
LeCun带两位UC伯克利华人博士提出「循环参数生成器」,一个参数重复用!
新智元报道
新智元报道
来源:arXiv
编辑:Priscilla 好困
【新智元导读】近日,LeCun带领两位来自UC伯克利的华人博士共同发表了一份关于如何减少参数冗余问题的论文,团队提出的RPG循环参数生成器,在减少骨干参数的同时,也依然能获得比SOTA更好的性能。

参数更少,更灵活
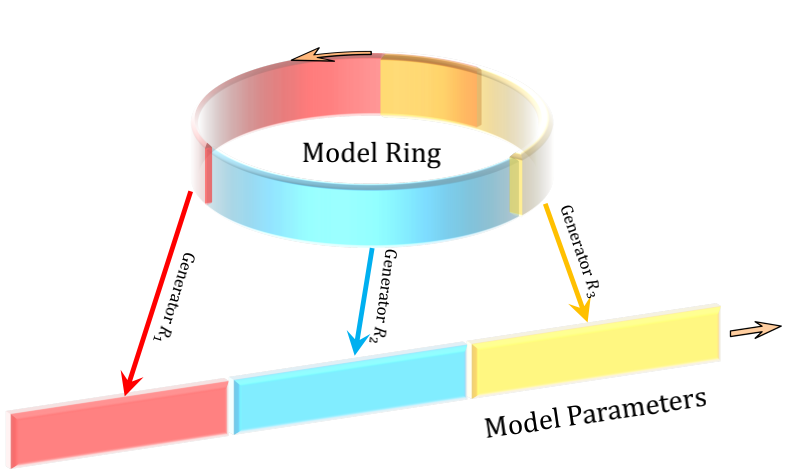
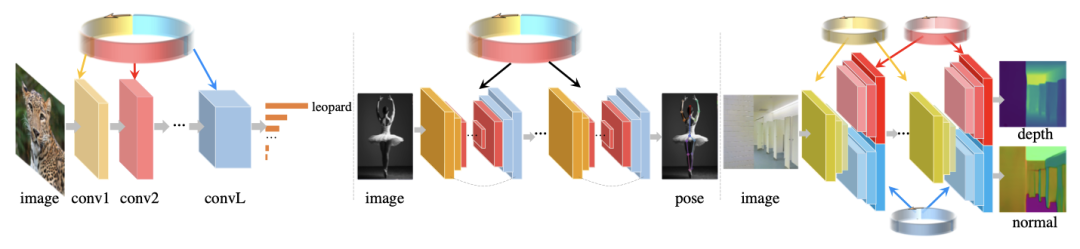
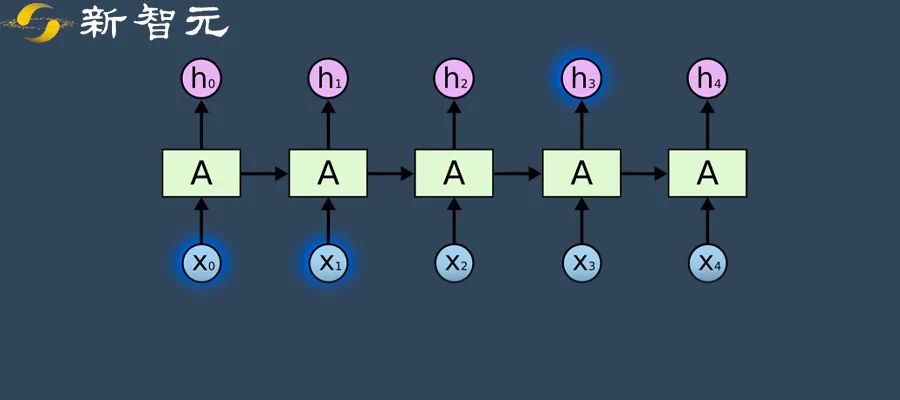
循环参数生成器
循环参数生成器
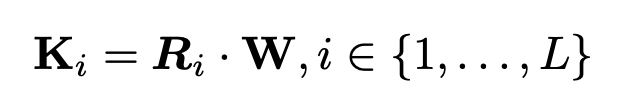
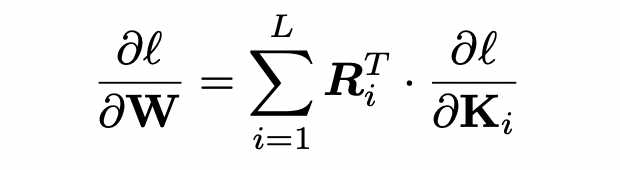
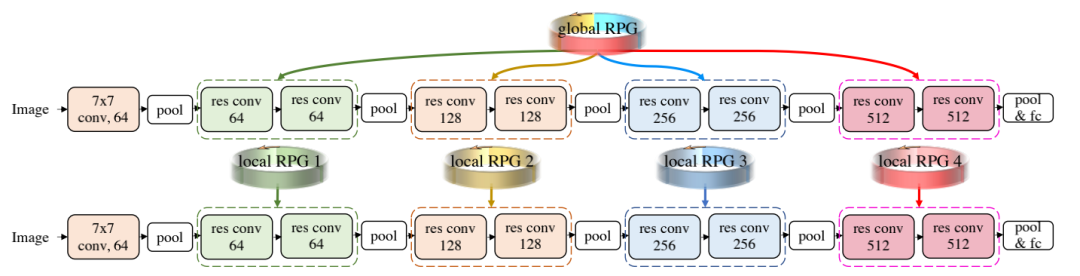
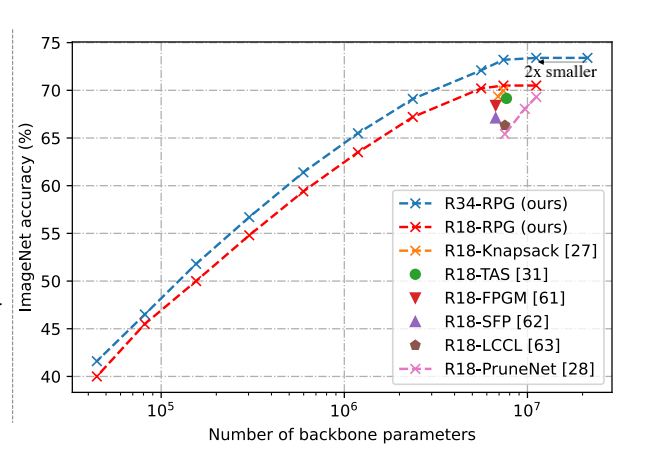
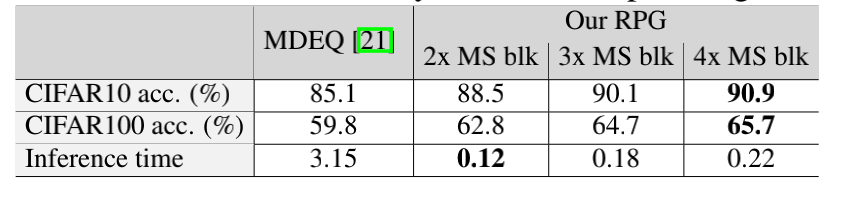
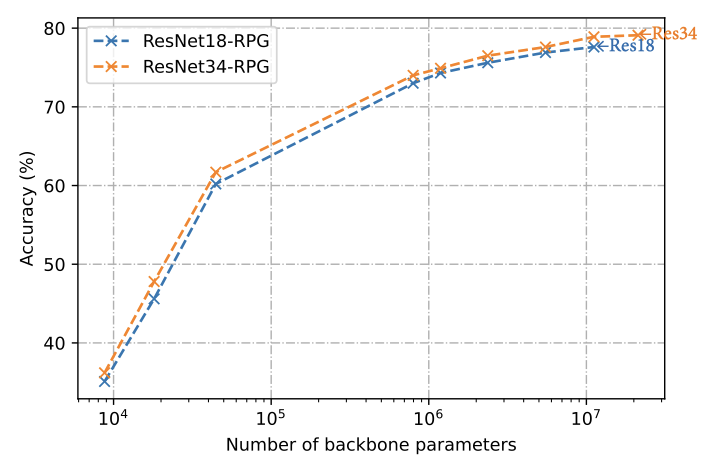
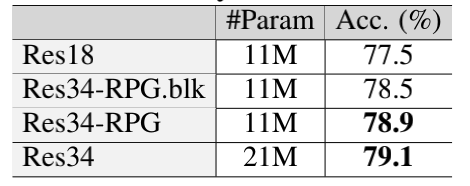
图像分类
图像分类

作者简介


参考资料:
https://arxiv.org/pdf/2107.07110.pdf

评论