各五人,一支是经验老道的全明星球队,另一支则是年轻球员组成的青训队。
为了提高青训队的水平,所以随机选派青训队员去替换掉全明星队中的球员,然后让这个混合的球队不断地练习、比赛。
通过向前辈学习经验,新加入成员的实力会有所提升,也能学会和其他队员的配合,逐渐的这个混合球队就拥有了接近全明星球队的实力。之后重复这个过程,直到青训队员都被充分训练,最终青训队员也能自己组成一支实力突出的球队。
相比之下,如果没有“老司机”来带一带,青训队无论如何训练,水平也不会达到全明星队的实力。
事实上,Theseus压缩与知识蒸馏的思路有些类似,都是鼓励压缩模型模仿原始模型的行为,但 Theseus 压缩有很多独特的优势。
首先,Theseus压缩在压缩过程中仅使用任务特定的损失函数。而基于知识蒸馏的方法除了使用任务特定的损失函数外,还需加入繁琐的蒸馏损失函数作为优化目标。
其次,与近期研究 TinyBERT等不同,Theseus 压缩不使用 Transformer 特定特征进行压缩,这就为压缩广泛模型提供了可能性。与知识蒸馏仅使用原始模型执行推断不同,该方法允许前辈模型与压缩后的接替者模型共同训练,从而实现更深层次的梯度级交互,并简化训练过程。
此外,混合了前辈模块和接替者模块的不同模块组合还添加了额外的正则化项(类似于 Dropout)。该方法基于课程学习(Curriculum Learning)方法来驱动模块替换,将模块替换概率从低到高逐渐增加,从而实现优异的BERT压缩性能。
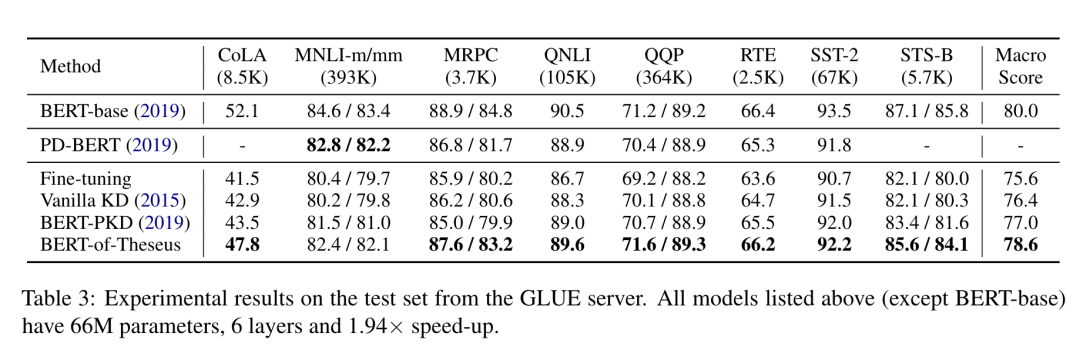
利用Theseus 压缩方法压缩得到的 BERT 模型运算速度是之前的1.94 倍,并且保留了原始模型超过 98% 的性能,优于其它基于知识蒸馏的压缩的基线方法。
通过在预训练语言模型 BERT 上的成功实验,微软亚洲研究院的研究员们希望可以为模型压缩打开一种全新的思路,并希望看到这一方法在计算机视觉等领域的更广泛应用。

