
Keras 实战系列之知识蒸馏(Knowledge Distilling)
前言
深度学习在这两年的发展可谓是突飞猛进,为了提升模型性能,模型的参数量变得越来越多,模型自身也变得越来越大。在图像领域中基于Resnet的卷积神经网络模型,不断延伸着网络深度。而在自然语言处理领域(NLP)领域,BERT,GPT等超大模型的诞生也紧随其后。这些巨型模型在准确性上大部分时候都吊打其他一众小参数量模型,可是它们在部署阶段,往往需要占用巨大内存资源,同时运行起来也极其耗时,这与工业界对模型吃资源少,低延时的要求完全背道而驰。所以很多在学术界呼风唤雨的强大模型在企业的运用过程中却没有那么顺风顺水。
知识蒸馏
为解决上述问题,我们需要将参数量巨大的模型,压缩成小参数量模型,这样就可以在不失精度的情况下,使得模型占用资源少,运行快,所以如何将这些大模型压缩,同时保持住顶尖的准确率,成了学术界一个专门的研究领域。2015年Geoffrey Hinton 发表的Distilling the Knowledge in a Neural Network的论文中提出了知识蒸馏技术,就是为了解决模型压而生的。至于文章的细节这里博主不做过多介绍,想了解的同学们可以好好研读原文。不过这篇文章的主要思想就如下方图片所示:用一个老师模型(大参数模型)去教一个学生模型(小参数模型),在实做上就是用让学生模型去学习已经在目标数据集上训练过的老师模型。尽管学生模型最终依然达不到老师模型的准确性,但是被老师教过的学生模型会比自己单独训练的学生模型更加强大。
这里大家可能会产生疑惑,为什么让学生模型去学习目标数据集会比被老师模型教出来的差。产生这种结果可能原因是因为老师模型的输出提供了比目标数据集更加丰富的信息,如下图所示,老师模型的输出,不仅提供了输入图片上的数字是数字1的信息,而且还附带着数字1和数字7和9比较像等额外信息。
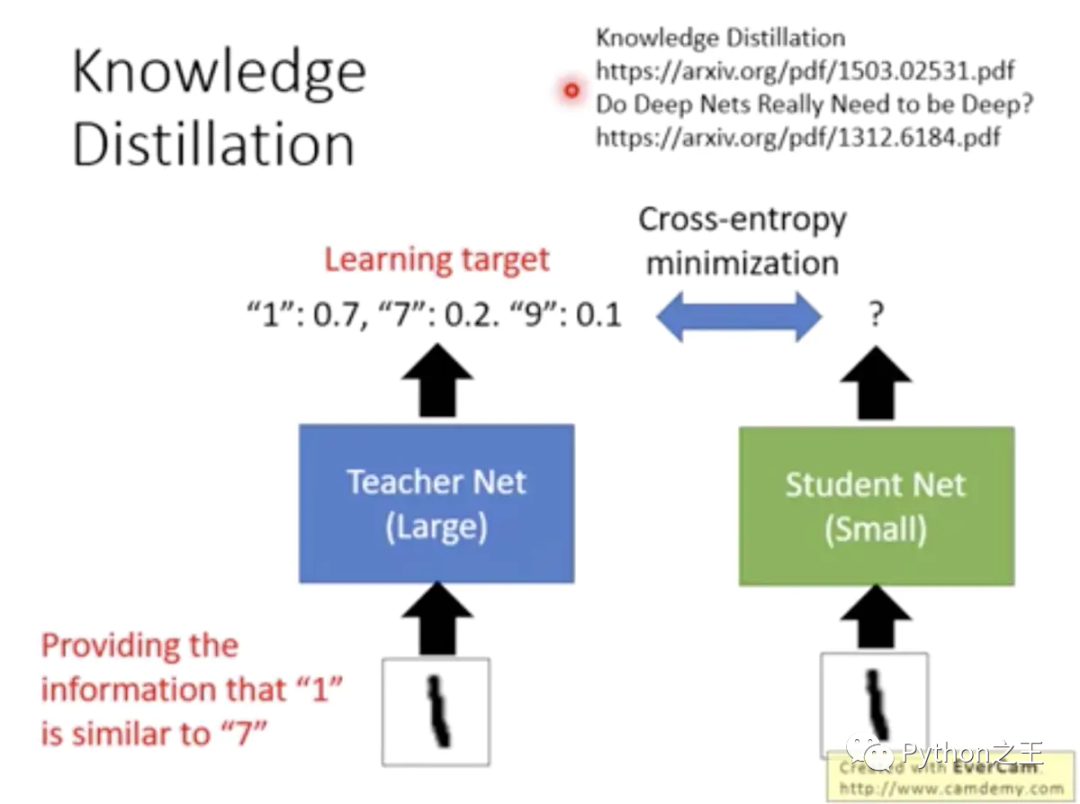
知识蒸馏
知识蒸馏具体流程
接下来博主介绍一下知识蒸馏在实做上的具体流程。
(1)定义一个参数量较大(强大的)的老师模型,和一个参数量较小(弱小的)的学生模型,
(2)让老师模型在目标数据集上训练到最佳,
(3)将目标数据的label替换成老师模型最后一个全连接层的输出,让学生模型学习老师模型的输出,希望学生模型的输出和老师模型输出之间的交叉熵越小越好。
了解到知识蒸馏的具体步骤之后,我们采用keras在mnist数据集上进行一次简单的实验。
知识蒸馏实战
包导入
导入一下必要的python 包,同时载入数据。
from keras.datasets import mnist
from keras.layers import *
from keras import Model
from sklearn.metrics import accuracy_score
import numpy as np
(data_train,label_train),(data_test,label_test )= mnist.load_data()
data_train = np.expand_dims(data_train,axis=3)
data_test = np.expand_dims(data_test,axis=3)
定义老师模型和学生模型
在下方代码中,博主定义了一个包含3层卷积层的CNN模型作为老师模型(参数量6万),定义了一个包含512个神经元的全连接层作为学生模型(参数量4万,比老师模型少了2万)。
#####定义老师模型——包含三层卷积层的CNN模型
def teacher_model():
input_ = Input(shape=(28,28,1))
x = Conv2D(32,(3,3),padding = "same")(input_)
x = Activation("relu")(x)
print(x)
x = MaxPool2D((2,2))(x)
x = Conv2D(64,(3,3),padding= "same")(x)
x = Activation("relu")(x)
x = MaxPool2D((2,2))(x)
x = Conv2D(64,(3,3),padding= "same")(x)
x = Activation("relu")(x)
x = MaxPool2D((2,2))(x)
x = Flatten()(x)
out = Dense(10,activation = "softmax")(x)
model = Model(inputs=input_,outputs=out)
model.compile(loss="sparse_categorical_crossentropy",
optimizer="adam",
metrics=["accuracy"])
model.summary()
return model
###定义学生模型——— 一层含512个神经元的全连接层
def student_model():
input_ = Input(shape=(28,28,1))
x = Flatten()(input_)
x = Dense(512,activation="sigmoid")(x)
out = Dense(10,activation = "softmax")(x)
model = Model(inputs=input_,outputs=out)
model.compile(loss="sparse_categorical_crossentropy",
optimizer="adam",
metrics=["accuracy"])
model.summary()
return model
训练老师模型
接下来开始训练老师模型,由于mnist数据集较为简单,在三层的CNN模型上,我设定只训练2个epoch。这里需要注意的是,如下图所示:三层卷积的CNN的有6万多个参数。
t_model = teacher_model()
t_model.fit(data_train,label_train,batch_size=64,epochs=2,validation_data=(data_test,label_test))
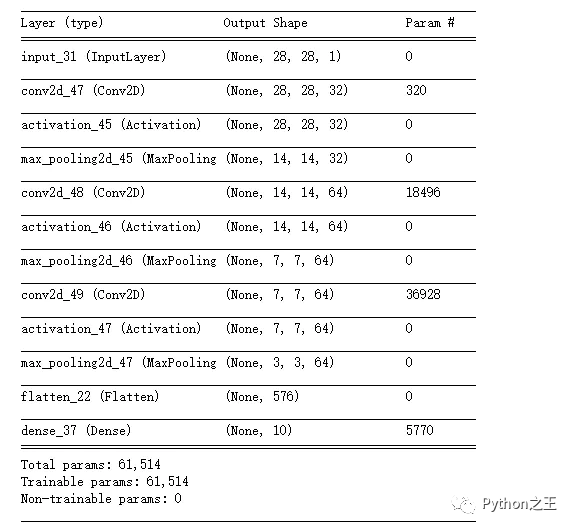
teacher model
训练结果如下图所示:两个epoch,CNN模型就在测试集上做到了98%的准确性。

teacher result
训练学生模型
在512个神经元的全连接层上训练mnist数据集,学生模型的参数量如下图所示:参数量只有4万个,参数量比老师模型少了2万个
s_model = student_model()
s_model.fit(data_train,label_train,batch_size=64,epochs=10,validation_data=(data_test,label_test))
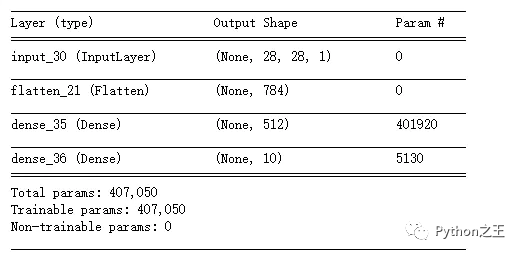
student model
在学生模型上训练了10个epoch之后,测试机准确率最高也才达到0.9460,远低于CNN老师模型的0.98

student result
老师模型教学生模型
最后我们用老师模型教学生模型,进行知识蒸馏。
首先我们采用下方代码将目标数据集的label替换成老师模型的输出。
t_out = t_model.predict(data_train)
然后用学生模型去学习老师模型的输出。
def teach_student(teacher_out, student_model,data_train,data_test,label_test):
t_out = teacher_out
s_model = student_model
for l in s_model.layers:
l.trainable = True
label_test = keras.utils.to_categorical(label_test)
model = Model(s_model.input,s_model.output)
model.compile(loss="categorical_crossentropy",
optimizer="adam")
model.fit(data_train,t_out,batch_size= 64,epochs = 5)
s_predict = np.argmax(model.predict(data_test),axis=1)
s_label = np.argmax(label_test,axis=1)
print(accuracy_score(s_predict,s_label))
最终得到的实验结果如下图所示:学生模型的性能提升到了0.9511,相比于学生模型在目标数据集上的最好成绩0.9460提升了千分之6个点。这也证明我们知识蒸馏确实起作用了。
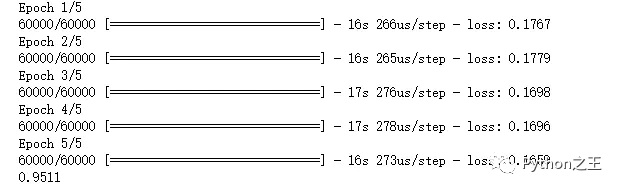
result of student model after being taught
结语
当然我们也发现,我们的实验提升的幅度并不大,离老师模型的准确度还有巨大的差距,而要想优化知识蒸馏的性能,我们可以采取升温技术,升温技术的原理图如下图所示:将老师模型的输出在softmax激活函数之前初上一个数值大于1的数字T,这样会使得老师模型输出的个类别概率值变得较为接近。

升温技术
确实升温技术的主要目的就是将老师模型输出的各类型的概率,变得较为接近,这样老师模型的输出信息将变得更加丰富,得学生模型学会分辨出个类别之间细微的区别。当然知识蒸馏的优化方法并不只上述的升温技术这一种,这里博主只是抛砖引玉,知识蒸馏还有更多的奥秘等着大家去探索,去学习。希望读者能够有所收获的同时,心中的好奇心也能够被激发,主动的学习知识蒸馏这门技术。


Python“宝藏级”公众号【Python之王】专注于Python领域,会爬虫,数分,C++,tensorflow和Pytorch等等。
近 2年共原创 100+ 篇技术文章。创作的精品文章系列有:
日常收集整理了一批不错的 Python 学习资料,有需要的小伙可以自行免费领取。
获取方式如下:公众号回复资料。领取Python等系列笔记,项目,书籍,直接套上模板就可以用了。资料包含算法、python、算法小抄、力扣刷题手册和 C++ 等学习资料!