
知识蒸馏综述:蒸馏机制
【GiantPandaCV导语】
Knowledge Distillation A Suvery的第二部分,上一篇介绍了知识蒸馏中知识的种类,这一篇介绍各个算法的蒸馏机制,根据教师网络是否和学生网络一起更新,可以分为离线蒸馏,在线蒸馏和自蒸馏。
感性上理解三种蒸馏方式:
离线蒸馏可以理解为知识渊博的老师给学生传授知识。 在线蒸馏可以理解为教师和学生一起学习。 自蒸馏意味着学生自己学习知识。
1. 离线蒸馏 Offline Distillation

上图中,红色表示pre-trained, 黄色代表To be trained。
早期的KD方法都属于离线蒸馏,将一个预训练好的教师模型的知识迁移到学生网络,所以通常包括两个阶段:
在蒸馏前,教师网络在训练集上进行训练。 教师网络通过logits层信息或者中间层信息提取知识,引导学生网络的训练。
第一个阶段通常不被认为属于知识蒸馏的一部分,因为默认教师网络本身就是已经预训练好的。一般离线蒸馏算法关注与提升知识迁移的不同部分,包括:知识的形式,损失函数的设计,分布的匹配。
Offline Distillation优点是实现起来比较简单,形式上通常是单向的知识迁移(即从教师网络到学生网络),同时需要两个阶段的训练(训练教师网络和知识蒸馏)。
Offline Distillation缺点是教师网络通常容量大,模型复杂,需要大量训练时间,还需要注意教师网络和学生网络之间的容量差异,当容量差异过大的时候,学生网络可能很难学习好这些知识。
2. 在线蒸馏 Online Distillation

上图中,教师模型和学生模型都是to be trained的状态,即教师模型并没有预训练。
在大容量教师网络没有现成模型的时候,可以考虑使用online distillation。使用在线蒸馏的时候,教师网络和学生网络的参数会同时更新,整个知识蒸馏框架是端到端训练的。
Deep Mutual Learning(dml)提出让多个网络以合作的方式进行学习,任何一个网络可以作为学生网络,其他的网络可以作为教师网络。 Online Knowledge Distillation via Collaborative Learning提出使用soft logits继承的方式来提升dml的泛化性能。 Oneline Knowledge distillation with diverse peers进一步引入了辅助peers和一个group leader来引导互学习过程。 为了降低计算代价,Knowledge Distillation by on-the-fly native ensemble通过提出一个多分支的架构,每个分支可以作为一个学生网络,不同的分支共享相同的的backbone。 Feature fusion for online mutual knowledge distillation提出了一种特征融合模块来构建教师分类器。 Training convolutional neural networks with cheap convolutions and online distillation提出使用cheap convolutioin来取代原先的conv层构建学生网络。 Large scale distributed neural network training throgh online distillation采用在线蒸馏训练大规模分布式网络模型,提出了一种在线蒸馏的变体-co-distillation。co-distillation同时训练多个相同架构的模型,每一个模型都是经由其他模型训练得到的。 Feature-map-level online adversarial knowledge distillation提出了一种在线对抗知识蒸馏方法,利用类别概率和特征图的知识,由判别器同时训练多个网络
在线蒸馏法是一种具有高效并行计算的单阶段端到端训练方案。然而,现有的在线方法(如相互学习)通常不能解决在线设置中的大容量教师,因此,进一步探索在线设置中教师和学生模型之间的关系是一个有趣的话题。
3. 自蒸馏 Self-Distillation
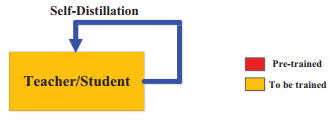
在自蒸馏中,教师和学生模型使用相同的网络。自蒸馏可以看作是在线蒸馏的一种特殊情况,因为教师网络和学生网络使用的是相同的模型。
Be your own teacher: Improve the performance of convolutional neural networks via self distillation 提出了一种新的自蒸馏方法,将网络较深部分的知识蒸馏到网络较浅部分。 Snapshot distillation:Teacher-student optimization in one generation 是自蒸馏的一种特殊变体,它将网络早期阶段(教师)的知识转移到后期阶段(学生),以支持同一网络内有监督的培训过程。 为了进一步减少推断的时间,Distillation based training for multi-exit architectures提出了基于蒸馏的训练方案,即浅层exit layer在训练过程中试图模拟深层 exit layer的输出。 最近,自蒸馏已经在Self-distillation amplifies regularization in hilbert space进行了理论分析,并在Self-Distillation as Instance-Specific Label Smoothing中通过实验证明了其改进的性能。 Revisit knowledge distillation: a teacher-free framework 提出了一种基于标签平滑化的无教师知识蒸馏方法。 Regularizing Class-wise Predictions via Self-knowledge Distillation提出了一种基于类间(class-wise)的自我知识蒸馏,以与相同的模型在同一源中,在同一源内的训练模型的输出分布相匹配。 Rethinking data augmentation: Self-supervision and self-distillation提出的自蒸馏是为数据增强所采用的,并对知识进行增强,以此提升模型本身的性能。
4. 教师学生架构
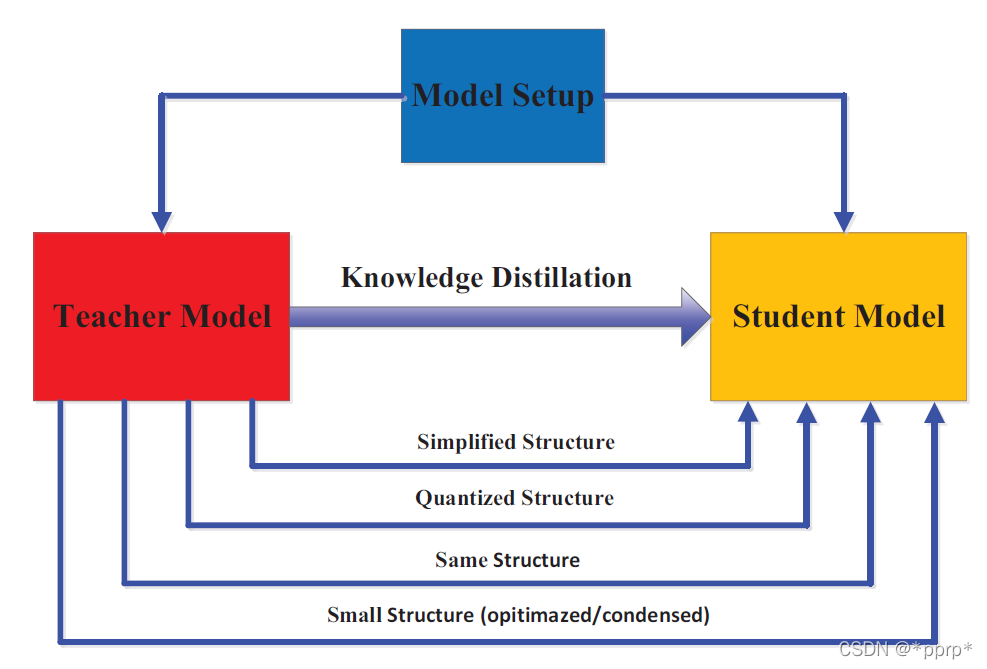
在知识提炼中,师生架构是形成知识传递的通用载体。换句话说,从教师到学生的知识获取和提炼的质量是由设计教师和学生网络的方式 决定的。
就人类的学习习惯而言,我们希望学生能找到一个合适的老师。因此,要很好地完成知识提炼中的知识捕捉和提炼,如何选择或设计合适的教师和学生的结构 是非常重要而困难的问题。
最近,在蒸馏过程中,教师和学生的模型设置几乎是预先固定的,其尺寸和结构都不尽相同,这样就容易造成模型容量差距。然而,如何对教师和学生的体系结构进行特殊的设计,以及为什么他们的体系结构是由这些模型设置决定的,这些问题几乎没有得到解答。
这部分将探讨的教师模型和学生模型的结构之间的关系,如上图所示。
在Hinton提出的KD中,知识蒸馏先前被设计用来压缩深度神经网络,深度神经网络的复杂度主要来自于网络的深度和宽度。通常需要将知识从更深更宽的神经网络转移到更浅更窄的神经网络。学生网络被选择为:
教师网络的简化版:通道数和层数减少。
教师网络的量化版:网络结构被保留下来。
具有高效基本操作的小型网络。
具有优化全局网络结构的小型网络。
与教师相同的网络。
大型深度神经网络和小型学生网络之间的模型容量差距会降低知识转移的性能 。为了有效地将知识转移到学生网络中,已经提出了多种方法来控制降低模型的复杂性。比如:
Improved knowledge distillation via teacher assistant引入教师助理,缓解教师模式和学生模式之间的训练gap。 Residual Error Based Knowledge Distillation提出使用残差学习来降低训练gap,辅助的结构主要用于学习残差错误。
还有一些工作将关注点放在:最小化学生模型和教师模型结构上差异 。
Model compression via distillation and quantization将网络量化与知识蒸馏相结合,即学生模型是教师模型的量化版本。 Deep net triage: Analyzing the importance of network layers via structural compression.提出了一种结构压缩方法,将多个层学到的知识转移到单个层。 Progressive blockwise knowledge distillation for neural network acceleration在保留感受野的同时,从教师网络向学生网络逐步进行block-wise的知识转移。
以往的研究大多集中在设计教师与学生模型的结构 或教师与学生之间的知识迁移机制 。为了使一个小的学生模型与一个大的教师模型相匹配,以提高知识提炼的绩效,需要具有适应性的师生学习架构。近年来,知识提炼中的神经结构搜索,即在教师模型的指导下,对学生结构和知识转移进行联合搜索,将是未来研究的一个有趣课题。
Search to distill: Pearls are everywhere but not the eyes Self-training with Noisy Student improves ImageNet classification Search for Better Students to Learn Distilled Knowledge
以上的几个工作都是在给定教师网络的情况下,搜索合适的学生网络结构。